Este recurso muestra cómo evaluar la convergencia y eficiencia de simulaciones MCMC con múltiples cadenas utilizando el algoritmo de Metropolis-Hastings. Se usa un modelo con verosimilitud normal y varianza conocida, donde el objetivo es obtener el posterior de la media. Se construyen traceplots, se calcula el estadístico \(\hat{R}\) de Gelman-Rubin para diagnosticar la convergencia, y se calcula el tamaño efectivo de muestra \(N_{\text{eff}}\) para evaluar la la cantidad de información contenida en las muestras.
La siguiente celda de código contiene funciones utilitarias.
Código
library(dplyr)library(ggplot2)graficar_trazas <-function(df_muestras) { plt <-ggplot(df_muestras) +geom_line(aes(x = paso, y = valor, group = cadena, color = cadena)) +scale_color_manual(values =c("#107591", "#00c0bf", "#f69a48", "#fdcd49")) +labs(x ="Paso", y ="x") +theme_bw()theme(panel.grid.minor =element_blank() )return(plt)}crear_df_muestras <-function(muestras) {# Muestras es una lista de vectores.# Hay tantos vectores como cadenas. n_cadenas <-length(muestras) n_muestras <-length(muestras[[1]]) df <-data.frame(cadena =as.factor(rep(seq_len(n_cadenas), each = n_muestras)),paso =rep(seq_len(n_muestras), n_cadenas),valor =unlist(muestras) )return(df)}metropolis_hastings <-function(n, x, p, sigma) {# Algortimo de Metropolis Hastings en una dimensión con propuesta normal.## Parámetros# ------------------------------------------------------------------------# | n | Cantidad de muestras a obtener. |# | x | Posición inicial del algoritmo. |# | p | Función de densidad objetivo, normalizada o sin normalizar. |# | sigma | Desvío estándar de la distribución de propuesta normal. |# ------------------------------------------------------------------------ muestras <-numeric(n) muestras[1] <- xfor (i inseq_len(n -1)) { x_actual <- muestras[i] x_propuesto <-rnorm(1, mean = x_actual, sd = sigma) p_actual <-p(x_actual) p_propuesto <-p(x_propuesto)if (runif(1) < (p_propuesto / p_actual)) { muestras[i +1] <- x_propuesto } else { muestras[i +1] <- x_actual } }return(muestras)}set.seed(1211)
Diagnósticos
Diagnóstico \(\hat{R}\) de Gelman-Rubin
El valor de \(\hat{R}\) se utiliza para evaluar la convergencia de las cadenas de MCMC. Un valor cercano a 1 sugiere que las cadenas se han mezclado adecuadamente y convergido a la misma distribución objetivo. En cambio, valores mayores a 1 (en la práctica, 1.01 o más) indican que las cadenas aún no han convergido y/o no se han mezclado correctamente.
El estadístico de Gelman-Rubin se define: \[
\hat{R} = \sqrt{\frac{\frac{S-1}{S} W + \frac{1}{S} B}{W}}
\]
con: \[
\begin{aligned}
\bar{\theta}_{\cdot m} &= \frac{1}{S} \sum_{s=1}^S \theta_{sm} && \text{Promedio de la cadena } m \\
\bar{\theta}_{\cdot \cdot} &= \frac{1}{M} \sum_{m=1}^M \bar{\theta}_{\cdot m} && \text{Promedio global} \\
s^2_m &= \frac{1}{S-1} \sum_{s=1}^S \left(\theta_{sm} - \bar{\theta}_{\cdot m}\right)^2 && \text{Varianza de la cadena } m
\end{aligned}
\]
Además:
\(S\) es la cantidad de muestras en cada cadena.
\(M\) es la cantidad de cadenas.
\(\theta_{sm}\) es un valor de \(\theta\) muestreado en el paso \(s\) de la cadena \(m\).
En R, definimos:
calcular_W <-function(muestras) {# muestras: matriz de dimensión (n_muestras, n_cadenas)return(mean(apply(muestras, 2, var)))}calcular_B <-function(muestras) {# muestras: matriz de dimensión (n_muestras, n_cadenas) S <-nrow(muestras) # cantidad de muestras M <-ncol(muestras) # cantidad de cadenas media_cadenas <-apply(muestras, 2, mean) media_global <-mean(media_cadenas) diferencias_cuadrado <- (media_cadenas - media_global) ^2return(S / (M -1) *sum(diferencias_cuadrado))}calcular_R <-function(muestras) {# muestras: matriz de dimensión (n_muestras, n_cadenas) S <-nrow(muestras) W <-calcular_W(muestras) B <-calcular_B(muestras) numerador <- ((S -1) / S) * W + B / Sreturn(sqrt(numerador / W))}
Tamaño efectivo de muestra \(N_\text{eff}\)
El número efectivo de muestras, \(N_{\text{eff}}\), estima a cuántas muestras independientes equivalen las muestras autocorrelacionadas obtenidas mediante algoritmos de MCMC, en términos de la incertidumbre de las estimaciones.
Debido a la autocorrelación entre muestras, este valor suele ser menor que la cantidad total de muestras generadas.
Un \(N_{\text{eff}}\) alto indica baja autocorrelación y, por lo tanto, una incertidumbre similar a la que se obtendría con muestras independientes. En cambio, un valor bajo refleja alta autocorrelación y mayor incertidumbre respecto de la que se tendría con un muestreo independiente.
donde \(\text{ACF}(k)\) es la función de autocorrelación para un rezago \(k\).
Notar que la suma infinita en el denominador comienza en \(k = 1\) (y no en \(k = 0\), donde \(\text{ACF}(0) = 1\)).
En la práctica, una regla común para truncar la suma de autocorrelaciones es detenerla en el primer valor de \(k\) tal que \(\text{ACF}(k) < 0.05\).
calcular_n_eff <-function(muestras) {# muestras: vector de longitud 'n_muestras' autocorrelacion <-acf(muestras, lag =Inf, plot =FALSE)$acf limite <-which(autocorrelacion <0.05)[1] numerador <-length(muestras) denominador <-1+2*sum(autocorrelacion[2:limite])return(numerador / denominador)}
Modelo
Se plantea un modelo normal de media desconocida y varianza conocida. Para \(\mu\), se utiliza un prior normal. \[
\begin{aligned}
Y_i &\sim \text{Normal}(\mu, \sigma = 1.2) \\
\mu &\sim \text{Normal}(6, 1.8^2)
\end{aligned}
\]
Se cuenta con un vector de observaciones \(\boldsymbol{y}\):
donde tanto \(p_y\) como \(p_\mu\) son densidades normales.
En R:
# Función que depende de parámetros y datosposterior_no_normalizado <-function(mu, y) {exp(sum(dnorm(y, mean = mu, sd =1.2, log =FALSE)) +dnorm(mu, mean =6, sd =1.8, log =TRUE))}# Función que depende de parámetrosp <- purrr::partial(posterior_no_normalizado, y = y)# Se comprueba que ambas calculan la misma cantidadcat(posterior_no_normalizado(4, y) ==p(4))
TRUE
Aplicación
En todos los casos se utilizan 4 cadenas de 5000 muestras cada una. En cada caso, se utilizan diferentes desvíos estándar para la distribución de propuesta normal algoritmo de Metropolis-Hastings. Además, se visualizan los traceplots y se calculan los estadísticos \(\hat{R}\) y \(N_{\text{eff}}\).
Caso 1: \(\sigma=0.05\)
muestras <-list()n_muestras <-5000n_cadenas <-4sigma <-0.05# Se llama a la función `metropolis_hastings` y se guardan los resultados en una lista.# La posición inicial de las cadenas está dada por un valor al azar de una normal estándar.for (j inseq_len(n_cadenas)) { muestras[[j]] <-metropolis_hastings(n = n_muestras,x =rnorm(1),p = p,sigma = sigma )}
Se crea un data.frame que contiene las muestras para las diferentes cadenas. Lo necesitamos para crear el traceplot.
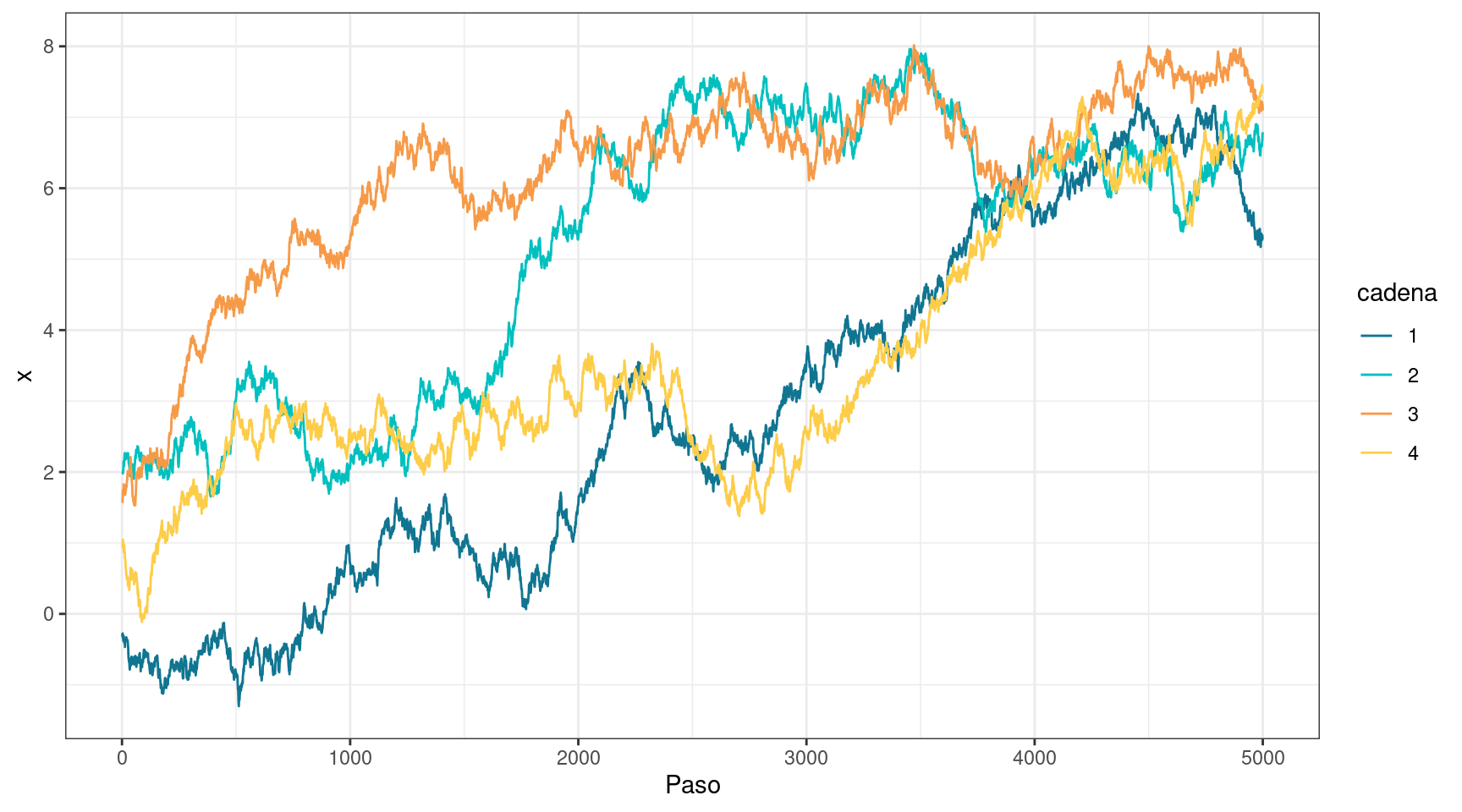
En el traceplot, las cadenas se mueven lentamente, lo que indica una alta autocorrelación. Además, no se mezclan y tampoco parecen converger a ninguna distribución objetivo. El valor de \(\hat{R}\) es considerablemente mayor a 1, lo que también señala falta de convergencia y resulta consistente con lo observado en el traceplot. Además, el tamaño efectivo de muestra en cada cadena es muy bajo, y en consecuencia, el tamaño efectivo de muestra total también lo es, lo cual es coherente con cadenas que presentan una autocorrelación muy alta.
Así, se concluye que no se pueden utilizar las muestras para realizar inferencia. Decidimos incrementar el desvío estándar de la distribución de propuesta.
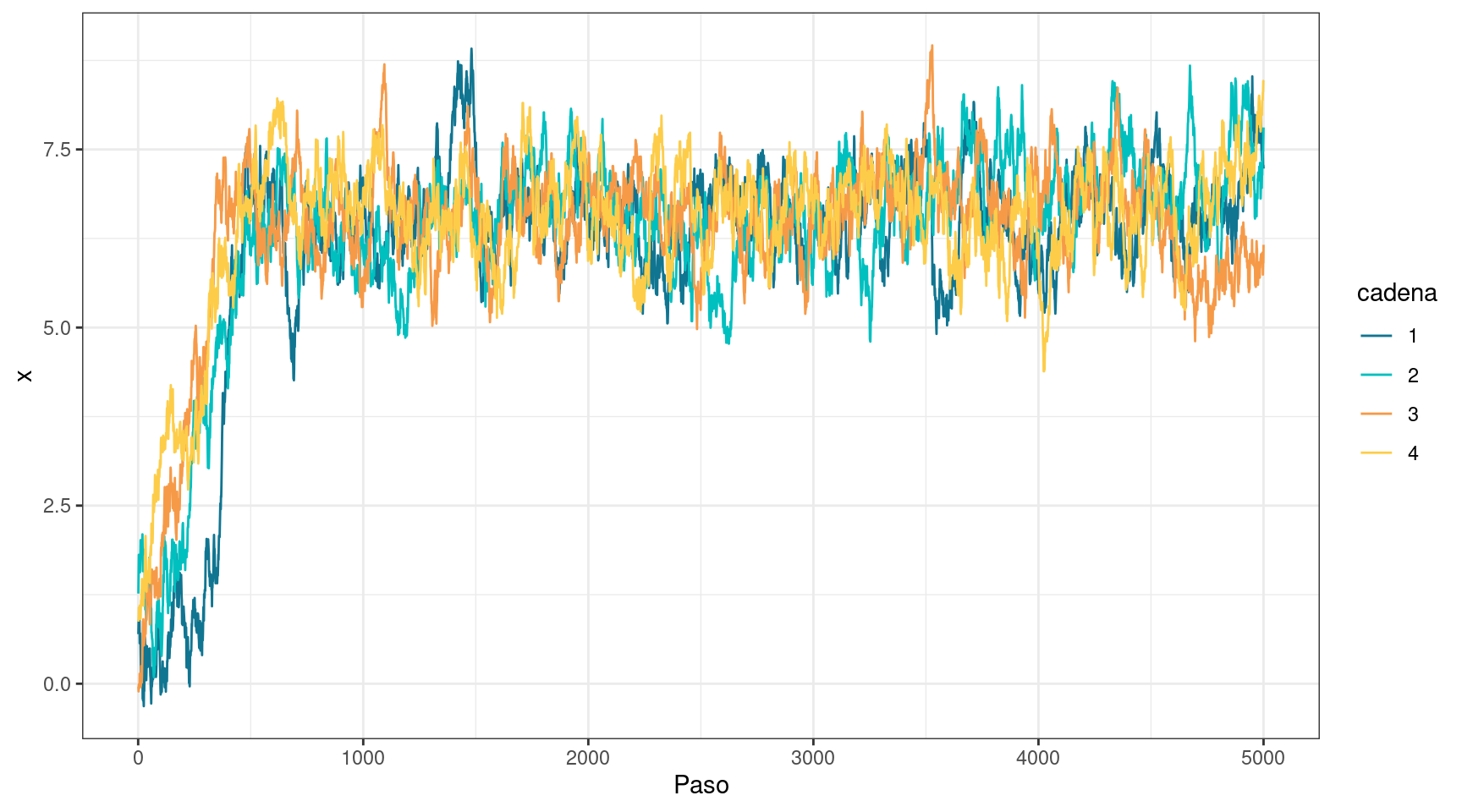
En este caso, las cadenas parecen converger a una distribución objetivo común. Sin embargo, el movimiento todavía resulta lento, lo que es consistente con cadenas que presentan alta autocorrelación. El valor de \(\hat{R}\) ahora es prácticamente igual a 1, en línea con la mezcla que se observa. A pesar de esto, el tamaño efectivo de muestra sigue siendo considerablemente bajo: las 20 000 muestras obtenidas tienen un poder de estimación equivalente al de aproximadamente 70 muestras independientes.
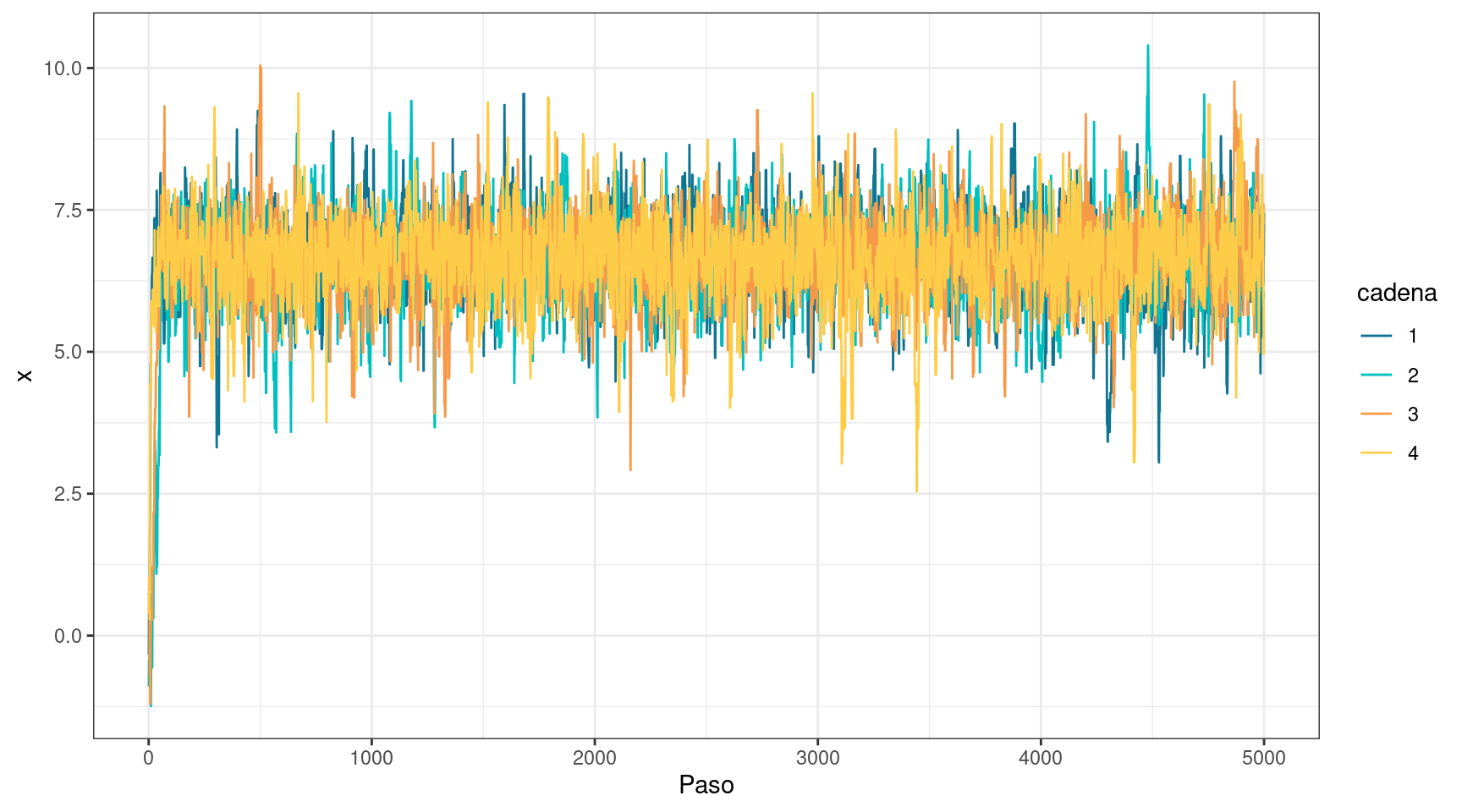
Finalmente, las cadenas convergen, se mezclan y parecen generar muestras representativas de la distribución objetivo. Esto se refleja en el traceplot, donde el patrón no se distingue del de un ruido blanco una vez que las cadenas convergen; en el valor de \(\hat{R}\), que es prácticamente igual a 1; y en el tamaño efectivo de muestra, que ahora alcanza aproximadamente 2000.
Ahora sí, se tiene confianza en que se pueden realizar inferencias válidas sobre \(\mu\) a partir de las muestras obtenidas mediante Metropolis-Hastings.
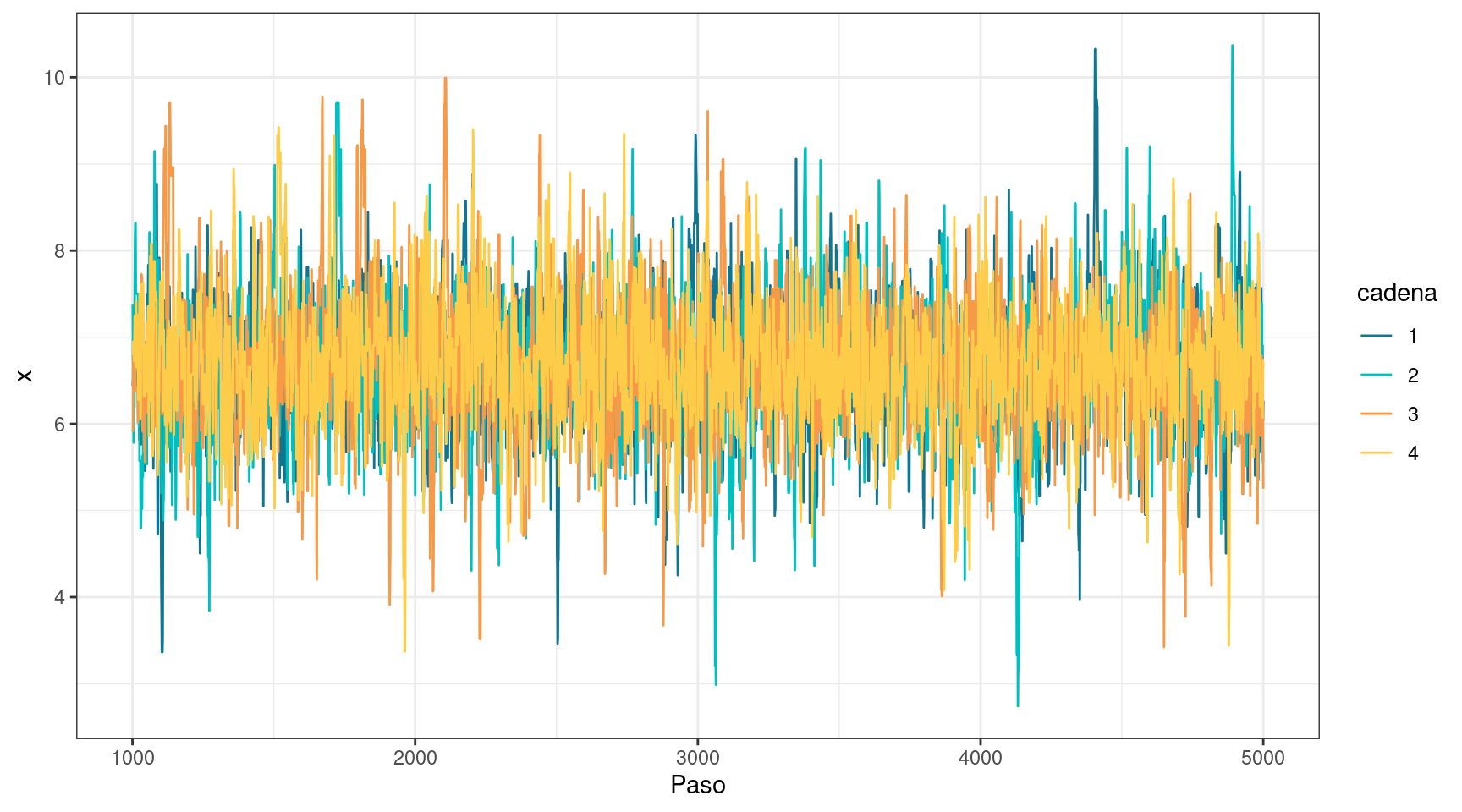
Caso 4: \(\sigma=1\) con descarte de muestras
A continuación se muestra cómo descartar un conjunto inicial de muestras. Estas corresponden al período en que la cadena aún se encuentra convergiendo. Dado que esas muestras no provienen de la distribución objetivo, es recomendable eliminarlas. En este caso, se descartan las primeras 1000 muestras de cada cadena.
Todos los diagnósticos son tan buenos como los obtenidos en el punto anterior, lo que indica que es seguro realizar inferencias sobre \(\mu\) a partir de las muestras obtenidas. Además, vale la pena destacar que el tamaño efectivo de muestra ha aumentado, lo cual se debe al descarte de las muestras iniciales, que presentan mayor autocorrelación.
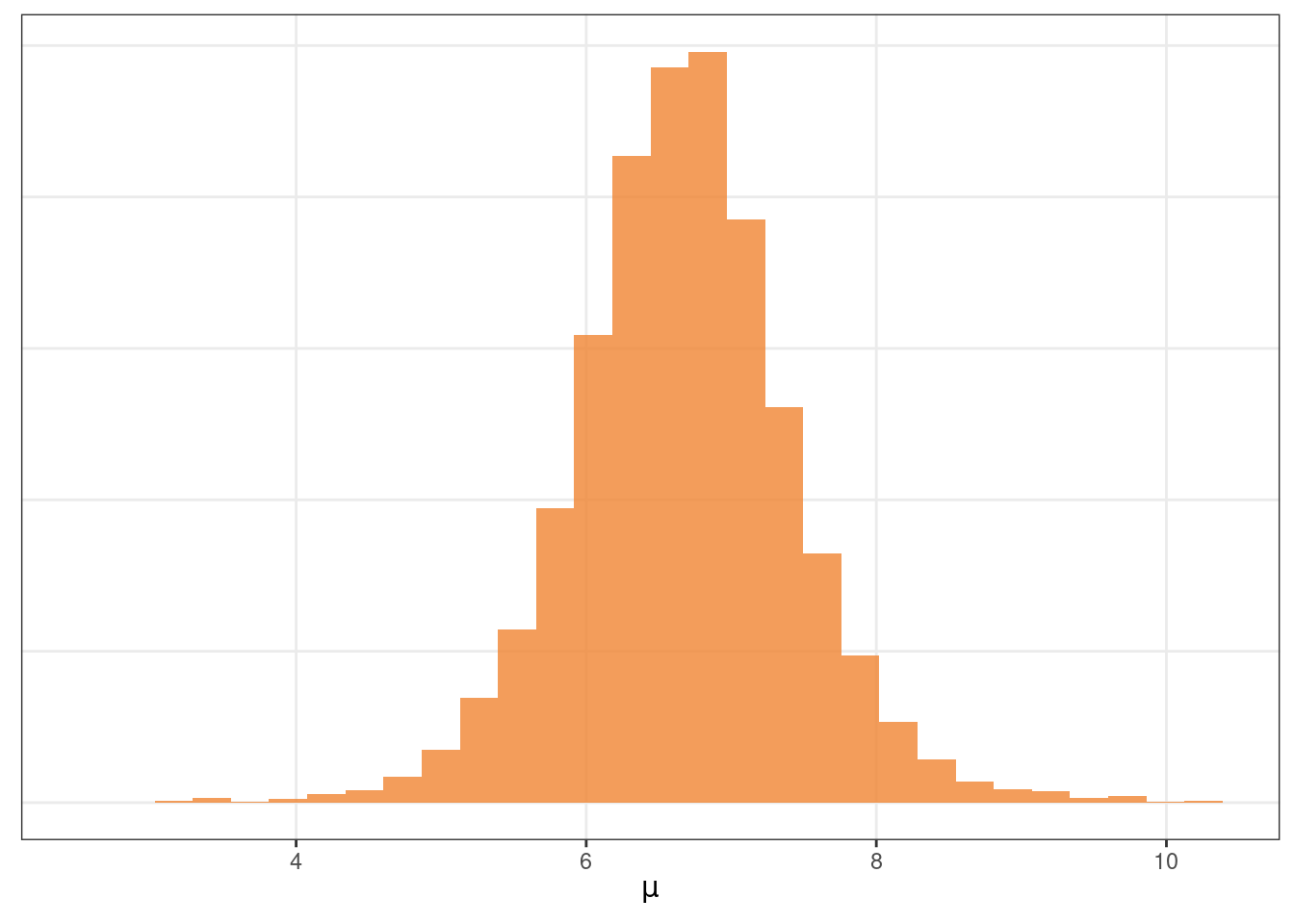
Para finalizar, se visualiza la distribución a posteriori de \(\mu\) mediante un histograma, y se lo resume utilizando la media y un intervalo de credibilidad central del 94%.
ggplot(df_muestras) +geom_histogram(aes(x = valor), bins =30, fill ="#f08533", alpha =0.8) +labs(x =expression(mu), y =NULL) +theme_bw() +theme(panel.grid.minor =element_blank(),axis.ticks.y =element_blank(),axis.text.y =element_blank() )
No existe una forma única de “calcular” (en realidad, estimar) los estadísticos \(\hat{R}\) y \(N_{\text{eff}}\). Para más información se puede consultar la bibliografía de la materia, o la documentación de Stan sobre estos temas.