Código
library(ggplot2)
custom_theme <- function() {
theme_bw() +
theme(
panel.grid.minor = element_blank(),
panel.grid.major = element_blank()
)
}
theme_set(custom_theme())Este programa obtiene la distribución a posteriori para los diferentes casos del ejercicio ¿Quién domina el posterior? de la Práctica 2.
Creamos dos funciones para simplificar los bloques de código en cada caso. La primera, generar_datos(), recibe una grilla para \(\pi\), los valores de \(p(\pi)\), \(p(y \mid \pi)\) y \(p(\pi, \mid y)\) en cada valor de la grilla, y devuelve un data.frame que permite graficar las 3 curvas con {ggplot2}. La segunda, generar_grafico(), simplemente toma el data.frame generado por generar_datos() y produce la visualización.
library(ggplot2)
custom_theme <- function() {
theme_bw() +
theme(
panel.grid.minor = element_blank(),
panel.grid.major = element_blank()
)
}
theme_set(custom_theme())grid_n <- 200
pi_grid <- seq(0, 1, length.out = grid_n)
generar_datos <- function(pi_grid, pi_prior, pi_likelihood, pi_posterior) {
grid_n <- length(pi_grid)
datos <- data.frame(
x = rep(pi_grid, times = 3),
y = c(pi_prior, pi_likelihood, pi_posterior),
1 grupo = factor(
rep(c("prior", "likelihood", "posterior"), each = grid_n),
levels = c("prior", "likelihood", "posterior"),
ordered = TRUE
)
)
return(datos)
}
generar_grafico <- function(datos) {
colores <- c("#f08533", "#3b78b0", "#d1352c")
plt <- ggplot(datos) +
geom_line(aes(x = x, y = y, color = grupo), linewidth = 1) +
scale_color_manual(values = colores) +
labs(x = expression(pi), y = NULL) +
facet_wrap(~ grupo, scales = "free_y") +
theme(
axis.ticks.y = element_blank(),
axis.text.y = element_blank(),
legend.position = "none"
)
return(plt)
}factor() ordenado para indicarle a {ggplot2} que primero se ubica el prior, luego el likelihood, y finalmente el posterior.
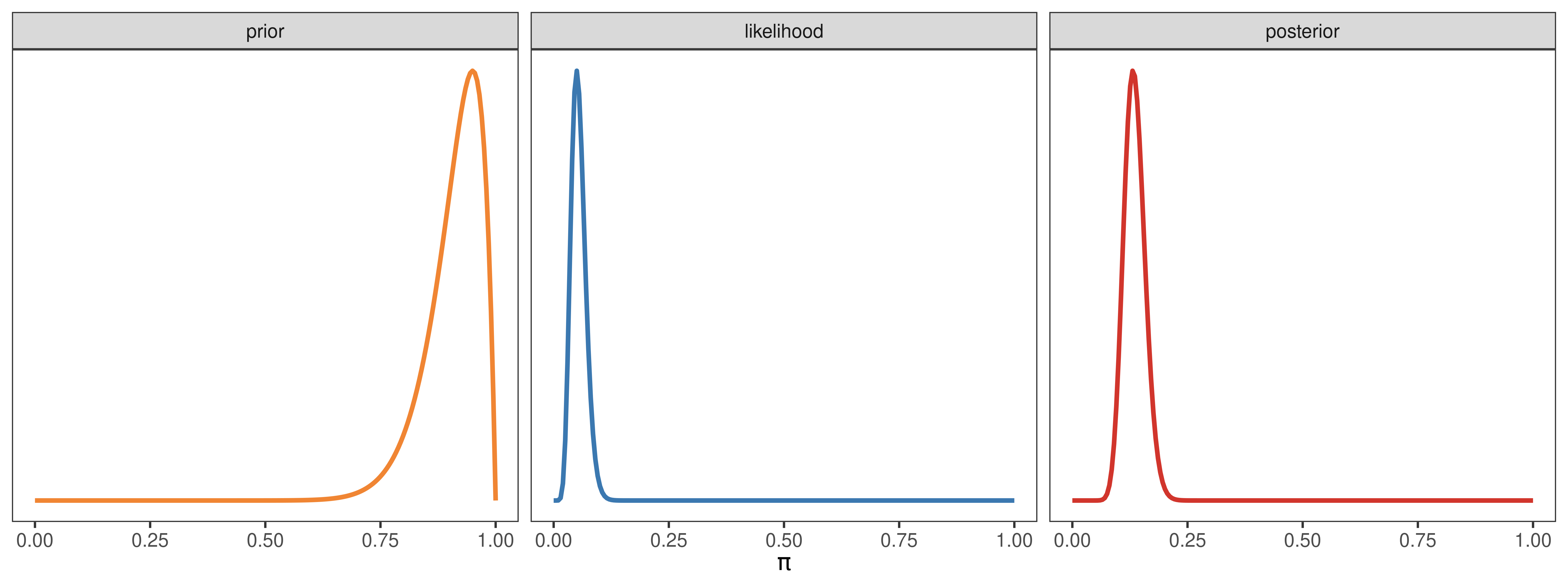
Caso i
a_prior <- 1
b_prior <- 4
y <- 8
N <- 10
pi_prior <- dbeta(pi_grid, a_prior, b_prior)
pi_likelihood <- dbinom(y, N, pi_grid)
pi_posterior <- dbeta(pi_grid, a_prior + y, b_prior + N - y)
datos <- generar_datos(pi_grid, pi_prior, pi_likelihood, pi_posterior)
generar_grafico(datos)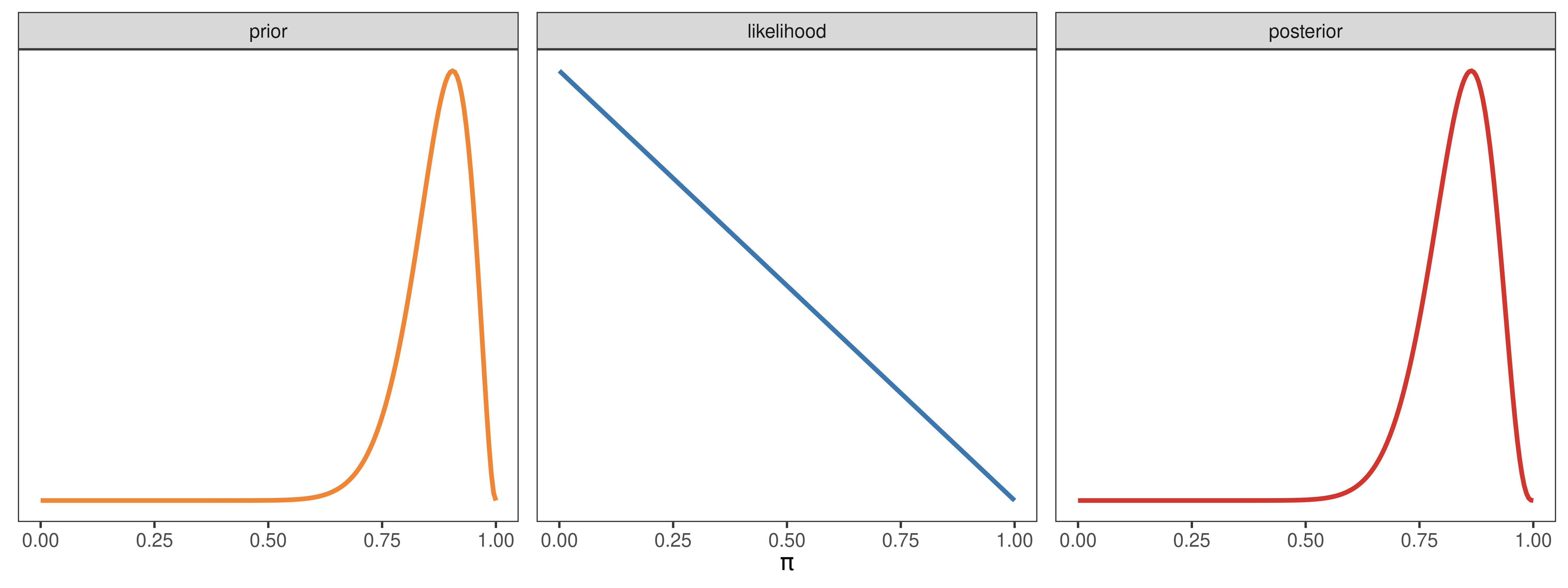
Caso ii
a_prior <- 20
b_prior <- 3
y <- 0
N <- 1
pi_prior <- dbeta(pi_grid, a_prior, b_prior)
pi_likelihood <- dbinom(y, N, pi_grid)
pi_posterior <- dbeta(pi_grid, a_prior + y, b_prior + N - y)
datos <- generar_datos(pi_grid, pi_prior, pi_likelihood, pi_posterior)
generar_grafico(datos)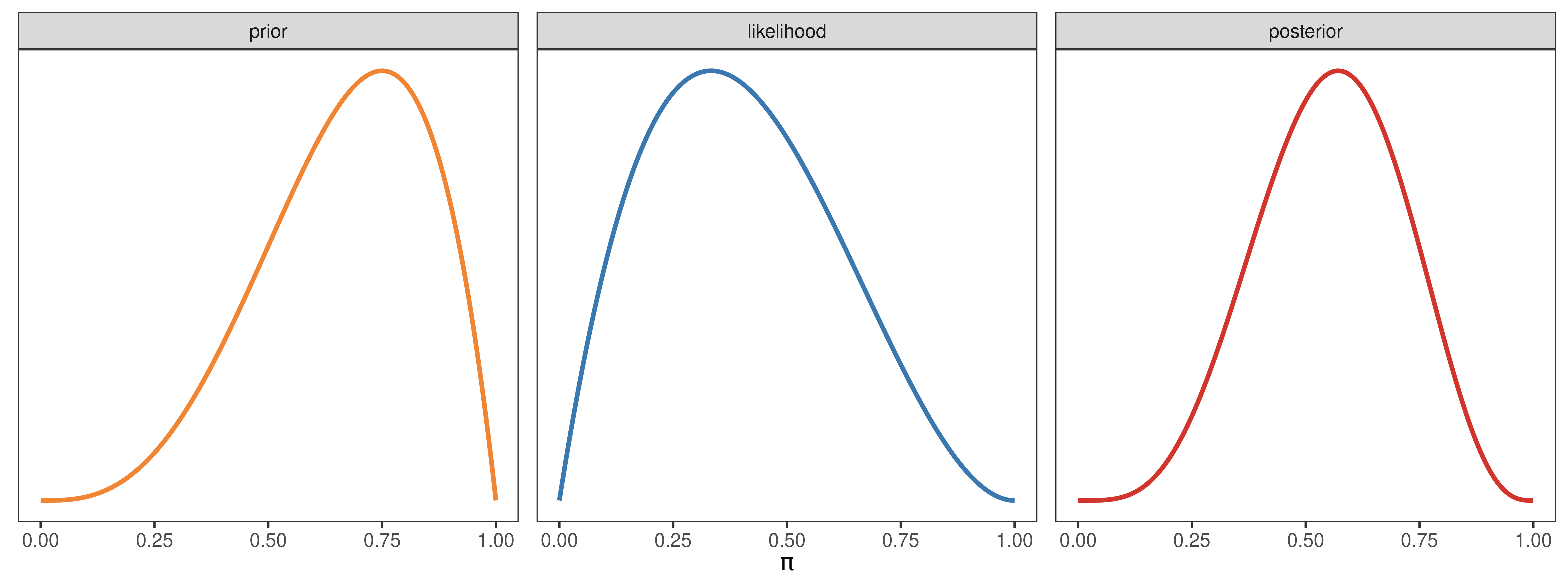
Caso iii
a_prior <- 4
b_prior <- 2
y <- 1
N <- 3
pi_prior <- dbeta(pi_grid, a_prior, b_prior)
pi_likelihood <- dbinom(y, N, pi_grid)
pi_posterior <- dbeta(pi_grid, a_prior + y, b_prior + N - y)
datos <- generar_datos(pi_grid, pi_prior, pi_likelihood, pi_posterior)
generar_grafico(datos)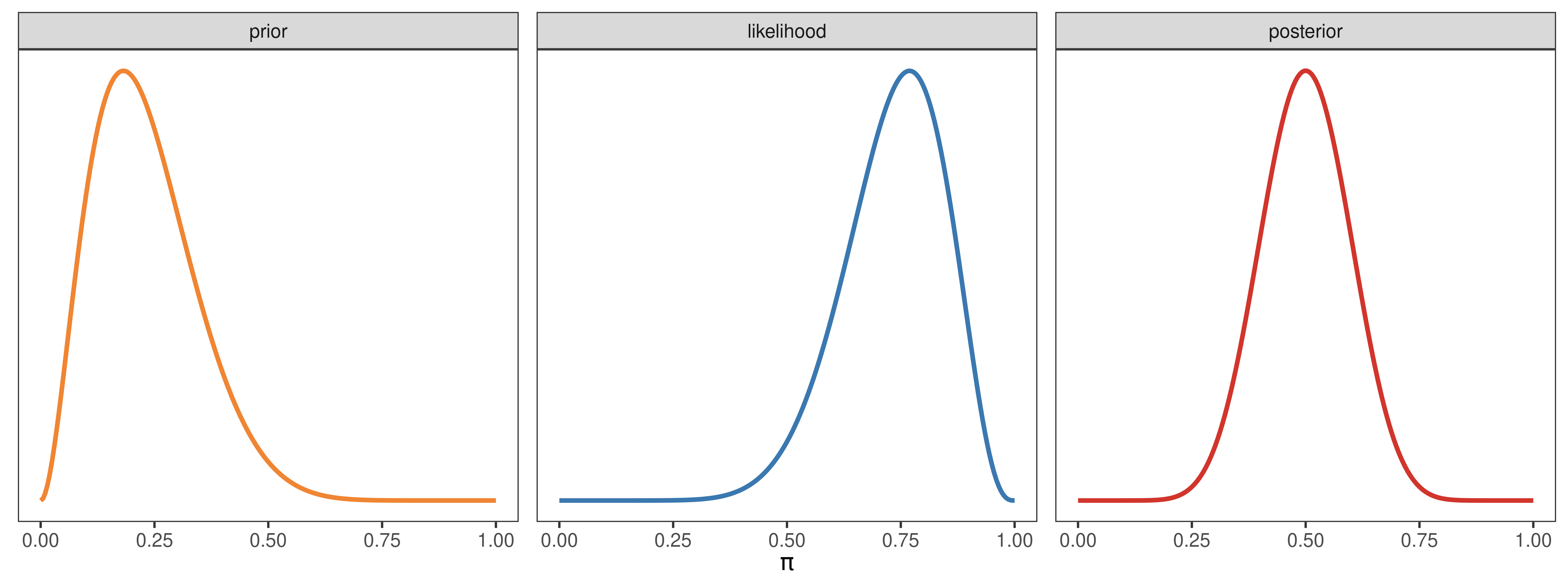
Caso iv
a_prior <- 3
b_prior <- 10
y <- 10
N <- 13
pi_prior <- dbeta(pi_grid, a_prior, b_prior)
pi_likelihood <- dbinom(y, N, pi_grid)
pi_posterior <- dbeta(pi_grid, a_prior + y, b_prior + N - y)
datos <- generar_datos(pi_grid, pi_prior, pi_likelihood, pi_posterior)
generar_grafico(datos)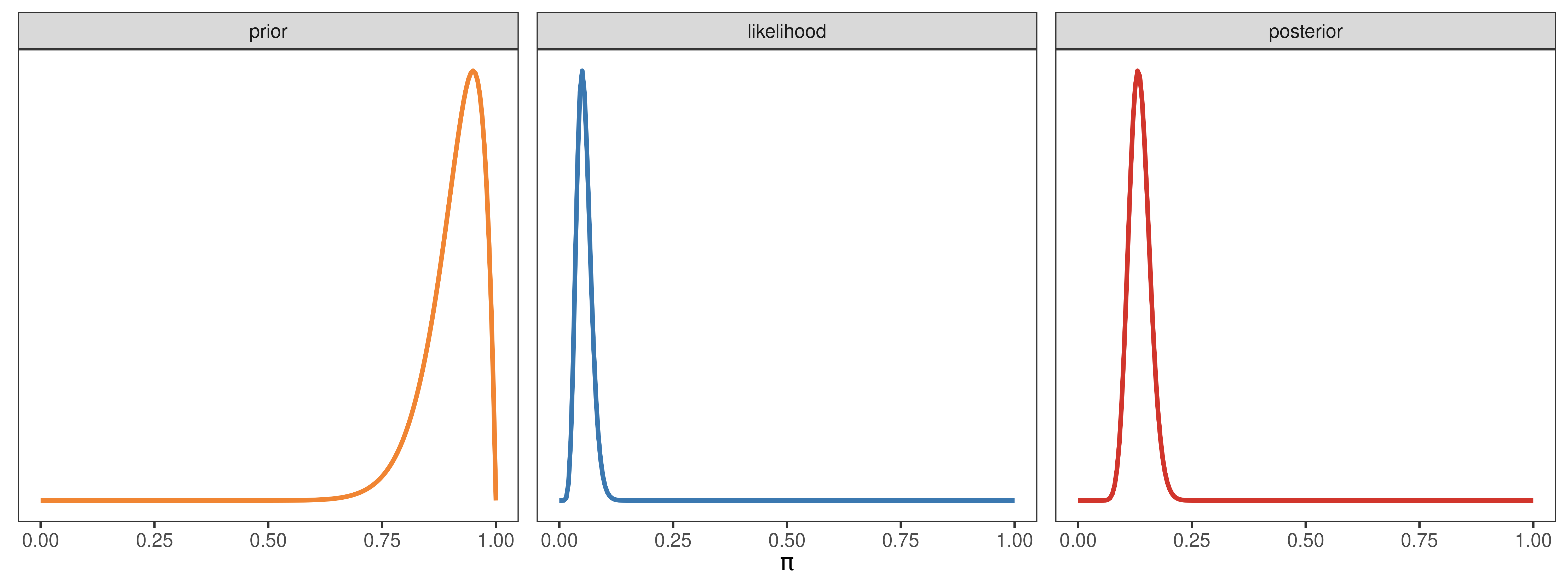
Caso v
a_prior <- 20
b_prior <- 2
y <- 10
N <- 200
pi_prior <- dbeta(pi_grid, a_prior, b_prior)
pi_likelihood <- dbinom(y, N, pi_grid)
pi_posterior <- dbeta(pi_grid, a_prior + y, b_prior + N - y)
datos <- generar_datos(pi_grid, pi_prior, pi_likelihood, pi_posterior)
generar_grafico(datos)