mi_lista <- list(
c(-4.5, 12, 2.71),
c("hola", "chau"),
matrix(c(8, 11, 13, 16), nrow = 2),
TRUE
)
mi_lista[[1]]
[1] -4.50 12.00 2.71
[[2]]
[1] "hola" "chau"
[[3]]
[,1] [,2]
[1,] 8 13
[2,] 11 16
[[4]]
[1] TRUEEn este capítulo vamos a introducir una nueva estructura de datos fundamental en R: las listas. A diferencia de los vectores y matrices que vimos hasta ahora, las listas permiten almacenar elementos de distinto tipo y estructura dentro de un mismo objeto. Esto las convierte en una herramienta muy flexible para trabajar con datos complejos y variados. Aprenderemos cómo se crean, cómo se accede a sus elementos y cómo se utilizan en distintos contextos.
Una lista en R es una estructura de datos que permite almacenar múltiples elementos de distinto tipo en un mismo objeto. Es la herramienta que nos brinda R para agrupar objetos que no necesariamente tienen la misma forma ni el mismo tipo de datos. Así, dentro de una lista podemos guardar números, caracteres, vectores, matrices, otras listas, funciones, o incluso resultados completos de modelos estadísticos. Podemos imaginarla como una bolsa en la cual podemos meter todo tipo de objetos.
Esto la diferencia de estructuras más rígidas como los vectores atómicos o las matrices, en los que todos los elementos deben ser del mismo tipo (por ejemplo, todos números o todos caracteres). Las listas no imponen esta restricción: son heterogéneas por definición. Este tipo de estructura no es exclusiva de R. De hecho, en otros lenguajes de programación se encuentran construcciones similares, aunque con distintos nombres o particularidades.
El siguiente diagrama presenta una lista de R (recuadro con puntas redondeadas) que contiene:
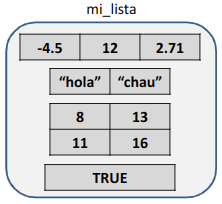
La creación de esta lista se realiza mediante la función list(), cuyos argumentos son los elementos que queremos guardar en la lista, separados por comas:
mi_lista <- list(
c(-4.5, 12, 2.71),
c("hola", "chau"),
matrix(c(8, 11, 13, 16), nrow = 2),
TRUE
)
mi_lista[[1]]
[1] -4.50 12.00 2.71
[[2]]
[1] "hola" "chau"
[[3]]
[,1] [,2]
[1,] 8 13
[2,] 11 16
[[4]]
[1] TRUELuego de correr la sentencia anterior, podemos ver que mi_lista es un nuevo objeto disponible en el ambiente global y como tal está listado en el panel Environment. Allí se nos indica que se trata de una lista y, además, podemos previsualizar su contenido al hacer clic en el círculo celeste que antecede a su nombre:
Usamos dobles corchetes [[ ]] para referenciar a cada objeto que forma parte de la lista. Además, si queremos indicar un elemento dentro de un objeto que forma parte de la lista, agregamos otro conjunto de corchetes como hacemos con vectores y matrices. Por ejemplo:

mi_lista[[1]][1] -4.50 12.00 2.71mi_lista[[1]][3][1] 2.71mi_lista[[2]][1] "hola" "chau"mi_lista[[2]][2][1] "chau"mi_lista[[3]] [,1] [,2]
[1,] 8 13
[2,] 11 16mi_lista[[3]][2, 1][1] 11mi_lista[[3]][2, ][1] 11 16mi_lista[[4]][1] TRUEmi_lista[[4]][1][1] TRUEPodemos asignar valor a algún elemento usando los índices de esa misma forma:
mi_lista[[1]][3] <- 0
mi_lista[[1]]
[1] -4.5 12.0 0.0
[[2]]
[1] "hola" "chau"
[[3]]
[,1] [,2]
[1,] 8 13
[2,] 11 16
[[4]]
[1] TRUECada uno de los elementos de una lista puede tener un nombre propio. Podemos asignarle un nombre a uno, algunos o todos los integrantes en una lista:
mi_lista <- list(
w = c(-4.5, 12, 2.71),
x = c("hola", "chau"),
y = matrix(c(8, 11, 13, 16), nrow = 2),
z = TRUE
)
mi_lista$w
[1] -4.50 12.00 2.71
$x
[1] "hola" "chau"
$y
[,1] [,2]
[1,] 8 13
[2,] 11 16
$z
[1] TRUEEsto amplía las opciones para hacer referencia a cada objeto y elemento allí contenido. Las siguientes sentencias son todas equivalentes y sirven para acceder al tercer elemento de la lista, cuyo nombre es y:
mi_lista[[3]] [,1] [,2]
[1,] 8 13
[2,] 11 16mi_lista[["y"]] [,1] [,2]
[1,] 8 13
[2,] 11 16mi_lista$y [,1] [,2]
[1,] 8 13
[2,] 11 16La última opción hace uso de $, el operador de acceso de R, que utiliza para acceder a un elemento de una lista (si tiene nombre) o a una columna de un data.frame. El operador $ simplifica la extracción de elementos específicos, haciendo que el código sea más legible y eficiente que cuando se emplean corchetes.
Una de las aplicaciones más frecuentes y prácticas de las listas en R es su uso como estructura de salida de funciones. En la Unidad 3 sobre funciones mencionamos que las mismas pueden devolver exactamente un objeto como resultado. Esto puede ser una limitación, ya que en algunos casos tal vez necesitemos devolver varios elementos de distinto tipo1.
Las listas permiten que las funciones devuelvan una colección de resultados relacionados, sin perder la flexibilidad de acceder a cada uno por separado, y sin forzar al usuario a usar estructuras más rígidas o artificiales. Gracias a esto, podemos inspeccionar, manipular o extraer partes de un resultado complejo sin necesidad de descomponerlo manualmente. Si escribimos funciones que devuelven más de un resultado (por ejemplo, una media y una desviación estándar), la forma más clara y ordenada de hacerlo es con una lista nombrada.
Para ejemplificar, recordemos el ejercicio de la práctica 3 que pide escribir una función triangulos(a, b, c). A partir de la longitud de los tres lados de un triángulo a, b y c, esta función lo clasifica como “equilátero”, “isósceles” o “escaleno”, o bien devuelve un texto diciendo que las medidas provistas no son compatibles con la definición de un triángulo:
triangulos <- function(a, b, c) {
if (a > b + c || b > a + c || c > a + b) {
return("no es triángulo")
} else if (a == b & a == c) {
return("equilátero")
} else if (a == b || a == c || b == c) {
return("isósceles")
} else {
return("escaleno")
}
}Vamos a modificar la función para que tenga el siguiente comportamiento: la función debe devolver el tipo de triángulo como cadena de texto y el valor numérico del perímetro del mismo (o un 0 si no es triángulo). Es decir, la función debe devolver tanto un objeto de tipo carácter y otro de tipo numérico. Para lograrlo los encerraremos en una lista:
triangulos <- function(a, b, c) {
perim <- a + b + c
if (a > b + c || b > a + c || c > a + b) {
tipo <- "no es triángulo"
perim <- 0
} else if (a == b & a == c) {
tipo <- "equilátero"
} else if (a == b || a == c || b == c) {
tipo <- "isósceles"
} else {
tipo <- "escaleno"
}
return(list(triangulo = tipo, perimetro = perim))
}En la línea final, encontramos triangulo = tipo: tipo es uno de los elementos que ponemos en la lista y debe ser una variable local en la función; mientras que triangulo es un nombre que elegimos para este elemento en la lista definida y puede ser cualquier palabra que deseemos. Lo mismo ocurre con perimetro = perim. Veamos ejemplos del uso de esta función:
# Guardamos el resultado devuelto (una lista) en el objeto resultado
resultado <- triangulos(2, 3, 4)
# Miramos todo el contenido de la lista
resultado$triangulo
[1] "escaleno"
$perimetro
[1] 9# Accedemos a sus elementos por nombre con el operador de acceso
resultado$triangulo[1] "escaleno"resultado$perimetro[1] 9# Accedemos a sus elementos por nombre con corchetes
resultado[["triangulo"]][1] "escaleno"resultado[["perimetro"]][1] 9# Accedemos a sus elementos por posición
resultado[[1]][1] "escaleno"resultado[[2]][1] 9Muchas funciones del sistema y de paquetes externos devuelven sus resultados en forma de lista, especialmente cuando se necesita devolver más de un objeto o cuando los resultados son complejos o estructurados.
Tal vez no lo hayas hecho aún, pero muy pronto comenzarás a “ajustar” muchos modelos estadísticos. Los más básicos se llaman “modelos lineales” y se pueden ajustar en R con la función lm(), que es un ejemplo perfecto de una función que devuelve una lista con varios componentes: los coeficientes del modelo, los residuos, la fórmula utilizada, el número de observaciones, entre otros que ya aprenderás a interpretar. Este conjunto de resultados no puede ser representado de manera sencilla en una sola estructura homogénea como un vector o una matriz, por lo que la lista se presenta como una solución natural:
# Ajuste de un modelo lineal con los datos del data.frame de ejemplo "mtcars"
modelo <- lm(mpg ~ hp + wt, data = mtcars)
class(modelo)[1] "lm"# Elementos de la lista llamada "modelo", con todos los resultados del análisis
names(modelo) [1] "coefficients" "residuals" "effects" "rank"
[5] "fitted.values" "assign" "qr" "df.residual"
[9] "xlevels" "call" "terms" "model" En este caso, modelo es una lista con clase "lm", que contiene múltiples objetos relacionados con el modelo ajustado. Podemos acceder a cada componente utilizando el operador [[ ]] o el operador $, como se muestra a continuación:
modelo$coefficients(Intercept) hp wt
37.22727012 -0.03177295 -3.87783074 modelo[["residuals"]][1:5] Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive
-2.5723294 -1.5834826 -2.4758187 0.1349799
Hornet Sportabout
0.3727334 Aunque solemos decir que una lista puede contener “cualquier cosa”, eso no es del todo exacto si hablamos en términos técnicos.
Desde el punto de vista interno de R, una lista es una estructura que agrupa referencias a distintos objetos (algo como “punteros”, si estás familiarizado con el mundo de la programación). Es decir, cada elemento de la lista no contiene directamente un valor, sino que apunta a un objeto almacenado en otro lugar de la memoria. Por eso, técnicamente todos los elementos de una lista son del mismo tipo: referencias.
Esto nos da la impresión de que en una lista de R podemos “mezclar” libremente objetos de cualquier tipo, cuando en realidad lo que estamos haciendo es agrupar accesos a distintos objetos en una misma estructura. Lo que varía es el tipo de objeto al que apunta cada referencia: puede ser un número, una cadena de texto, un vector, una función, una matriz, otra lista, etc.
Teniendo en cuenta esto, debemos notar que una lista no es más que un tipo especial de vector, también llamado recursive vector o generic vector, para diferenciarlo de los más básicos atomic vectors que ya conocemos.
Para realizar análisis de datos en R, vas a necesitar emplear data.frames, una estructura con aspecto tabular para organizar datos en filas y columnas. En esta asignatura no trabajamos con datos ni con data.frames, pero es interesante resaltar que un data.frame es, en realidad, una lista de vectores de igual longitud, donde cada vector representa una columna y puede ser de un tipo diferente (numérico, carácter, lógico, factor, etc.). Todas las columnas deben tener la misma cantidad de elementos (filas), lo que permite tratar al data.frame como una tabla rectangular y le confiere características semejantes a las de una matriz.
Verifiquemos que un data.frame es una lista, con ciertos atributos:
datos <- data.frame(x = 1:3, y = letters[1:3])
datos x y
1 1 a
2 2 b
3 3 ctypeof(datos)[1] "list"attributes(datos)$names
[1] "x" "y"
$class
[1] "data.frame"
$row.names
[1] 1 2 3A diferencia de una lista normal, un data.frame tiene ciertas propiedades específicas:
rownames(datos)[1] "1" "2" "3"colnames(datos)[1] "x" "y"nrow(datos)[1] 3ncol(datos)[1] 2length(datos)[1] 2Los data.frames son una de las ideas más importantes y troncales de R, y uno de los aspectos que lo diferencian de otros lenguajes de programación, que no ofrecen este tipo de estructura de forma nativa. Por eso, R es un lenguaje creado específicamente con el objetivo de realizar análisis de datos, de forma sencilla y directa.
Sin embargo, en los casi 30 años transcurridos desde su creación, la forma en que se usa R ha cambiado, y algunas decisiones de diseño que tenían sentido en su momento ahora causan algunos problemas. Esto condujo a la creación del tibble, una reinvención moderna del data.frame. Es recomendable utilizar tibbles, disponibles en el ecosistema de paquetes tidyverse, ya que son semejantes a los nativos data.frames, con mejores características.Los tibbles están diseñados para ser (en la medida de lo posible) reemplazos directos de los marcos de datos que solucionan estas frustraciones. Una forma concisa y divertida de resumir las principales diferencias es que los tibbles son perezosos y hoscos: hacen menos y se quejan más. Verás lo que esto significa a medida que avances en esta sección.
Si fuesen elementos del mismo tipo, los podríamos devolver dentro de un vector, por ejemplo, las dos soluciones reales distintas de una ecuación cuadrática.↩︎