#Datos Multivariados
library(rgl)
library(plotly)
library(gganimate)
library(ggcleveland)
#Hetmaps
library(pheatmap)
library(corrplot)
#Series
library(echarts4r)
library(highcharter)
#Gráficos varios
library(ggplot2)
library(cowplot)
library(ggradar)
library(ggridges)
#Lectura y manipulación
library(dplyr)
library(tidyr)
library(readr)
library(scales)
#Bases de datos
library(gapminder)
library(quantmod)8 Unidad 4 - Visualización de Variables Cuantitativas
Análisis Exploratorio de Datos | Licenciatura en Estadística | FCEyE | UNR
8.1 Introducción
A lo largo de esta unidad vamos a repasar gráficos para visualizar variables numéricas.
Los paquetes de R a emplear son los siguientes:
8.2 Histogramas
- El histograma es uno de los métodos gráficos más antiguos para representar información univariada.
- Los datos se agrupan en clases o intervalos que se señalan en el eje horizontal, mientras que en el eje vertical se coloca alguna medida que indica la cantidad de observaciones que pertenece a cada intervalo.
- La interpretación que hagamos acerca de la distribución depende mucho de la amplitud elegida para los intervalos, y de su cantidad:
- Si la amplitud es muy pequeña o el número de barras es elevado, el histograma presentará muchos picos y se oscurecerá la visualización de la forma general de la distribución.
- Si la amplitud es muy grande o el número de barras es pequeño, pueden perderse algunas características de la distribución.
8.2.1 Elegir la cantidad de intervalos de un histograma en R
Para generar histogramas usando
ggplot2contamos con la funcióngeom_histogram(). Usaremos los datos de flores de iris para ejemplificar.Las opciones disponibles para elegir la cantidad y amplitud de los intervalos son las siguientes:
- Default: elige siempre 30 intervalos, pero probablemente este valor arbitrario no sea el óptimo para nuestros datos.
- Definir la cantidad de barras: se usa el argumento
bins. - Definir el ancho de cada barra: se usa el argumento
binwidth. - Definir los límites de cada intervalo: se usa el argumento
breaks.
h_base <- ggplot(data = iris) +
aes(x = Petal.Width) +
labs(x = "Ancho de Pétalo", y = "Frecuencia absoluta") +
theme_bw()
h1 <- h_base +
geom_histogram(fill = "forestgreen", col = "black") +
ggtitle("Opción 1: default (30 intervalos)")
h2 <- h_base +
geom_histogram(fill = "forestgreen", col = "black", bins = 10) +
ggtitle("Opción 2: 10 intervalos")
h3 <- h_base +
geom_histogram(fill = "forestgreen", col = "black", binwidth = 0.25) +
ggtitle("Opción 3: intervalos de amplitud 0.25 cm")
h4 <- h_base +
geom_histogram(fill = "forestgreen", col = "black", breaks = seq(0, 2.5, 0.25)) +
ggtitle("Opción 4: límites específicos")
plot_grid(h1, h2, h3, h4)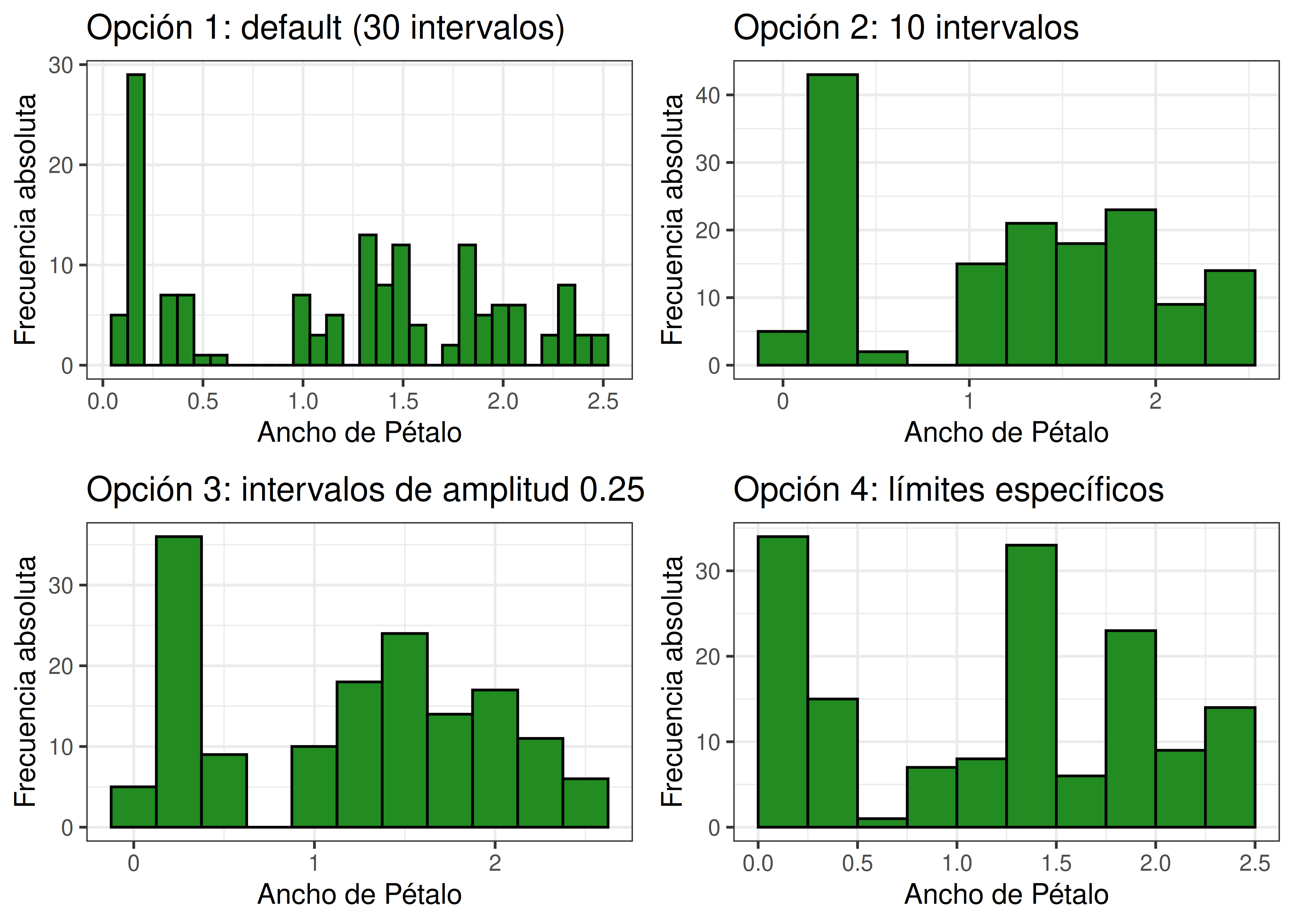
8.2.2 Alternativas a las frecuencias absolutas
Como vimos,
ggplot2grafica por defecto frecuencias absolutas (conteo de la cantidad de individuos que pertenecen a cada intervalo).A continuación vemos 2 alternativas, para las cuales es necesario aplicar la función
after_stat():A) Frecuencia relativa: la suma de las alturas de las barras es igual a 1.
B) Gráfico de densidad: la suma de las áreas de las barras (ancho por alto) es igual a 1. En estos casos, carece de sentido interpretar la altura nominal de cada barra.
h5 <- ggplot(data = iris) +
aes(x = Petal.Width) +
geom_histogram(
aes(y = after_stat(count)/sum(after_stat(count))),
fill = "forestgreen", col = "black", bins = 10
) +
labs(
x = "Ancho de Pétalo", y = "Frecuencia relativa",
title = "Opción A: frecuencia relativa"
)
h6 <- ggplot(data = iris) +
aes(x = Petal.Width) +
geom_histogram(
aes(y = after_stat(density)),
fill = "forestgreen", col = "black", bins = 10
) +
labs(
x = "Ancho de Pétalo", y = "Densidad",
title = "Opción B: Gráfico de Densidad"
)
plot_grid(h5, h6)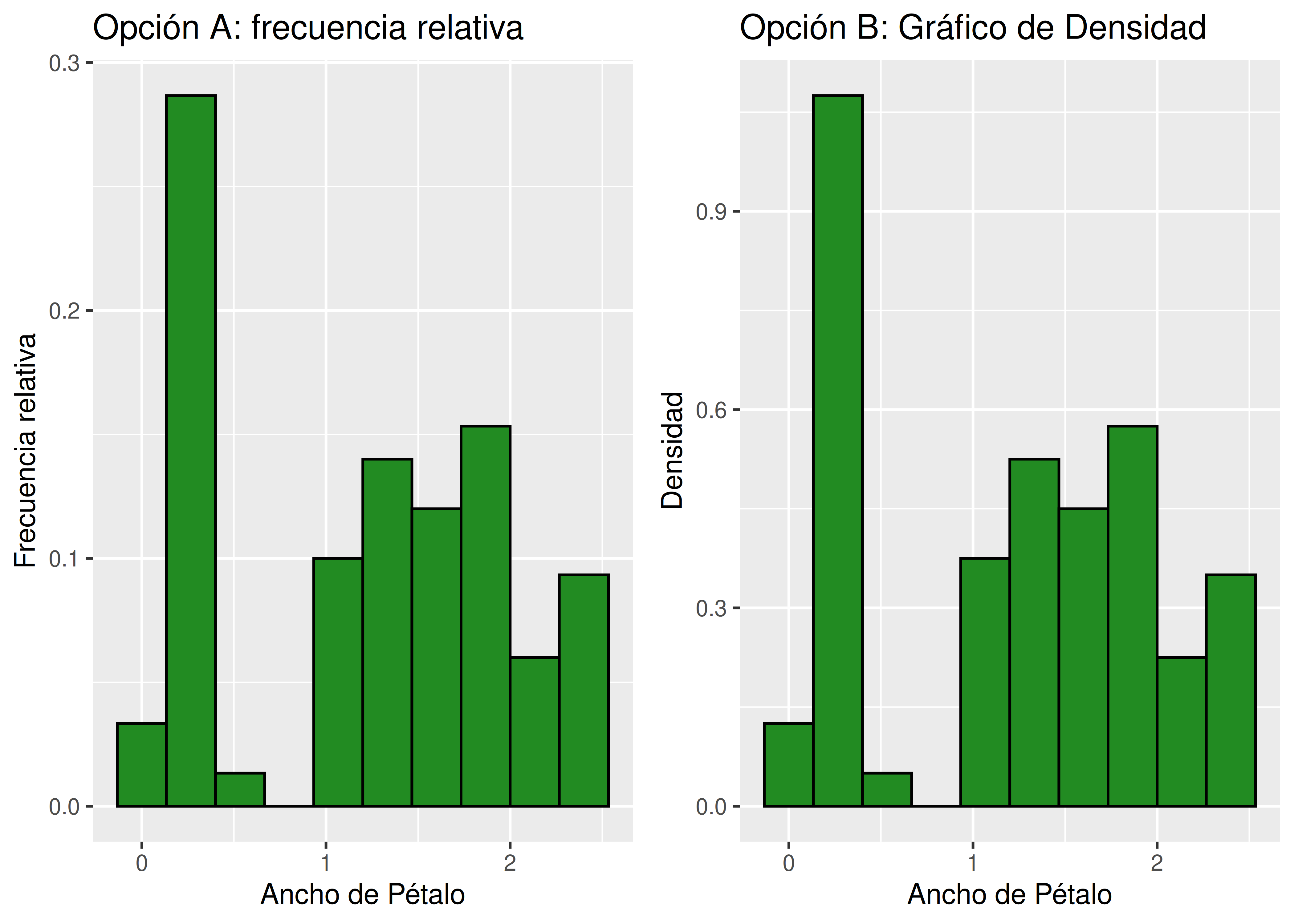
8.3 Curvas de Densidad
Los histogramas han sido muy populares desde siempre, en parte por la facilidad de graficarlos manualmente. Sin embargo, poseen algunas desventajas: no son “suaves” y no son sensibles a cambios locales.
Debido a esto, en la actualidad muchas veces son reemplazados por curvas de densidad, a partir de las cuales intentamos visualizar la distribución de probabilidad subyacente bosquejando una curva continua, la cual es estimada a partir de los datos.
Para esto, se suele emplear un método conocido como estimación de densidades kernel, el cual ajusta una curva continua en la vecindad de cada dato, cuyo tamaño es controlado por un parámetro llamado ancho de banda. Luego se combinan todas esas curvas para obtener la estimación final de la densidad.
El tipo de kernel (núcleo) más utilizado es el gaussiano, pero hay muchas opciones.
Consideremos la definición de \(f(x)\):
\[f(x) \equiv \dfrac{d}{dx}F(x)\equiv \lim\limits_{h \to 0} \dfrac{F(x+h)-F(x-h)}{2h}\]
El histograma estima esta función dividiendo el eje en intervalos, pero un enfoque más sensible es realizar la estimación de la derivada en cada punto \(x\).
Reemplazando \(F(x)\) por la función de distribución acumulada empírica obtenemos:
\[\hat{f}(x)=\dfrac{\#\{x_i \in (x-h,x+h)\}}{2hn}\]
- Esto puede ser reescrito como:
\[\hat{f}(x) = \dfrac{1}{2hn}\sum_{j=1}^n I\Bigg(x_j - h < x \le x_j + h\Bigg)=\dfrac{1}{hn}\sum_{j=1}^n K\Bigg(\dfrac{x-x_j}{h}\Bigg) \]
donde
\[K(u)=\begin{cases}\frac{1}{2} & si\;\;\; {-1<u \leq 1} \\ \\0 & e.o.c. \end{cases}\]
El anterior es un estimador de densidad con función kernel \(K\) que corresponde a una función de densidad uniforme en el \((-1,1]\).
La función
density()del paquetestatspermite estimar funciones de densidad a partir del estimador presentado.Entre los distintos kernels disponibles, el gaussiano es el que se utiliza generalmente, siendo el kernel por defecto en la mayoría de las funciones. A continuación se presentan las distintas opciones:
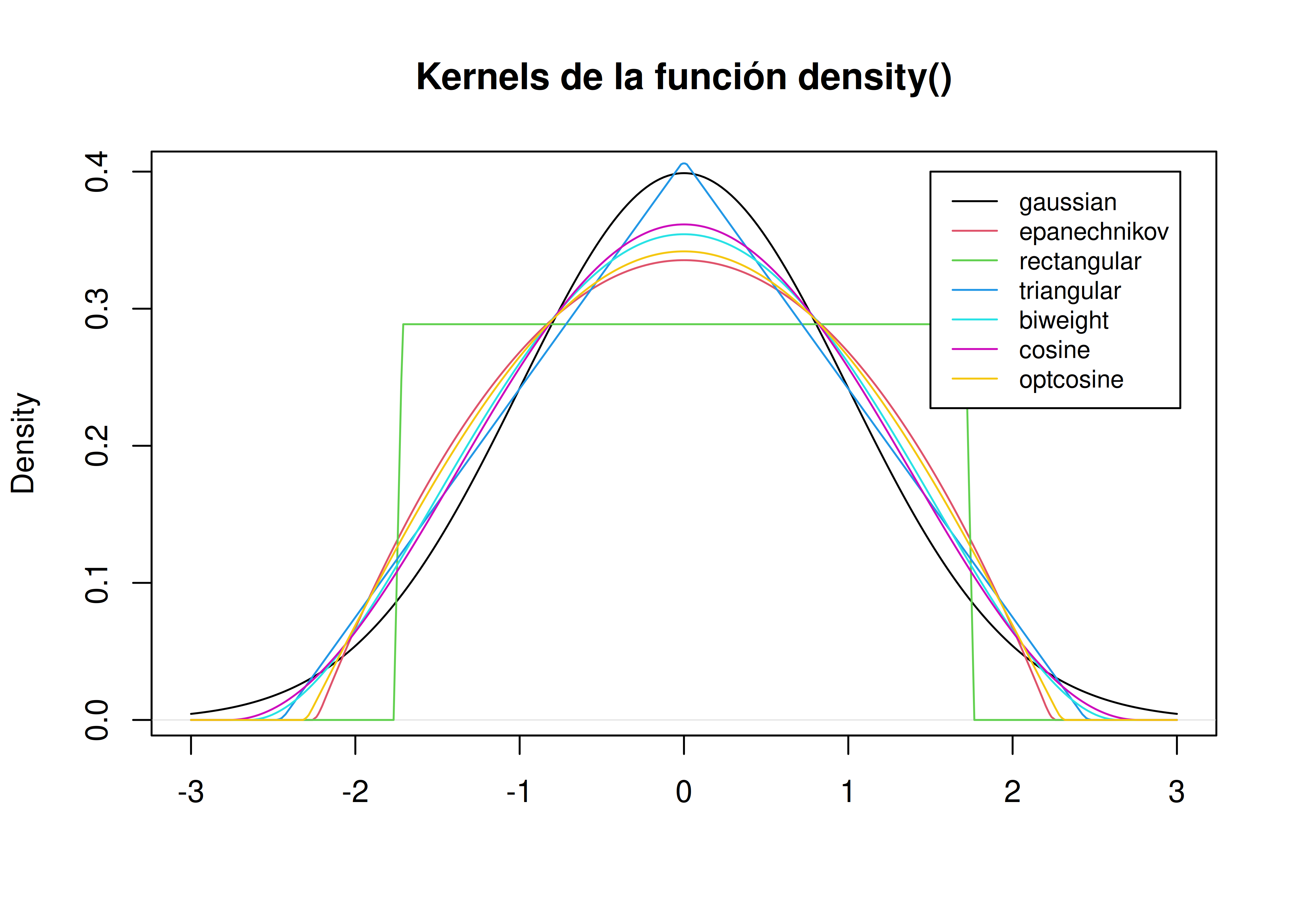
- El resultado depende del ancho de banda, que produce el mismo tipo de efecto que la amplitud de los intervalos en los histogramas, y también del kernel empleado. Por ejemplo, un kernel gaussiano tendrá una tendencia a producir densidades más semejantes a la normal. En contraste, un kernel rectangular puede producir una apariencia escalonada.
- En general, cuantos más datos haya, menos importancia tendrá la elección del kernel. Por lo tanto, los gráficos de densidad suelen ser confiables e informativos para grandes conjuntos de datos, pero pueden ser engañosos en otros casos.
- Las curvas de densidad se escalan para que el área encerrada sea igual a 1, lo cual hace que los valores del eje vertical carezcan de relevancia en cuanto a su interpretación.
Precaución
Los gráficos de densidad suelen dar la apariencia de que existen datos donde nos los hay, especialmente en las colas. En consecuencia, se podrían producir gráficos que presenten curvas que no tengan sentido, por ejemplo, que se extienden hacia valores negativos al representar la distribución de una variable positiva. Para evitar este inconveniente, en los siguientes ejemplos las densidades se cortan en el mínimo y máximo observados.
- Aplicación en R: usamos la función
stat_density()deggplot2:
ggplot(data = iris) +
aes(x = Petal.Width) +
stat_density(fill = "blue", col = "black", kernel = "gaussian")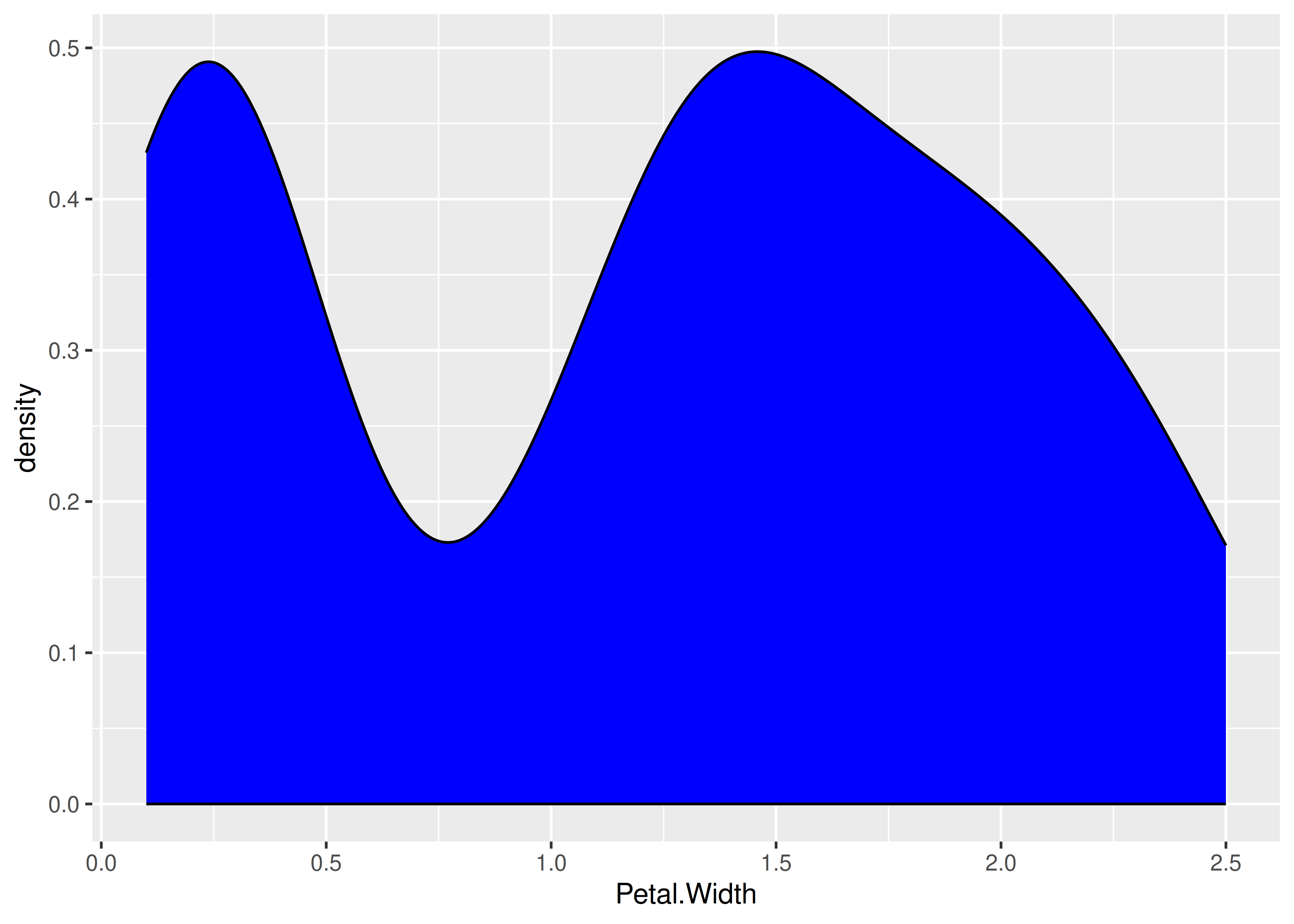
- El parámetro bw (ver
?stats::bw.nrd) especifica la ventana a utilizar en cada estimación de la densidad, y es un múltiplo del desvío estándar del kernel especificado. - Valores grandes de bw nos dan una curva más suave (menor variancia) pero también más sesgada.
- R utiliza ciertos valores por defecto, los cuales pueden no funcionar bien para ciertos conjuntos de datos, siendo nuestro deber proporcionar valores más apropiados.
- Debajo vemos el efecto del ancho de banda y de la selección del kernel:
curva_base <- ggplot(data = iris) + aes(x = Petal.Width)
g1 <- curva_base +
stat_density(kernel = "gaussian", bw = 0.1) +
ggtitle("Kernel Gaussiano con bw = 0.1")
g2 <- curva_base +
stat_density(kernel = "gaussian", bw = 0.4) +
ggtitle("Kernel Gaussiano con bw = 0.4")
g3 <- curva_base +
stat_density(kernel = "rectangular", bw = 0.1) +
ggtitle("Kernel rectangular con bw = 0.1")
g4 <- curva_base +
stat_density(kernel = "rectangular", bw = 0.4) +
ggtitle("Kernel rectangular con bw = 0.4")
plot_grid(g1, g2, g3, g4, nrow = 2)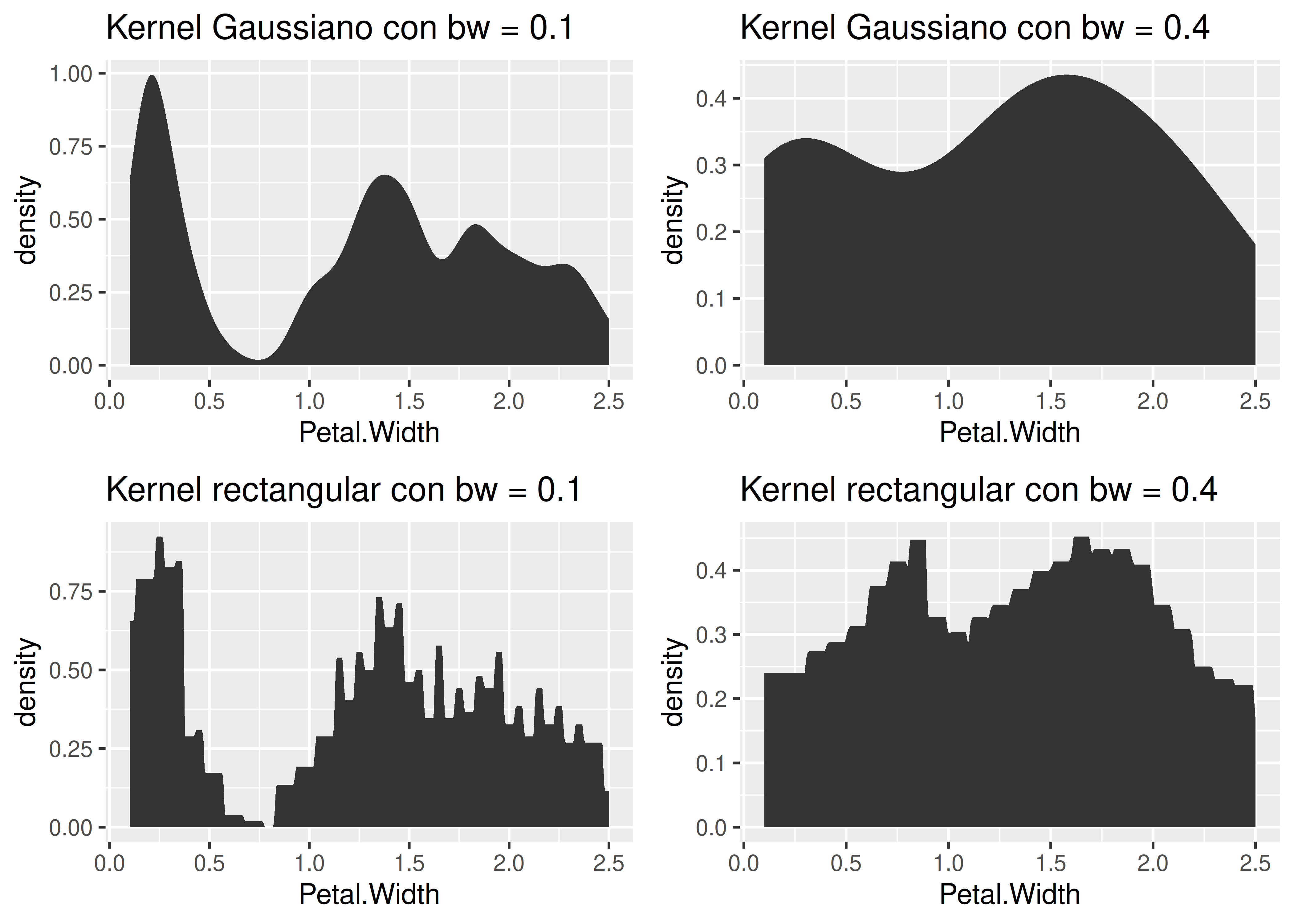
Cálculo “a mano” de la curva de densidad estimada con kernel gaussiano:
h <- 0.1 #ancho de banda
kernel_normal <- function(x, h, datos) {mean(dnorm((x - datos)/h))/h}
kernel_normal <- Vectorize(kernel_normal, vectorize.args = "x")
z <- tibble(
ejex = seq(min(iris$Petal.Width), max(iris$Petal.Width), length.out = 500),
ejey = kernel_normal(ejex, h = h, datos = iris$Petal.Width)
)
ggplot() +
stat_density(aes(x = iris$Petal.Width), bw = h, alpha = 0.5, kernel = "gaussian") +
geom_line(data = z, aes(x = ejex, y = ejey), color = "red", linewidth = 2) +
scale_x_continuous(limits = range(z$ejex))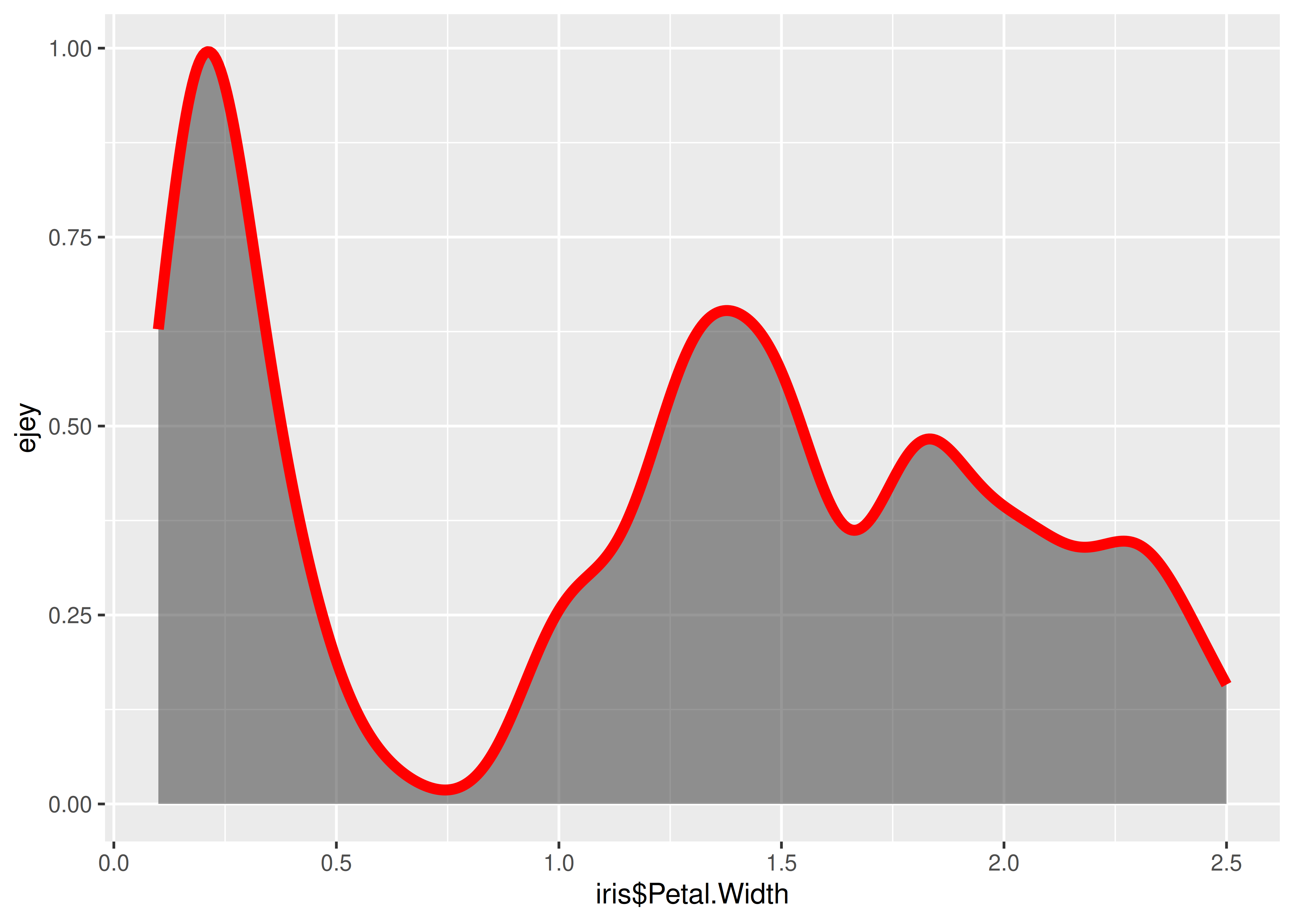
8.3.1 Ridgeline plots
- Estos gráficos surgen ante la necesidad de comparar subgrupos de la misma población mediante múltiples curvas de densidad. Debajo vemos la solución “común” a este problema:
ggplot(data = iris) +
aes(x = Petal.Width, fill = Species, color = Species) +
geom_density(alpha = 0.4)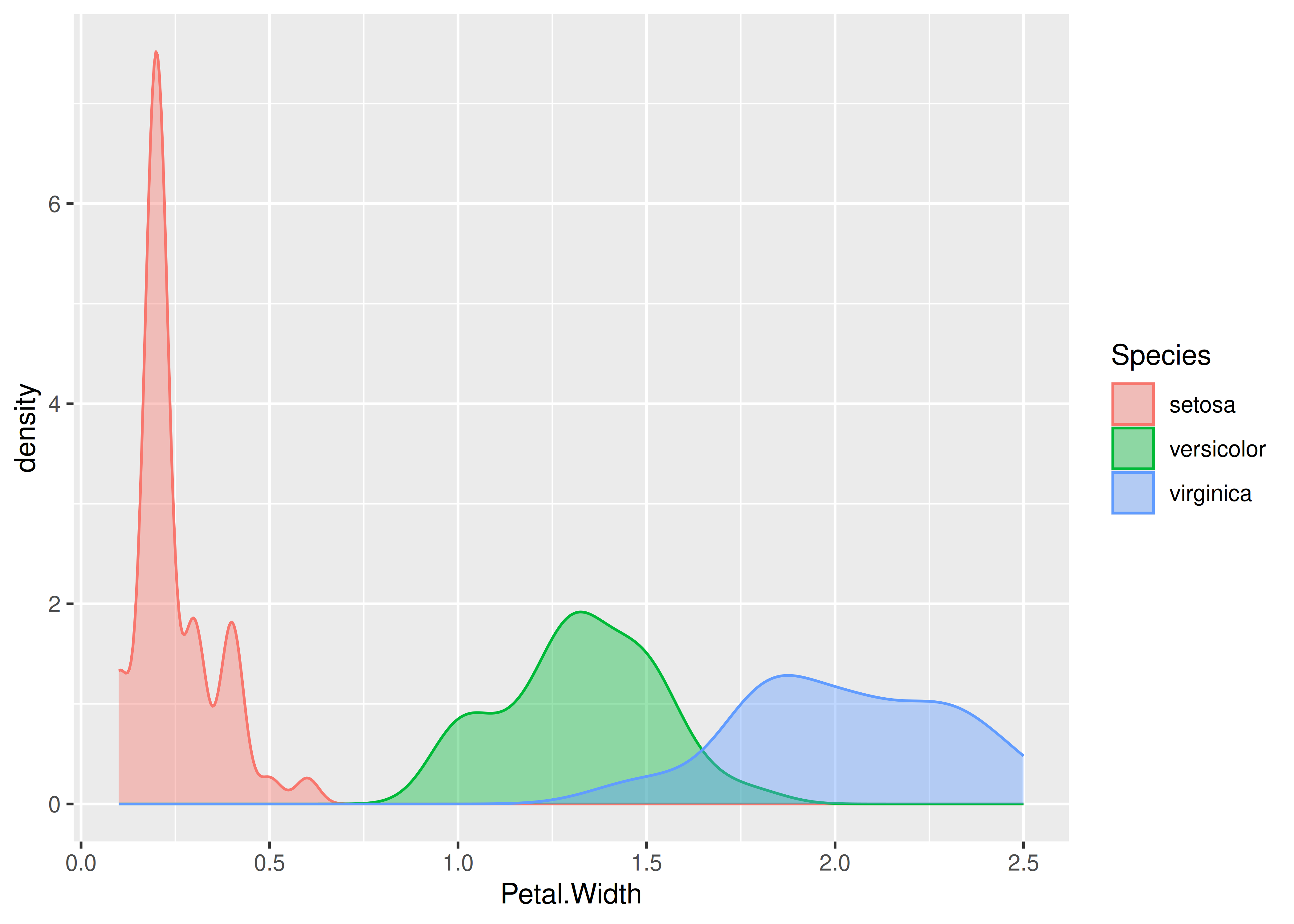
Los ridgeline plots (por ridgeline mountains, crestas o riscos de montañas) constituyen una variante al gráfico presentado arriba, ya que proponen apilar las distintas curvas sobre el eje vertical, en lugar de superponerlas.
Suelen ser particularmente útiles para mostrar tendencias en el tiempo o ante la presencia de muchas distribuciones para comparar.
Dado que el eje horizontal representa la variable continua y el vertical la variable de agrupación, no hay un eje apartado para la densidad. El propósito del gráfico no es mostrar explícitamente los valores de densidad estimados, sino permitir una comparación fácil de las formas y alturas de las densidades.
En R armamos este tipo de visualización mediante la función
geom_density_ridges()del paqueteggridges:
ggplot(data = iris) +
aes(y = Species, x = Petal.Width, fill = Species) +
geom_density_ridges() +
labs(x = "Ancho de Pétalo (cm)", y = "Especie") +
theme_ridges() +
theme(legend.position = "none")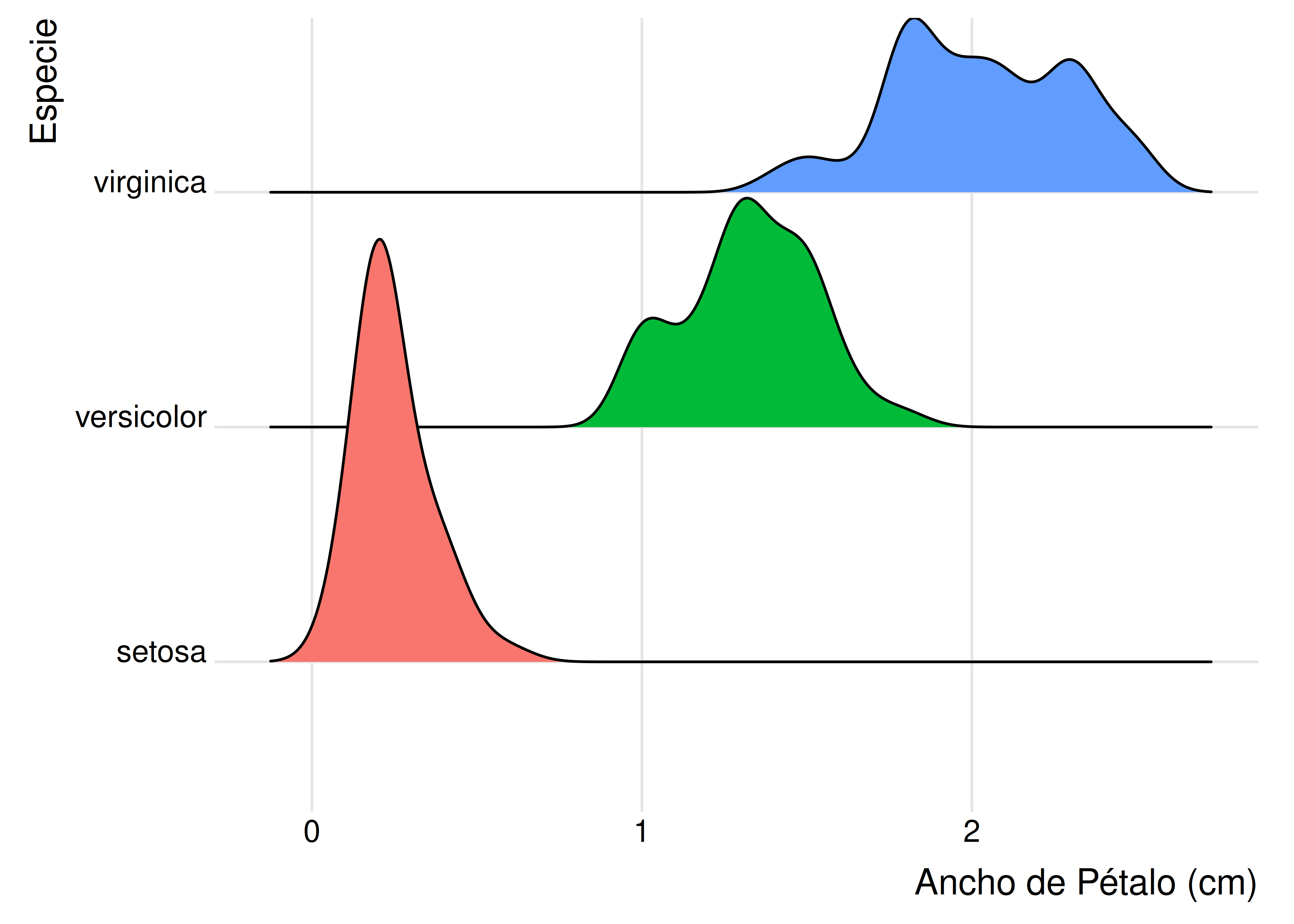
8.3.2 Gráficos de violines
Los gráficos de violines persiguen el mismo objetivo que los boxplots, pero mostrando curvas de densidad estimadas en lugar de cajas. Las curvas se rotan 90 grados y se dibujan en espejo (son simétricas). El aspecto resultante le da el nombre de violín al gráfico.
Su uso se justifica si se tiene una suficiente cantidad de datos como para que la estimación de la densidad sea precisa. Además, pueden mostrar más matices de las distribuciones (por ejemplo bimodalidad) en comparación a lo que se puede lograr mediante un boxplot.
Debajo presentamos dos ejemplos construidos a través de la función
geom_violin()deggplot2: una sin puntos superpuestos y otra con puntos perturbados (jittered):
violin1 <- ggplot(data = iris) +
aes(y = Petal.Width, x = Species, fill = Species) +
geom_violin() +
ggtitle("Gráfico de Violín sin puntos") +
theme(legend.position = "none")
violin2 <- ggplot(data = iris) +
aes(y = Petal.Width, x = Species, fill = Species) +
geom_jitter(width = 0.25, height = 0) +
geom_violin(alpha = 0.4) +
ggtitle("Gráfico de Violín con puntos") +
theme(legend.position = "none")
plot_grid(violin1, violin2)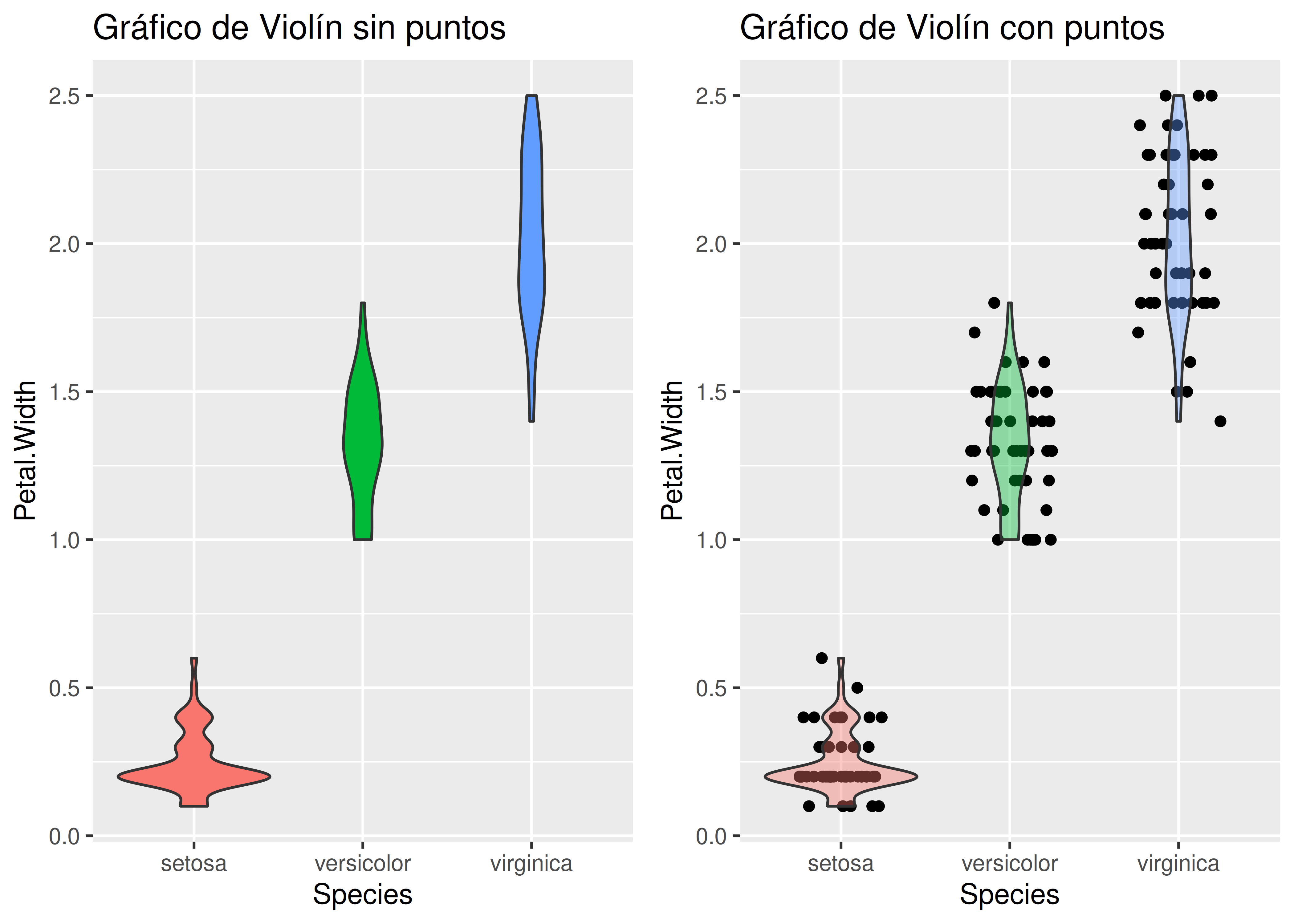
8.4 Diagramas de Caja
Los diagramas de caja (boxplots) fueron inventados por John Tukey a principios de la década del ’70. Ganaron mucha popularidad principalmente debido a dos características:
- Son altamente informativos: podemos enterarnos de la mediana, los cuartiles, la forma, dispersión y asimetría de la distribución, etc.
- Son muy fáciles de graficar a mano, detalle fundamental cuando las computadoras no eran tan populares como ahora.

Elementos que lo componen:
- Mediana: medida de posición central de la distribución (\(Q_2\)).
- Cuartil inferior: \(Q_1\) = cuantil 0.25.
- Cuartil superior: \(Q_3\) = cuantil 0.75.
- Rango intercuartil o intercuartílico \(RI=(Q_3-Q_1)\): medida de dispersión de la distribución. El 50% de los datos se encuentran entre el cuartil inferior y el superior. Un valor de RI pequeño indica homogeneidad alrededor de la mediana, mientras que un valor grande indica heterogeneidad.
- Valor adyacente superior: mayor observación menor o igual a \(Q_3 + 1.5 \times RI\).
- Valor adyacente inferior: menor observación mayor o igual a \(Q_1 - 1.5 \times RI\).
- Valores externos: observaciones más allá de los valores adyacentes (outliers), se grafican en forma individual. Pueden no existir, en cuyo caso los valores adyacentes coinciden con el máximo y mínimo.
Veremos 4 alternativas para graficar boxplots en R:
- Opción 1: versión común.
- Opción 2: se agregan puntos superpuestos con cierto nivel de jitter.
- Opción 3: marca un intervalo de confianza del 95% para la mediana, calculado como \(mediana \pm1.58 \times RI/\sqrt{n}\). Se lo conoce como notched boxplot.
- Opción 4: con ancho (o alto) de caja proporcional al tamaño muestral de cada grupo. Usamos el dataset
mtcarspara apreciar mejor esta característica.
b1 <- ggplot(data = iris) +
aes(x = Petal.Width, y = Species, fill = Species) +
geom_boxplot() +
ggtitle("Opción 1: default") +
theme_bw() +
theme(legend.position = "none")
b2 <- ggplot(data = iris) +
aes(x = Petal.Width, y = Species, fill = Species) +
geom_jitter(width = 0, height = 0.2) +
# Usamos shape NA para que no aparezcan dos veces los outliers
geom_boxplot(outlier.shape = NA, alpha = 0.5) +
ggtitle("Opción 2: con jitter") +
theme_bw() +
theme(legend.position = "none")
b3 <- ggplot(data = iris) +
aes(x = Petal.Width, y = Species, fill = Species) +
geom_boxplot(notch = TRUE) +
ggtitle("Opción 3: notched") +
theme_bw() +
theme(legend.position = "none")
b4 <- ggplot(data = mtcars) +
aes(x = mpg, y = factor(gear), fill = factor(gear)) +
geom_boxplot(varwidth = TRUE) +
ggtitle("Opción 4: proporcional a n") +
theme_bw() +
theme(legend.position = "none")
plot_grid(b1, b2, b3, b4)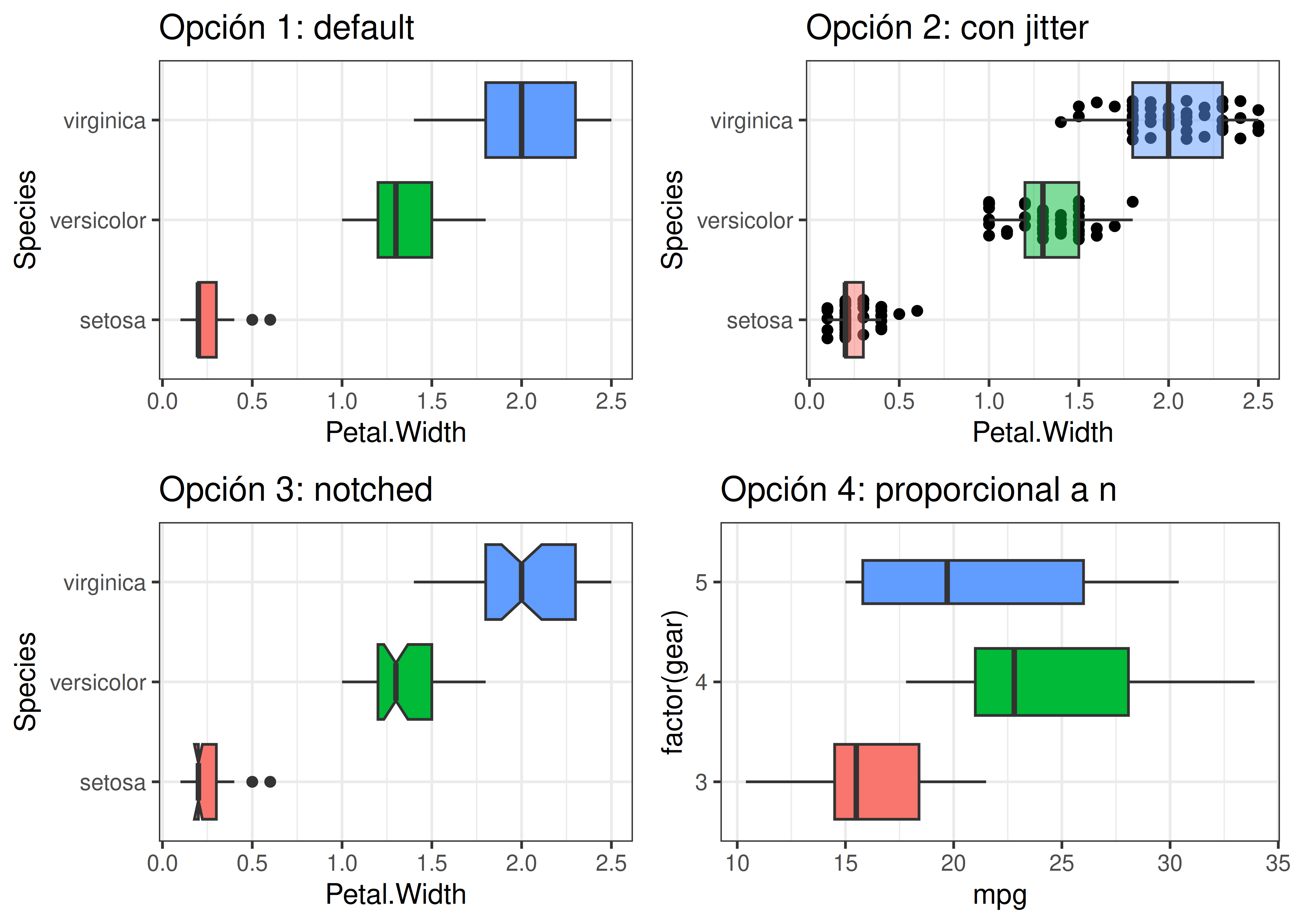
8.5 Gráficos de Cuantiles
- Estos gráficos permiten visualizar la distribución de los datos, entendiendo a la misma como un conjunto de posiciones.
Definición
El cuantil \(f\), llamado \(q(f)\), es el valor tal que aproximadamente una fracción \(f\) del conjunto de datos es menor o igual que \(q(f)\).
Un cuantil estimado a través de los datos es una magnitud aproximada porque puede no existir un valor con una fracción \(f\) de datos menor o igual al mismo.
Para construir los cuantiles \(q(f)\), se ordena a la muestra de menor a mayor obteniendo los valores ascendentes \(x_{(i)}\) para \(i=1,2,...,n\).
Se considera que cada valor ordenado \(x_{(i)}\) es el cuantil \(q(f_i)\) que acumula una fracción igual a:
\[f_i=\dfrac{i-0.5}{n} \]
Si bien esta es la definición más usual, existen alternativas, como por ejemplo \(f_i=i/(n+1)\) o bien \(f_i=i/n\).
Ejemplo: si \(n=50\), el quinto dato ordenado \(x_{(5)}\) es el cuantil \((5-0.5)/ 50 = 0.09\), es decir \(x_{(5)} = q(0.09)\) y consideramos que el 9% de los datos son menores o iguales a \(x_{(5)}\).
Los valores \(f_i\) poseen incrementos de \(1/n\), comenzando por \(0.5/n\), y terminando en \(1-0.5/n\). Si bien definimos \(q(f)\) sólo para los valores de \(f\) que son iguales a los \(f_i\), esto puede extenderse a todos los valores de \(f\) entre \(0\) y \(1\) mediante interpolación y extrapolación lineal.
Una vez que tenemos todos los cuantiles calculados, graficamos \(x_{(i)}\) vs \(f_i\).
Ejemplo con datos simulados a partir de una normal estándar:
set.seed(1974)
z <- rnorm(1000)
ggplot() +
aes(sample = z) +
stat_qq(distribution = qunif, geom = "line")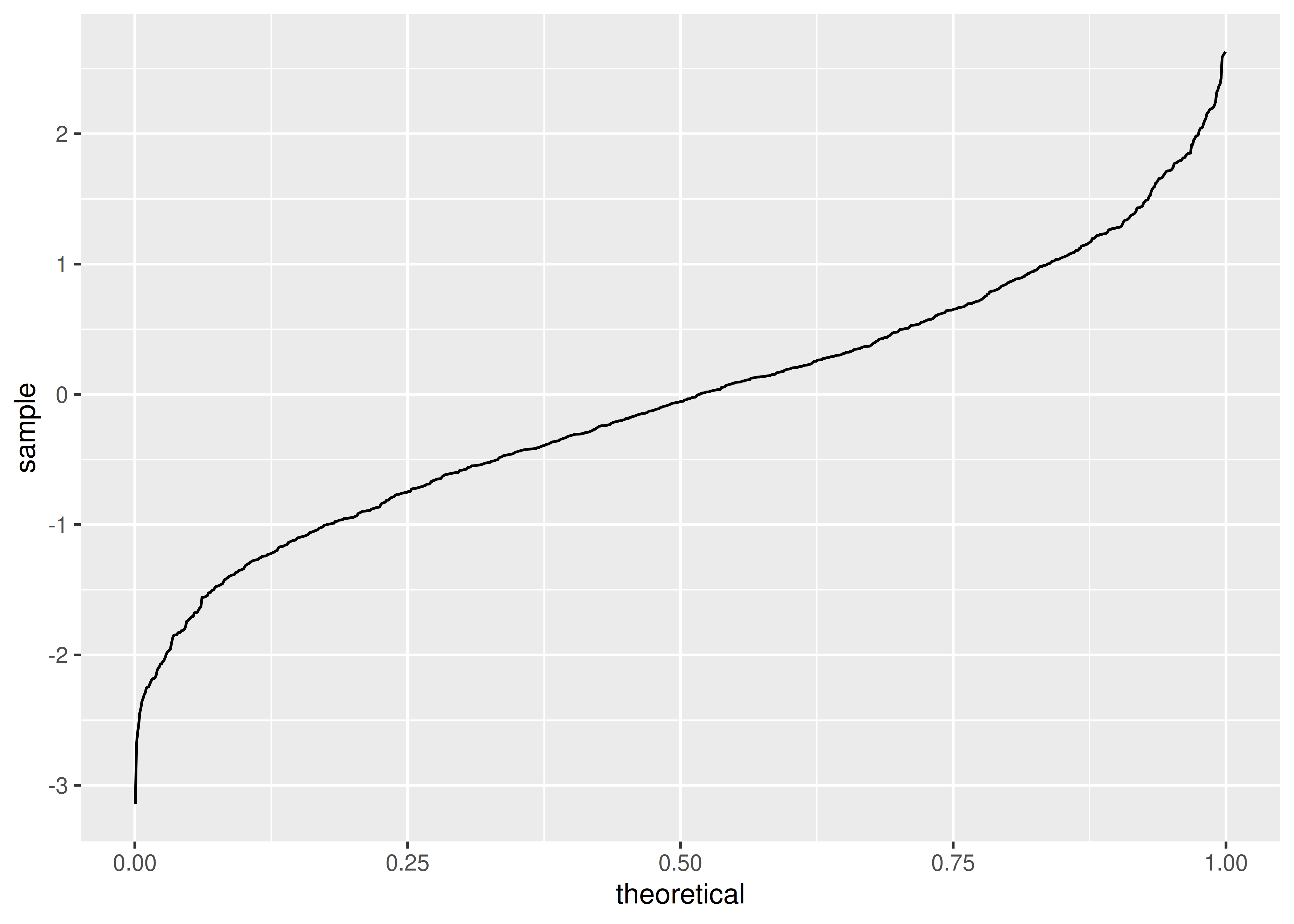
8.6 Datos Multivariados
En la Unidad 1 de la materia vimos cómo agregar una tercera variable a un gráfico de dispersión mediante las estéticas de tamaño (diámetro del punto) o color (paletas con gradientes).
En esta sección mencionaremos algunas alternativas que tenemos a la hora de visualizar más de dos variables numéricas al mismo tiempo.
8.6.1 Dispersión en 3D
Si bien hoy en día existen muchos paquetes de software que facilitan la visualización de datos trivariados, no debe olvidarse que el resultado para nuestra vista es siempre una representación en dos dimensiones, y su interpretación es altamente dependiente del ángulo elegido, Debido a estos detalles, muchos autores no recomiendan su uso.
Pasando por alto esta recomendación, vamos a ver cómo llevar a cabo esta tarea en R mediante el paquete
rgl(dejamos de lado momentáneamente aggplot2ya que no posee la capacidad de renderizar gráficos dinámicos en 3D).Debajo graficamos tres variables numéricas en simultáneo para el conjunto de datos
iris. Además, la especie de cada flor se representa mediante una escala de colores (rojo para setosa, azul para versicolor y verde para virginica):
plot3d(
x = iris$Petal.Width,
y = iris$Petal.Length,
z = iris$Sepal.Width,
col = c(rep("red", 50), rep("blue", 50), rep("green", 50)),
size = 10,
xlab = "Ancho del petalo",
ylab = "Largo del petalo",
zlab = "Ancho del sepalo"
)
rglwidget(width = 600, height = 600)- Una alternativa muy recomendable es Plotly (link a su web oficial), compañía canadiense fundada en 2013 que ofrece herramientas de visualización y data analytics asociadas generalmente a lenguajes de programación como Python o JavaScript.

Entre los muchos productos desarrollados por esta empresa se encuentra el paquete de R que lleva su nombre, orientado a generar visualizaciones dinámicas.
En esta materia ya usamos
plotlyal momento de crear gráficos de tipo treemap. Ahora veamos cómo podemos usarlo para generar un gráfico de dispersión 3D:
plot_ly(
data = iris,
x = ~Petal.Width,
y = ~Petal.Length,
z = ~Sepal.Width,
color = ~Species,
type = "scatter3d",
mode = "markers",
size = I(150),
hoverinfo = "text",
hovertext = paste0(
"<b>Ancho del pétalo: </b>", iris$Petal.Width, "<br>",
"<b>Largo del pétalo: </b>", iris$Petal.Length, "<br>",
"<b>Ancho del sépalo: </b>", iris$Sepal.Width
)
) %>%
layout(
scene = list(
xaxis = list(title = "Ancho del pétalo"),
yaxis = list(title = "Largo del pétalo"),
zaxis = list(title = "Ancho del sépalo")
)
)Si bien este paquete ofrece numerosas posibilidades (ver referencias y galería) no todos tenemos tiempo para aprender a generar gráficos con una nueva sintaxis, lo que implicaría acostumbrarse a escribir nuevas estructuras, funciones, argumentos, opciones, etc.
Por suerte para nosotros,
plotlypuede integrarse conggplot2de manera muy simple a través de la funciónggplotly():
grafico <- ggplot(data = iris) +
aes(x = Petal.Width, y = Petal.Length, color = Species) +
geom_point()
ggplotly(grafico)8.6.2 Coplots
Si no queremos depender de una visualización interactiva en 3D, una alternativa son los denominados coplots (conditioning plots).
Este tipo de gráficos asigna el rol de “condicionante” a una de las tres variables en estudio, graficando la relación entre las dos restantes para subconjuntos de la población en diferentes paneles.
En R podemos armar estos gráficos mediante la función
gg_coplot()del paqueteggcleveland(Prunello & Marí, 2021).Veamos un coplot para analizar la relación entre ancho y largo del pétalo, condicionada a los valores de ancho de sépalo:
gg_coplot(
df = iris,
x = Petal.Width,
y = Petal.Length,
faceting = Sepal.Width,
number_bins = 6,
overlap = 1/2,
xlabel = "Ancho del pétalo",
ylabel = "Largo del pétalo",
facet_label = "Ancho del sépalo",
loess_degree = 2
)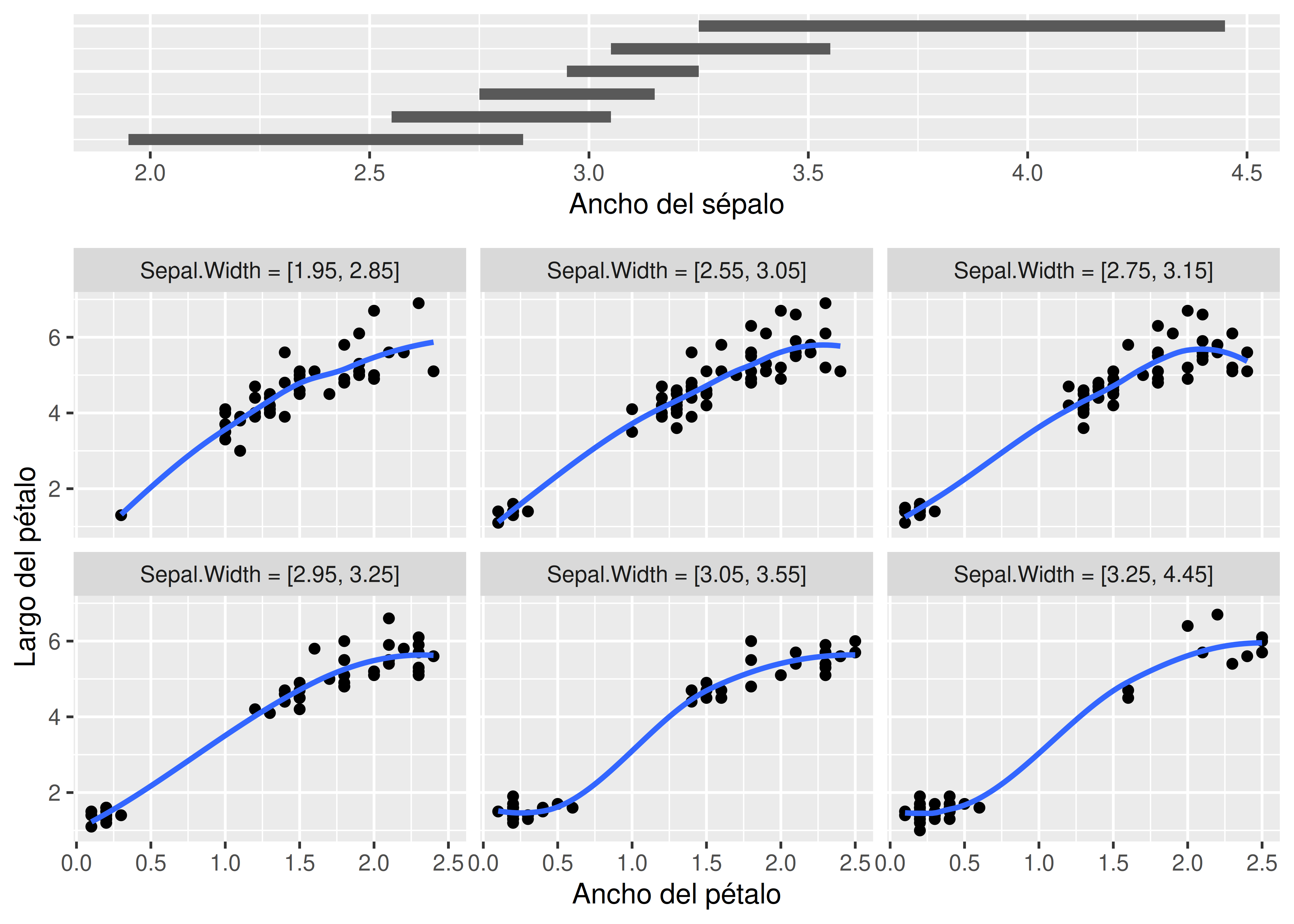
En este tipo de visualizaciones es común agregar una curva mediante ajuste LOESS para verificar si la relación entre las 2 variables graficadas es homogénea a lo largo de los diferentes intervalos de la “condicionante”.
En un coplot los intervalos empleados para condicionar los paneles se solapan, lo cual implica que un mismo individuo aparece en más de un panel. Para definir la longitud de cada intervalo deben tenerse en cuenta dos criterios:
Cantidad de puntos: la amplitud de los intervalos debe ser tal que los paneles dependientes posean suficientes puntos para visualizar la relación existente.
Resolución: la amplitud debe ser lo suficientemente pequeña para mantener una resolución razonable. Si el intervalo condicionante es muy grande, existe el riesgo de una visualización distorsionada cuando la naturaleza de la dependencia cambia dramáticamente a medida que crecen los valores de la variable condicionante.
8.6.3 Paquete gganimate
gganimatees una extensión deggplot2que ofrece herramientas para crear gráficos animados a partir de objetos ggplot. Este paquete es útil cuando queremos representar en un mismo gráfico diferentes períodos temporales, o bien destacar las diferencias entre distintos grupos de individuos.

- Veamos un ejemplo donde el objetivo es analizar la evolución a través de los años del PBI (gdpPercap) per cápita y la esperanza de vida (lifeExp) de varios países según continente, tomando datos del paquete
gapminder:
head(gapminder)# A tibble: 6 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.
6 Afghanistan Asia 1977 38.4 14880372 786.
Vamos a tomar el año como variable de transición, utilizando funciones de
gganimatepara construir un gráfico animado.Los pasos a seguir para generar la animación en formato gif son:
- Crear un gráfico de manera común y corriente con
ggplot2. - Agregar una capa extra con alguna de las funciones transition de
gganimate, las cuales crean un gráfico diferente para cada valor de la variable de transición establecida. - Generar un objeto “animado” mediante la función
animate(), eligiendo la cantidad de fotogramas. - Guardar el objeto animado en un archivo en nuestra PC, con formato gif, utilizando la función
anim_save().
- Crear un gráfico de manera común y corriente con
Paso 1: gráfico básico
- En este gráfico cada país está representado por un punto de un determinado color, cuyo diámetro depende de la cantidad de habitantes. Se observa una posible relación positiva entre PBI per cápita y esperanza de vida:
pbi_esp <- ggplot(data = gapminder) +
aes(x = log(gdpPercap), y = lifeExp, size = pop, colour = country) +
geom_point(alpha = 0.7, show.legend = FALSE) +
scale_colour_manual(values = country_colors) +
scale_size(range = c(2, 12)) +
labs(x = 'Logaritmo del PBI per Cápita',
y = 'Esperanza de Vida (en años)') +
theme_bw() +
theme(axis.title = element_text(face = "bold"))
pbi_esp + facet_wrap(~year)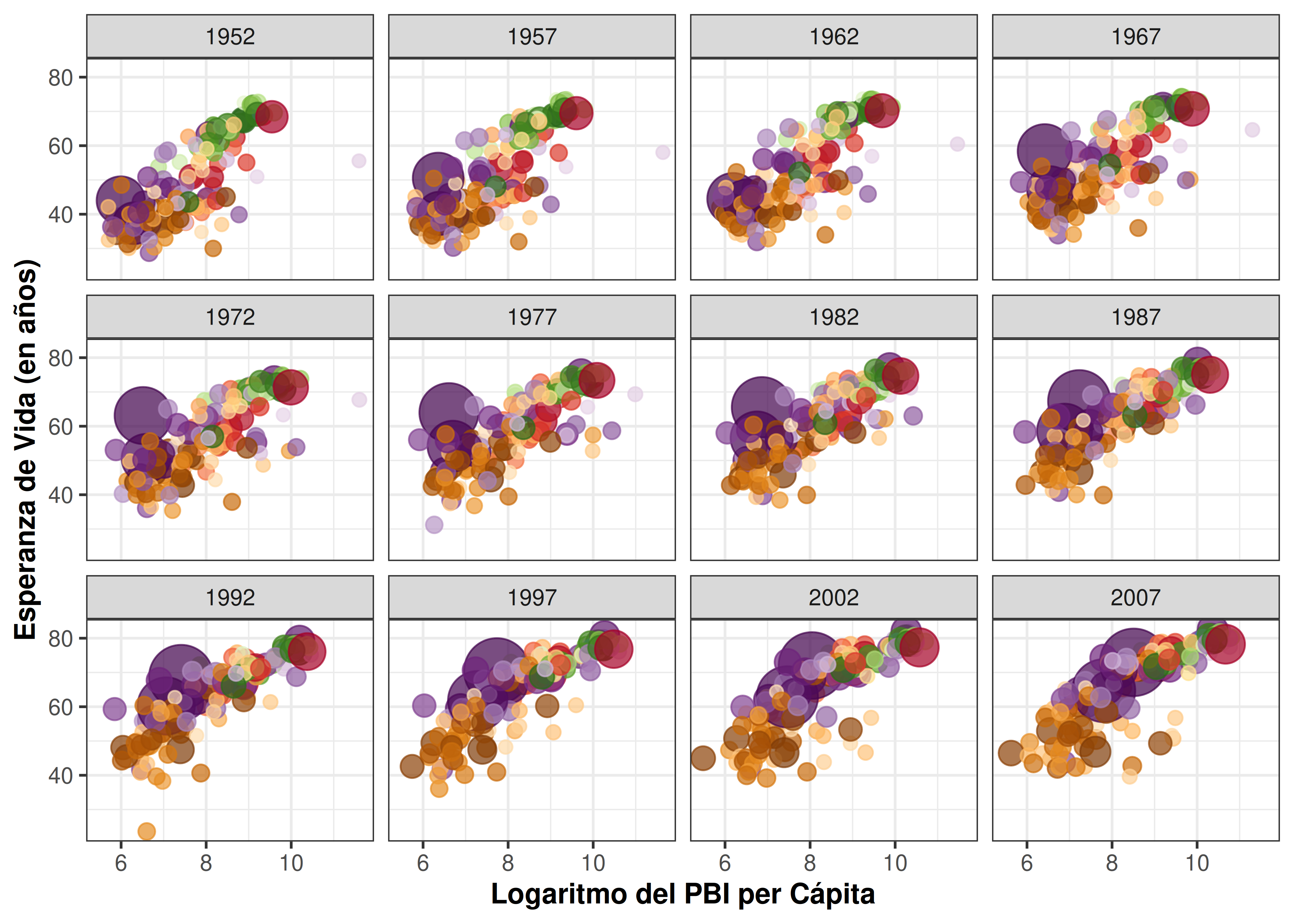
Paso 2: transición animada
- Intercambiamos la capa de paneles por una de transición animada y agregamos un título dinámico:
pbi_esp_animado <- pbi_esp +
transition_time(year) + #Variable de transición
ease_aes("linear") + #Tipo de transición
ggtitle("Año: {frame_time}") #Título dinámico
pbi_esp_animado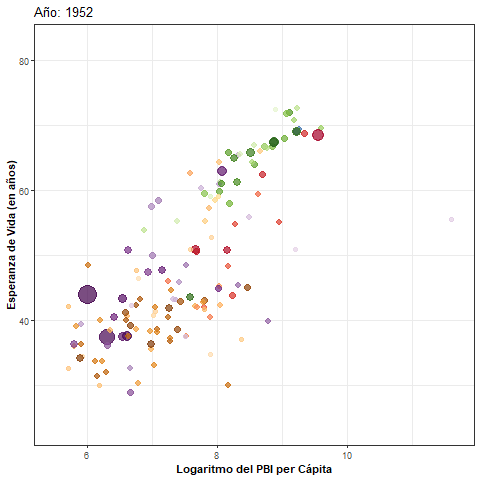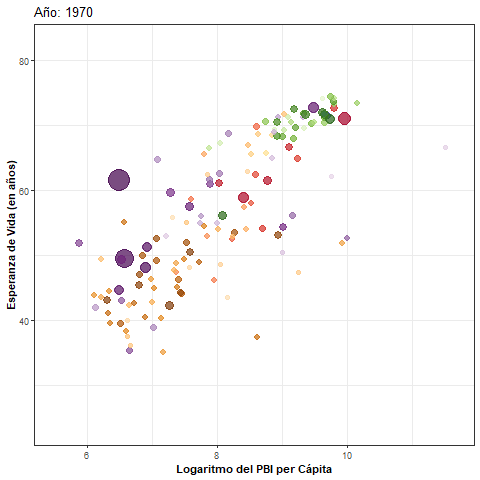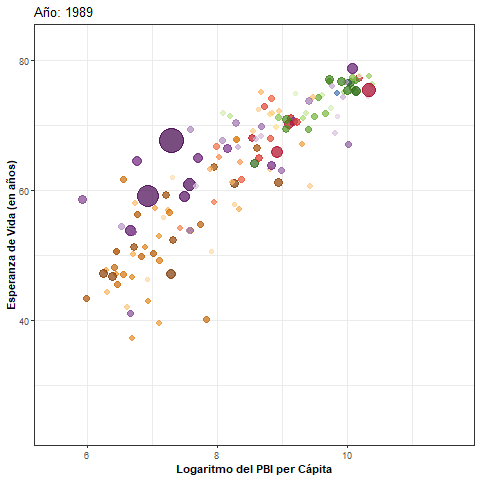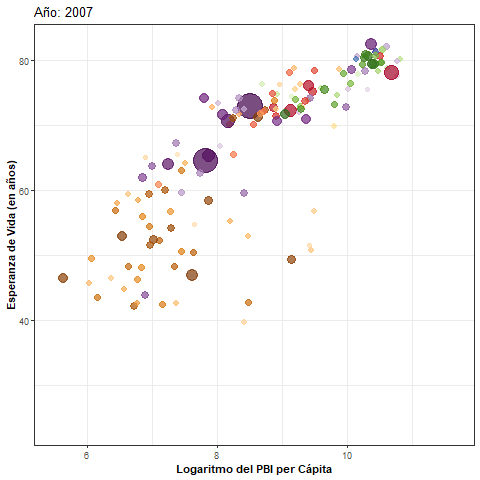
8.6.3.1 Paso 3: función animate()
- Antes de guardar la animación en un objeto de R, dividimos el gráfico anterior en paneles según continente. Luego, usamos la función
animate()para especificar opciones referidas a la generación del gif, en este caso, la cantidad de frames (fotogramas):
pbi_esp_ok <- pbi_esp_animado + facet_wrap(~continent)
animacion <- animate(
plot = pbi_esp_ok,
renderer = gifski_renderer(),
nframes = 50 # Cantidad de fotogramas
)Paso 4: exportación del gif
- Por último, mediante la función
anim_save()exportamos a nuestra PC un archivo con la animación generada:
# Guardamos la animación en un archivo formato gif
anim_save(filename = "Gapminder.gif", animation = animacion)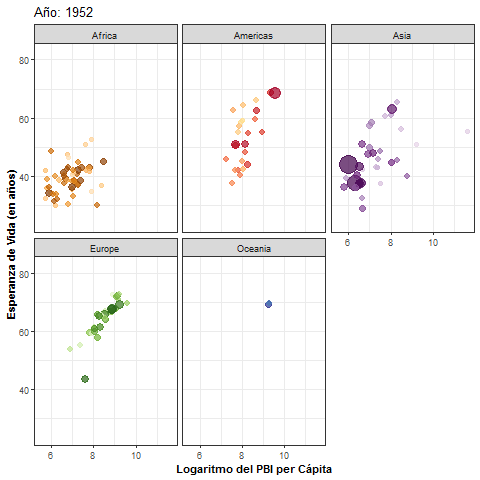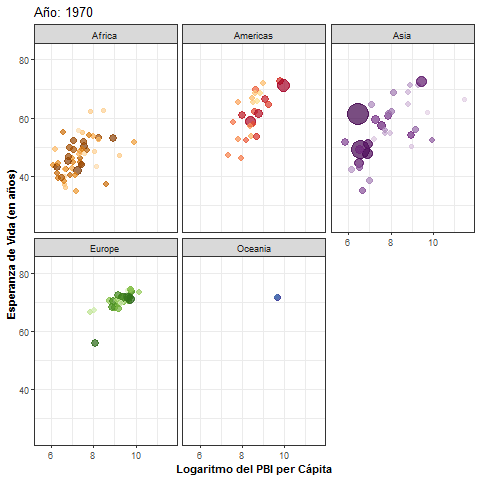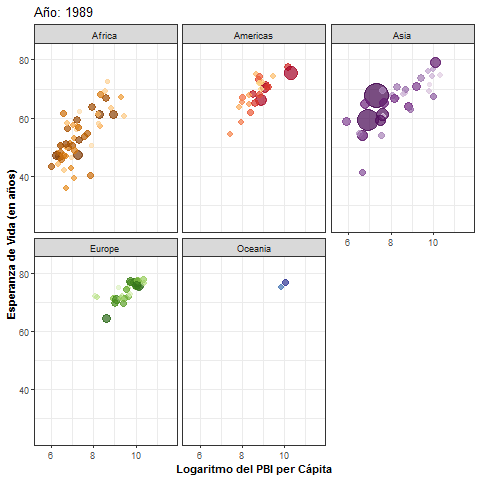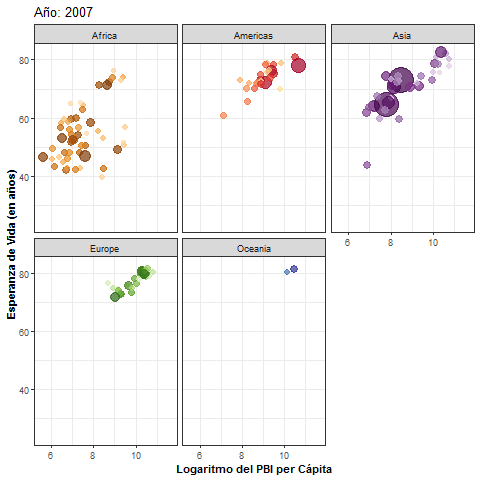
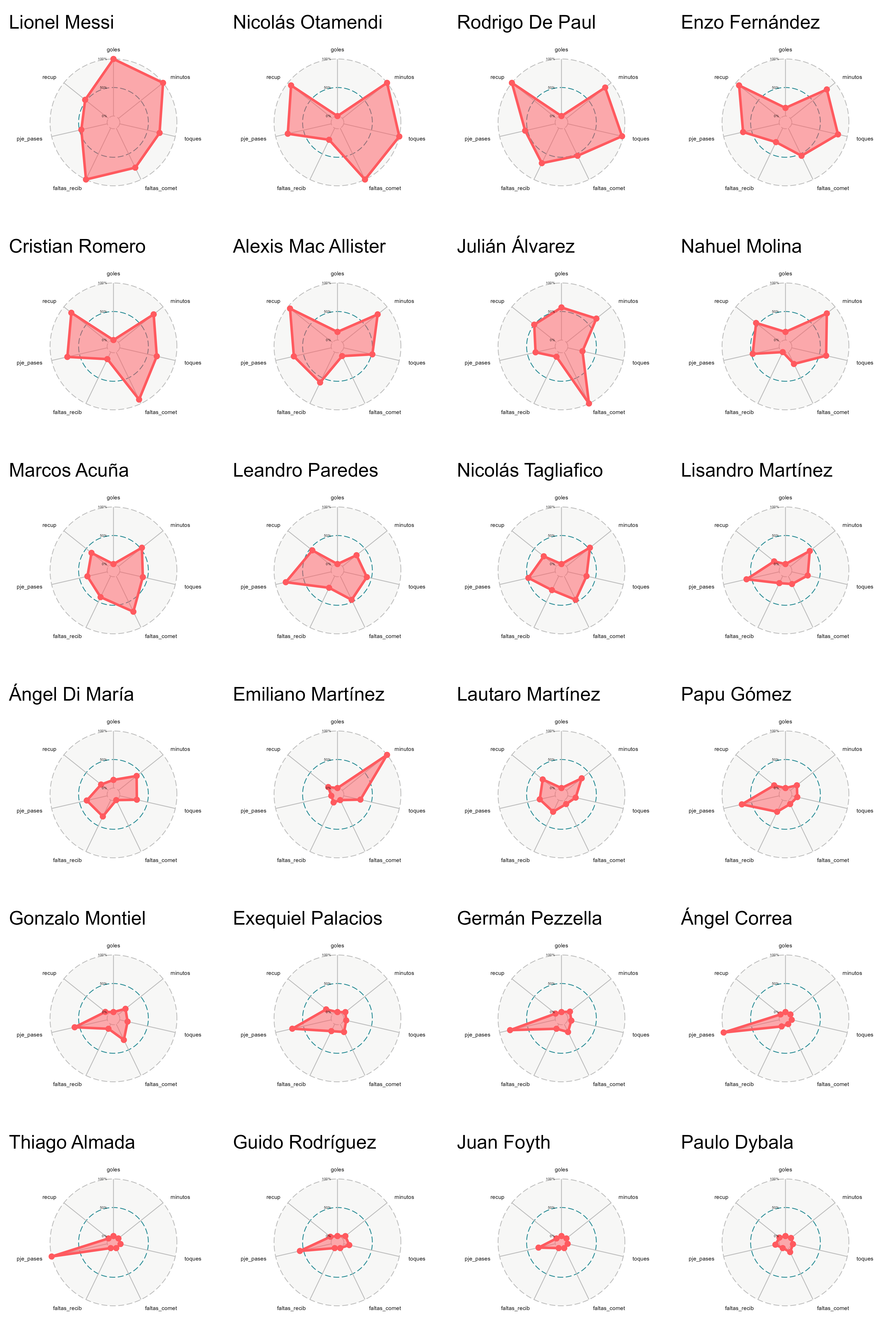
8.7 Radar Chart
Los radar charts, también conocidos como spider charts, son una manera de visualizar múltiples variables cuantitativas medidas a un mismo individuo utilizando un único gráfico, cuya forma es circular.
En teoría, permiten comparar individuos de un solo vistazo a través de varios indicadores numéricos. Veamos un ejemplo donde se grafican las calificaciones de dos estudiantes en diversas materias (tomado de la excelente web https://www.data-to-viz.com/):
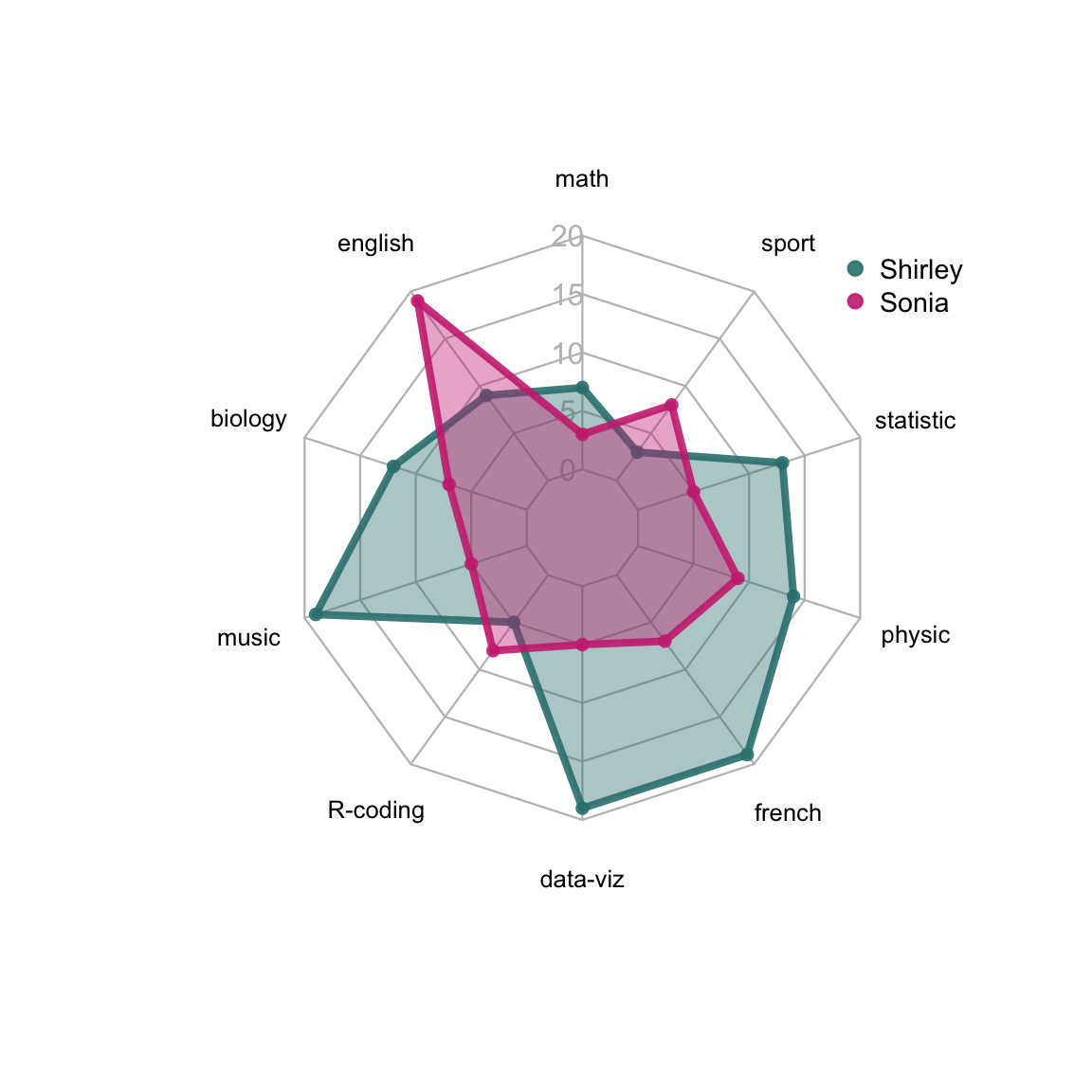
Al igual que los gráficos en 3D, este tipo de visualizaciones reciben varias críticas por parte de los expertos. Sus principales desventajas son:
- Las cantidades son complejas de “medir” a simple vista dada la confección circular del gráfico (siempre lo lineal es más fácil).
- El orden asignado a las variables posee un gran impacto sobre la apariencia final del gráfico.
- El escalamiento necesario que se aplica sobre todas las variables para estandarizar rangos de amplitud puede distorsionar algunas diferencias.
- No cumplen con el principio de tinta proporcional. Por ejemplo, un individuo con un score de 2 en todas sus variables debería tener un área igual al doble que la de un individuo con score de 1 en todas sus variables; sin embargo, esto no ocurre, ya que las áreas aumentan cuadráticamente.
Otras críticas a estos gráficos pueden encontrarse en este enlace. A pesar de todo esto, su popularidad ha ido en aumento, en parte gracias a su presencia en diversos videojuegos de fútbol (PES, FIFA, etc.).
8.7.1 Datos: Mundial de Qatar 2022
Para homenajear a los juegos que han hecho populares este tipo de gráficos, vamos a trabajar con un conjunto de datos que posee información sobre todos los jugadores que participaron en el Mundial de Qatar 2022. En este link hay más detalles sobre el origen de la base.
Los datos se encuentran almacenados en formato .csv, dentro del archivo llamado
fifa2022. Las variables disponibles son:player: nombre del jugador.position: posición más habitual en la que juega (GK: arqueros, DF: defensores, MF: mediocampistas, FW: delanteros).team: selección.age: edad del jugador al inicio de la temporada.minutes_90s: total de minutos jugados durante el Mundial, dividido 90 (da idea de cuántos partidos completos jugó).cards_red: cantidad de tarjetas rojas recibidas.cards_yellow: cantidad de tarjetas amarillas recibidas.fouls: faltas cometidas.fouled: faltas recibidas.ball_recoveries: cantidad pelotas recuperadas.goals: goles convertidos.games: partidos jugados.minutes_pct: porcentaje de minutos jugados (minutos jugados dividido el total de minutos que jugó su selección en todo el mundial).passes_pct: porcentaje de pases completados.touches: número de veces que el jugador tocó la pelota.continent: continente al que pertenece la selección.ronda: indica hasta qué ronda llegó la selección a la que pertenece cada jugador.amarillas: toma el valor “si” si el jugador tuvo tarjetas amarillas o “no” en caso contrario.
Cargamos los datos y vemos un resumen de sus variables:
mundial <- read_csv("../data/unidad04/fifa2022.csv")
glimpse(mundial)Rows: 680
Columns: 18
$ player <chr> "Aaron Mooy", "Aaron Ramsey", "Abdelhamid Sabiri", "Ab…
$ position <chr> "MF", "MF", "MF", "DF", "FW", "FW", "DF", "FW", "MF", …
$ team <chr> "Australia", "Wales", "Morocco", "Qatar", "Morocco", "…
$ age <dbl> 32.26, 31.98, 26.05, 29.31, 32.00, 21.00, 26.62, 18.78…
$ minutes_90s <dbl> 4.0, 3.0, 2.0, 3.0, 0.8, 1.0, 3.7, 0.0, 2.2, 2.0, 1.9,…
$ cards_red <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ cards_yellow <dbl> 1, 1, 1, 0, 0, 0, 0, 0, 0, 2, 2, 1, 0, 1, 1, 0, 1, 0, …
$ fouls <dbl> 4, 3, 2, 1, 3, 4, 3, 0, 4, 3, 8, 1, 0, 1, 2, 6, 10, 0,…
$ fouled <dbl> 1, 3, 3, 4, 2, 0, 0, 0, 1, 3, 4, 0, 0, 4, 1, 13, 4, 1,…
$ ball_recoveries <dbl> 35, 19, 7, 11, 4, 4, 17, 0, 4, 15, 9, 2, 1, 3, 10, 46,…
$ goals <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, …
$ games <dbl> 4, 3, 5, 3, 4, 3, 4, 1, 3, 3, 2, 1, 2, 1, 3, 7, 6, 1, …
$ minutes_pct <dbl> 100.0, 98.5, 27.4, 100.0, 10.3, 14.1, 91.9, 0.4, 72.6,…
$ passes_pct <dbl> 78.3, 78.6, 77.6, 75.8, 53.3, 76.9, 74.7, 100.0, 79.1,…
$ touches <dbl> 255, 147, 86, 193, 28, 40, 210, 2, 98, 129, 105, 19, 2…
$ continent <chr> "Oceania", "Europe", "Africa", "Asia", "Africa", "Afri…
$ ronda <chr> "octavos de final", "fase de grupos", "final o tercer …
$ amarillas <chr> "si", "si", "si", "no", "no", "no", "no", "no", "no", …8.7.2 Aplicación en R
Dado que hay 680 jugadores en la base, vamos a limitarnos a trabajar con los de la Selección Argentina.
El preprocesamiento de la base incluye también un paso de re-escalamiento, en el cual convertimos todas las variables numéricas a una nueva escala, donde el mínimo valor observado pasa a ser 0 y el máximo pasa a ser 1.
Para esta conversión usamos la función
rescale()del paquetescales:
argentina <- mundial %>%
filter(team == "Argentina") %>%
select(
group = player, #necesario para la funcion ggradar
goles = goals,
minutos = minutes_90s,
toques = touches,
faltas_comet = fouls,
faltas_recib = fouled,
pje_pases = passes_pct,
recup = ball_recoveries
) %>%
mutate_if(is.numeric, rescale)- El gráfico en sí mismo lo construimos a través del paquete
ggradar, una extensión deggplot2que debe instalarse desde su propio repositorio de GitHub:
devtools::install_github("ricardo-bion/ggradar", dependencies = TRUE)- Una vez hecho esto, conseguir el gráfico es relativamente fácil. Veamos un ejemplo para comparar a Lionel Messi con Rodrigo De Paul:
messi <- ggradar(
plot.data = filter(argentina, group == "Lionel Messi"),
plot.title = "Lionel Messi",
fill = TRUE,
axis.label.size = 2.5,
grid.label.size = 2,
group.point.size = 3
)
depaul <- ggradar(
plot.data = filter(argentina, group == "Rodrigo De Paul"),
plot.title = "Rodrigo De Paul",
fill = TRUE,
axis.label.size = 2.5,
grid.label.size = 2,
group.point.size = 3
)
plot_grid(messi, depaul)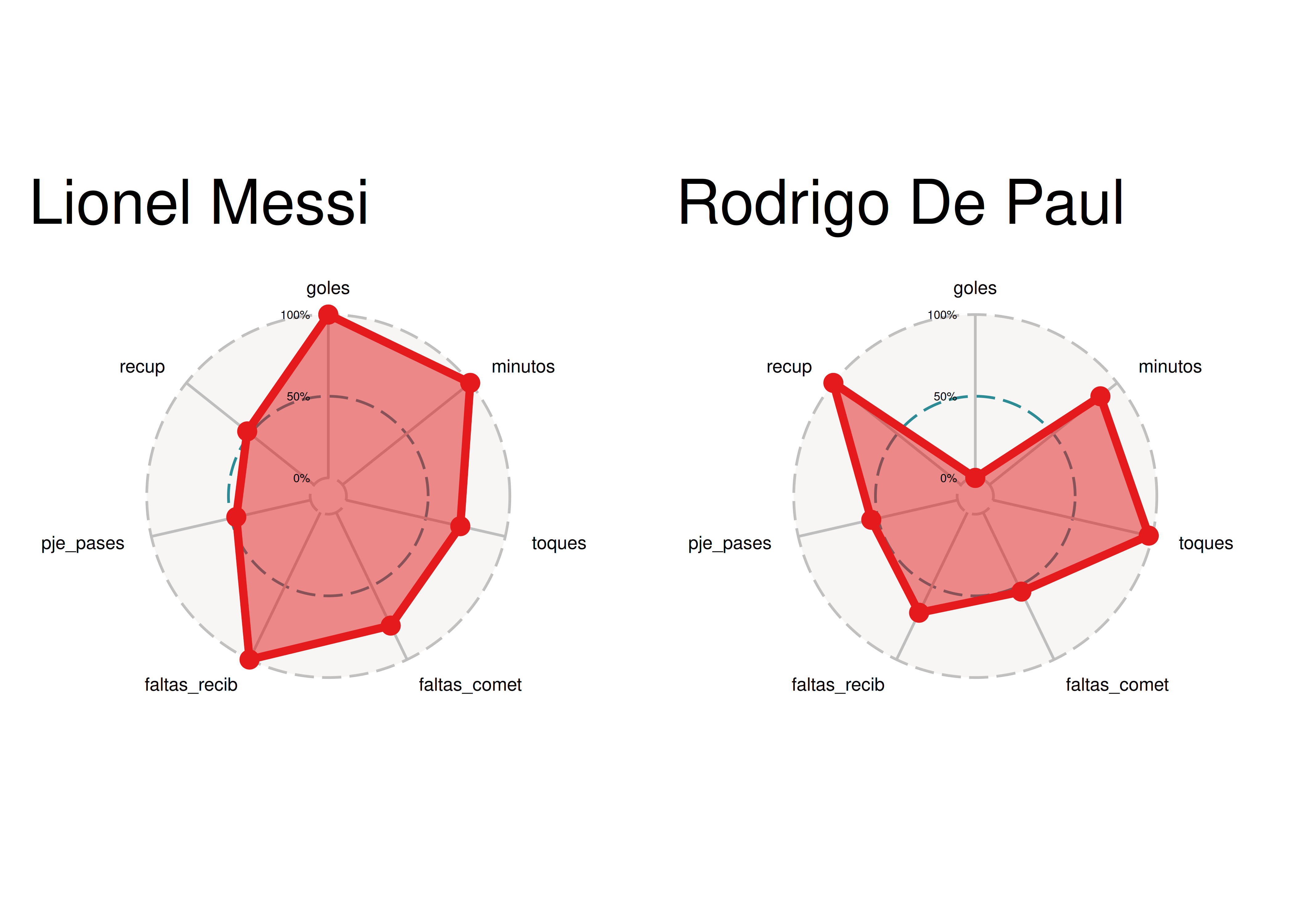
- Debajo vemos un gráfico con la comparación de los 24 jugadores que sumaron minutos durante el Mundial:
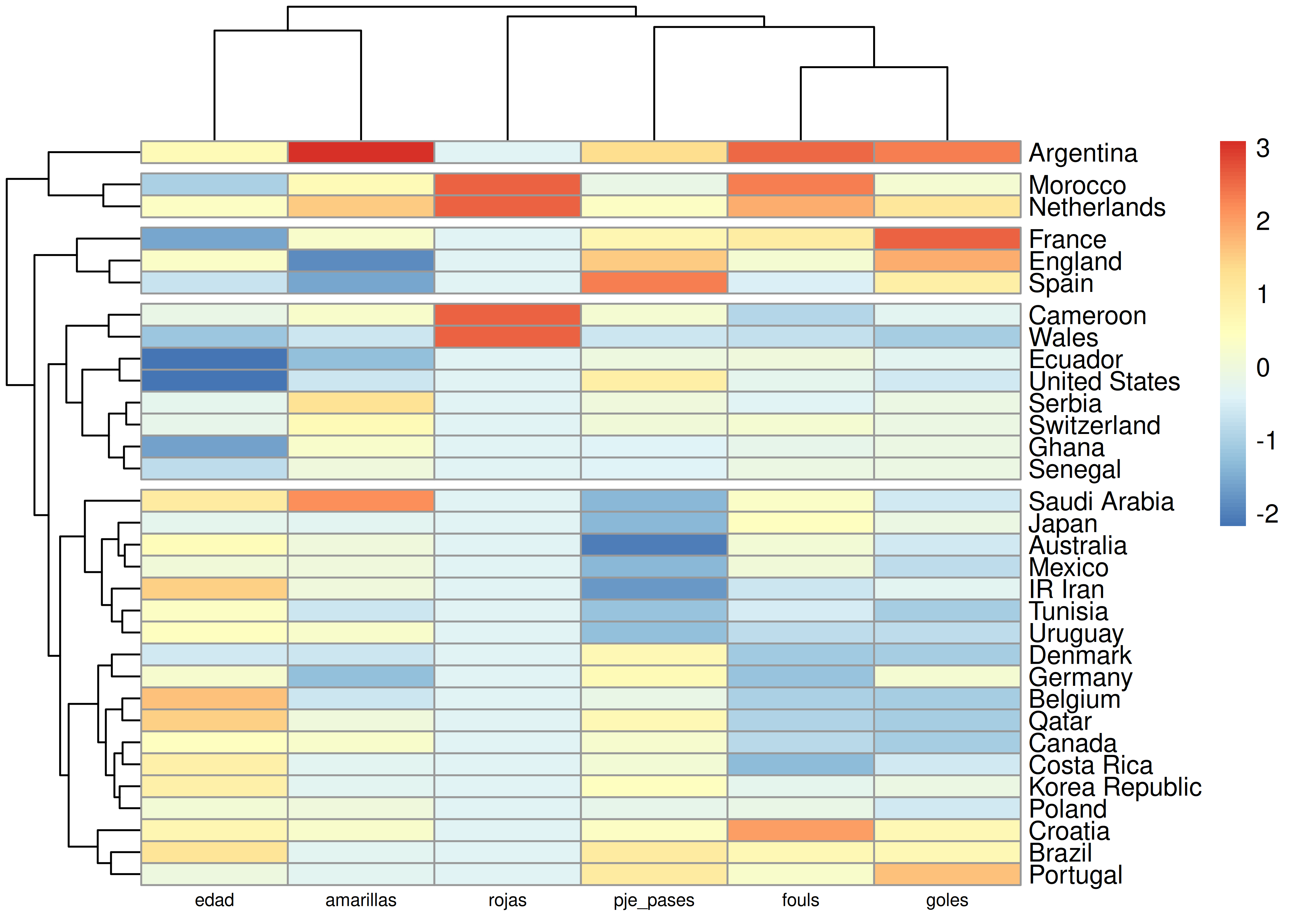
8.8 Mapas de Calor
Como alternativa a los radar charts, presentamos los conocidos mapas de calor o heatmaps.
Este tipo de visualización sirve para representar una matriz de datos numéricos, reemplazando cada valor por una celda pintada con un color, el cual indica la magnitud de la observación correspondiente.
Aunque este tipo de gráfico no deja apreciar fácilmente los valores exactos que se muestran, hace un excelente trabajo al resaltar tendencias generales.
Debajo vemos un heatmap para los jugadores de la Selección Argentina, a través del cual podemos visualizar su rendimiento durante el Mundial de Qatar 2022:
argentina %>%
pivot_longer(-group) %>%
group_by(name) %>%
mutate(value = (value - mean(value)) / sd(value)) %>%
ungroup() %>%
ggplot() +
aes(x = name, y = group, fill = value) +
geom_tile(colour = "white") +
scale_fill_gradient2(low = "darkblue", mid = "white", high = "red") +
labs(x = "Variable", y = "Jugador")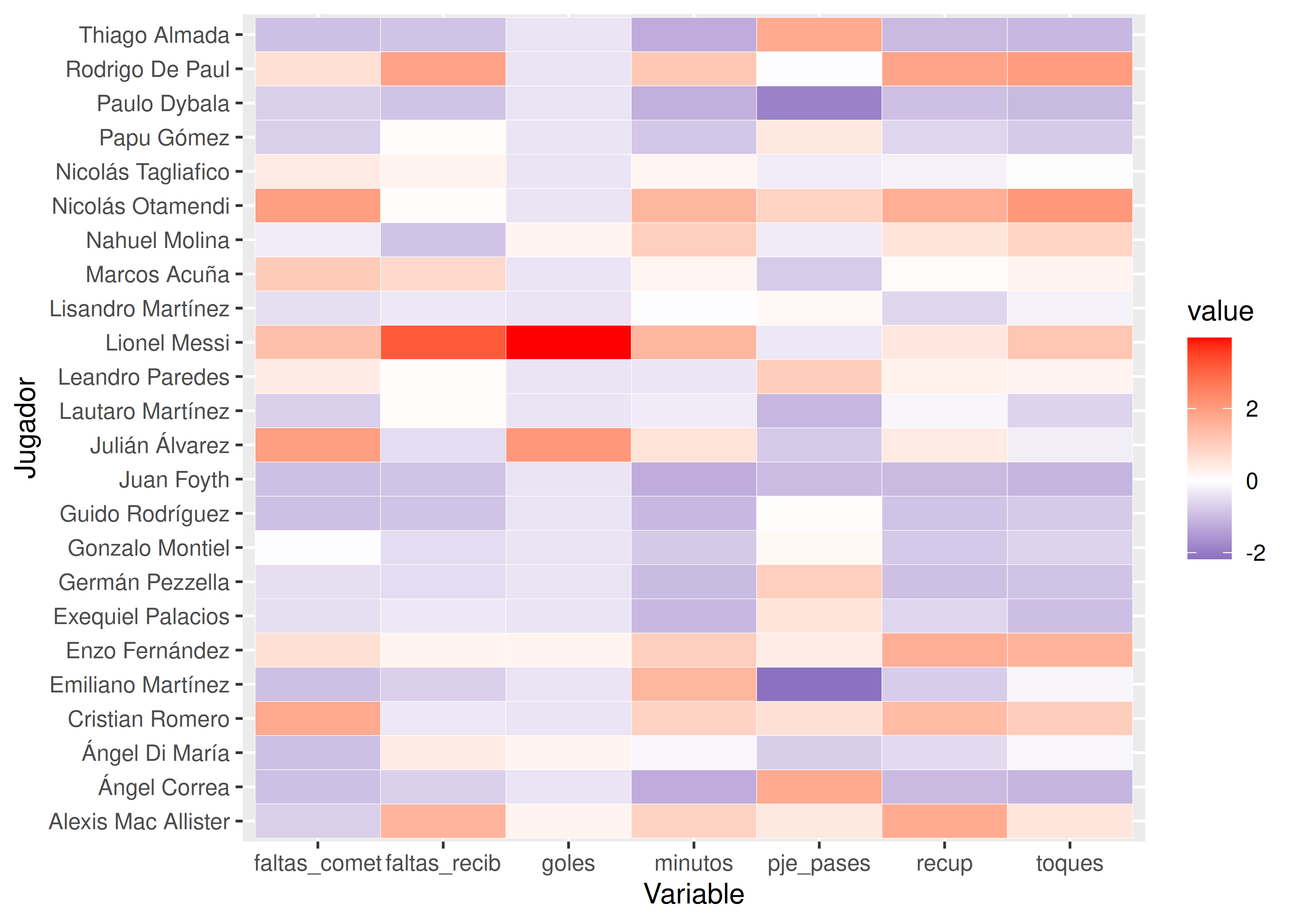
Observaciones: generalmente en las columnas se presentan las variables de interés y en las filas los individuos. Los datos se estandarizan previamente para homogeneizar rangos de variación entre diferentes variables.
Un tipo de heatmap más complejo surge cuando agregamos técnicas de análisis por conglomerados. En este caso se reordenan filas y columnas de acuerdo al resultado de algún proceso de clusterización, para mostrar grupos de individuos y/o variables con patrones similares.
En particular, si el agrupamiento surge de un análisis de conglomerados jerárquicos, suelen agregarse los dendrogramas a la figura.
Veamos un ejemplo con el paquete
pheatmap, para el cual definimos de antemano 4 clusters (conglomerados) de jugadores:
matriz <- argentina %>% select(-group) %>% as.matrix() %>% scale()
rownames(matriz) <- argentina$group
pheatmap(matriz, cutree_rows = 4, angle_col = 0, fontsize_col = 7)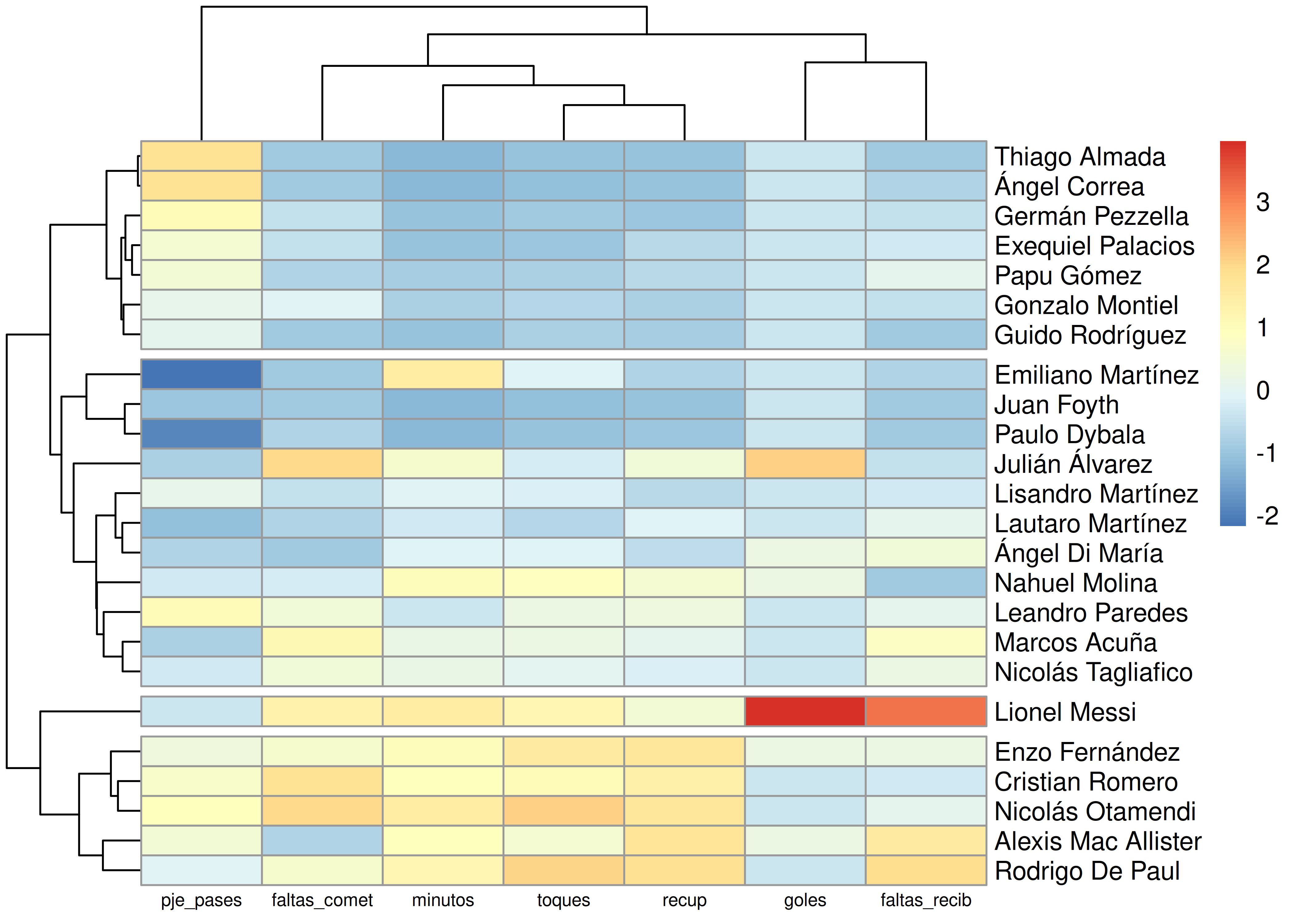
Intentamos algunas interpretaciones de los clusters conformados por este método:
- Cluster 1: jugadores con pocos minutos disputados durante el Mundial, en general poseen un porcentaje medio/alto de pases acertados.
- Cluster 2: es el más extenso de los 4. Si bien no posee una identidad clara, abarca jugadores con niveles medio/bajos de cantidad de toques y recuperaciones.
- Cluster 3: Lionel Messi. Único en su especie, es por lejos quien más goles hizo y a quien mayor cantidad de faltas le cometieron. También posee niveles altos de cantidad de toques y minutos jugados.
- Cluster 4: el corazón del equipo, está conformado por los 3 volantes titulares (Enzo, Alexis y De Paul) más la pareja de marcadores centrales (Romero y Otamendi). Es el cluster “rústico”, con mayor cantidad de faltas cometidas y alto nivel de recuperaciones.
Si bien las interpretaciones de los cluster obtenidos pueden ser algo sesgadas o subjetivas, esta técnica es útil para descubrir perfiles de individuos similares entre sí, con respecto a las variables incluidas en el análisis.
8.8.1 Matrices de Correlación
Otro uso común de los heatmaps ocurre cuando queremos visualizar matrices de correlación calculadas a partir de bases con alto valor de \(p\) (muchas variables).
En estos casos el paquete
corrplotpermite realizar mapas de calor muy útiles para describir de manera visual la información guardada en este tipo de matrices, al reemplazar los valores numéricos por una escala de colores.El paquete ofrece una gran cantidad de variantes para la visualización. Veremos solo algunas, usando nuevamente los datos
mtcars:
Caso 1: tamaño del círculo proporcional a la correlación
matriz_corr <- cor(mtcars)
corrplot(matriz_corr)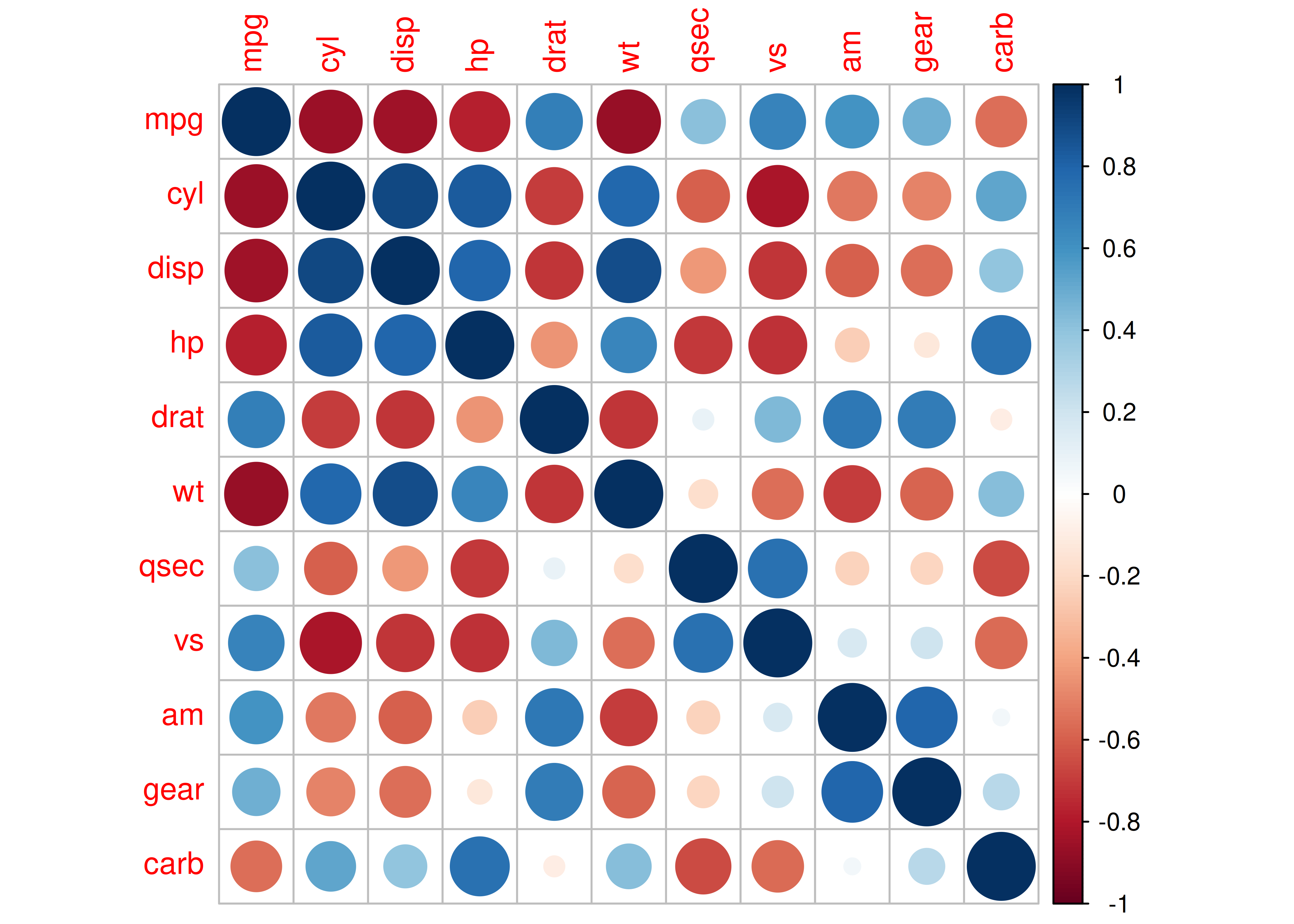
Caso 2: ángulo de la elipse según tipo de relación
corrplot(matriz_corr, method = "ellipse")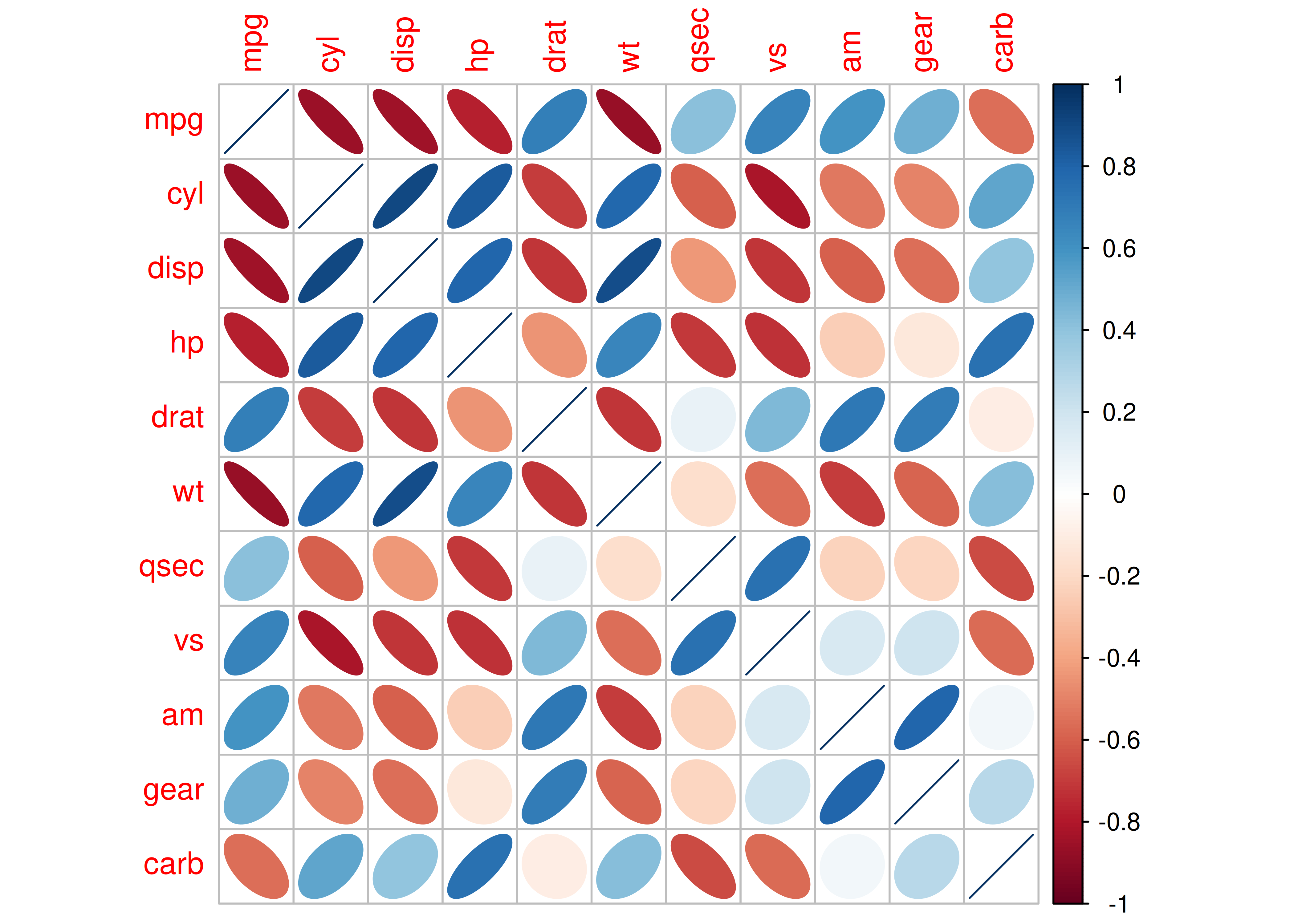
Caso 3: variables reordenadas según análisis de conglomerados
corrplot.mixed(matriz_corr, upper = "ellipse", order = "hclust")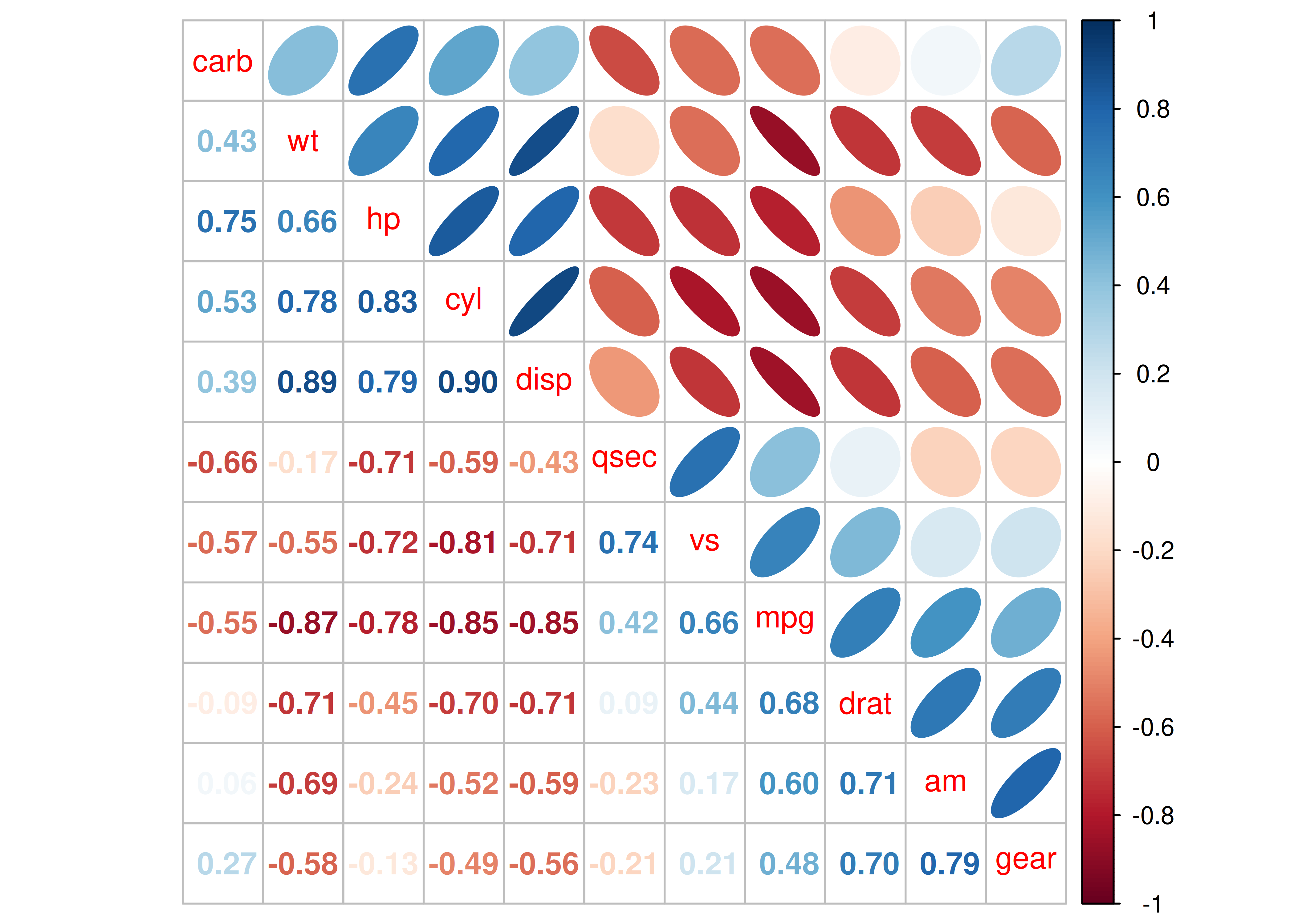
8.9 Series de Tiempo
Los gráficos de series de tiempo son un clásico de la visualización de datos. Se los puede pensar como un caso especial del diagrama de dispersión, cuando una de las dos variables representa el paso del tiempo, y deseamos representar la evolución de la otra variable.
En
ggplot2se los construye mediante la funcióngeom_line(). Debajo vemos un ejemplo con los datos degapminder, convertido aplotlypara facilitar su interpretación:
filtrado <- gapminder %>%
mutate(pobl = pop/1000000) %>%
filter(
country %in% c("Argentina", "Brazil", "Colombia", "Ecuador", "Chile",
"Paraguay", "Bolivia", "Peru", "Uruguay", "Venezuela")
)
serie_sudam <- ggplot(data = filtrado) +
aes(x = year, y = pobl, color = country) +
geom_line(linewidth = 1) +
geom_point(size = 2) +
scale_x_continuous(breaks = seq(1952, 2007, 5)) +
scale_y_continuous(breaks = seq(0, 200, 50), limits = c(0, 200)) +
labs(x = "Año", y = "Población (en millones)",
title = "Evolución de la población de los países sudamericanos") +
theme_bw()
ggplotly(serie_sudam)
- A continuación presentamos dos paquetes que nos ayudan a darle un toque más interesante a este tipo de gráficos.
8.9.1 Paquete echarts4r
Este paquete está desarrollado en JavaScript y permite crear varios tipos de gráficos. En este enlace podemos consultar una galería con ejemplos.
Debajo vemos el código necesario para recrear las series temporales presentadas arriba. Al igual que ocurre con
plotly, la libreríaecharts4rgenera gráficos dinámicos e interactivos:
filtrado %>%
group_by(country) %>%
e_charts(x = year) %>%
e_line(serie = pobl) %>%
e_title("Evolución de la población de los países sudamericanos") %>%
e_x_axis(name = "Año", serie = year) %>%
e_y_axis(name = "Población (en millones)") %>%
e_legend(orient = "vertical", left = "10%", top = "10%") %>%
e_tooltip(trigger = "axis")8.9.2 Paquete highcharter
La librería
highchartertambién está desarrollada en JavaScript y ofrece resultados dinámicos. Se diferencia de otros paquetes para visualización en que está enfocado principalmente en datos económicos.Debajo vemos un gráfico temporal que analiza datos OHLC (Open-high-low-close chart) para acciones de la empresa Amazon. Para acceder a este tipo de datos es necesario tener instalado, además, el paquete
quantmod:
amazon <- getSymbols("AMZN", auto.assign = FALSE)
hchart(amazon, type = "ohlc") %>%
hc_title(text = "Serie temporal: datos OHLC para Amazon") %>%
hc_add_theme(hc_theme_bloom())8.10 Recursos Extra
From Data to Viz: proyecto que busca clasificar diferentes tipos de gráficos estadísticos y visualizaciones en categorías, según su objetivo y características principales.
The R Graph Gallery: similar a From Data to Viz, agregar ejemplos de código en R para desarrollar cada tipo de gráfico.
Paquete ggforce: paquete que agrega complementos muy interesantes para
ggplot2. Ejemplo de agrupamiento de individuos:
library(ggforce)
library(concaveman)
ggplot(data = iris) +
aes(x = Petal.Length, y = Petal.Width) +
geom_point() +
geom_mark_hull(aes(label = Species, fill = Species), show.legend = FALSE) +
theme_bw()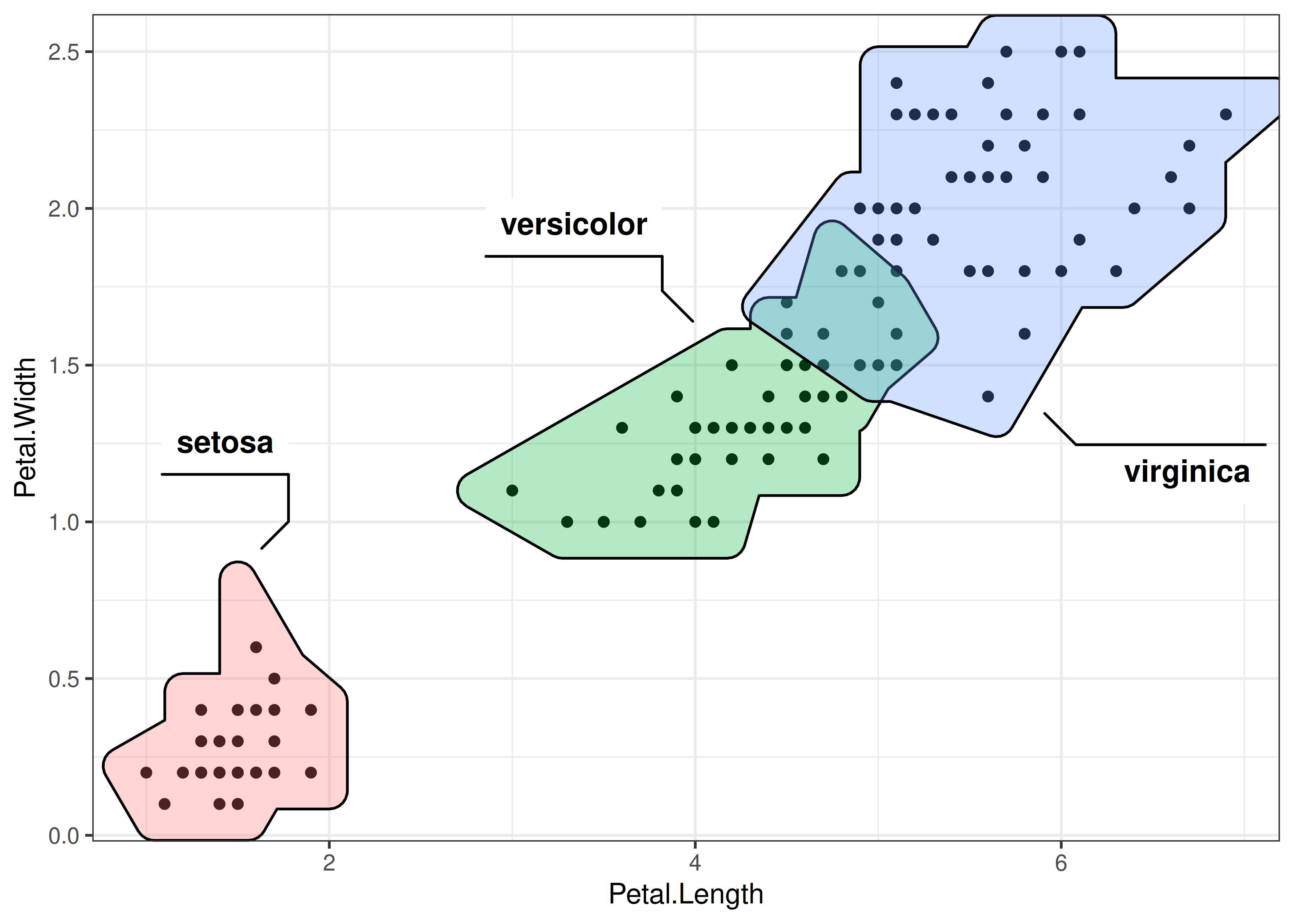
8.11 Ejercicios
- Usando las técnicas aprendidas durante esta clase, tratar de replicar los siguientes gráficos.
8.11.1 Ridgeline
- Usando los datos de cultivos que trabajamos en unidades anteriores de la materia, crear un gráfico de curvas de densidad del estilo ridgeline que compare el rendimiento del girasol desde el año 2010 en adelante (las curvas se calculan teniendo en cuenta a los departamentos como individuos).
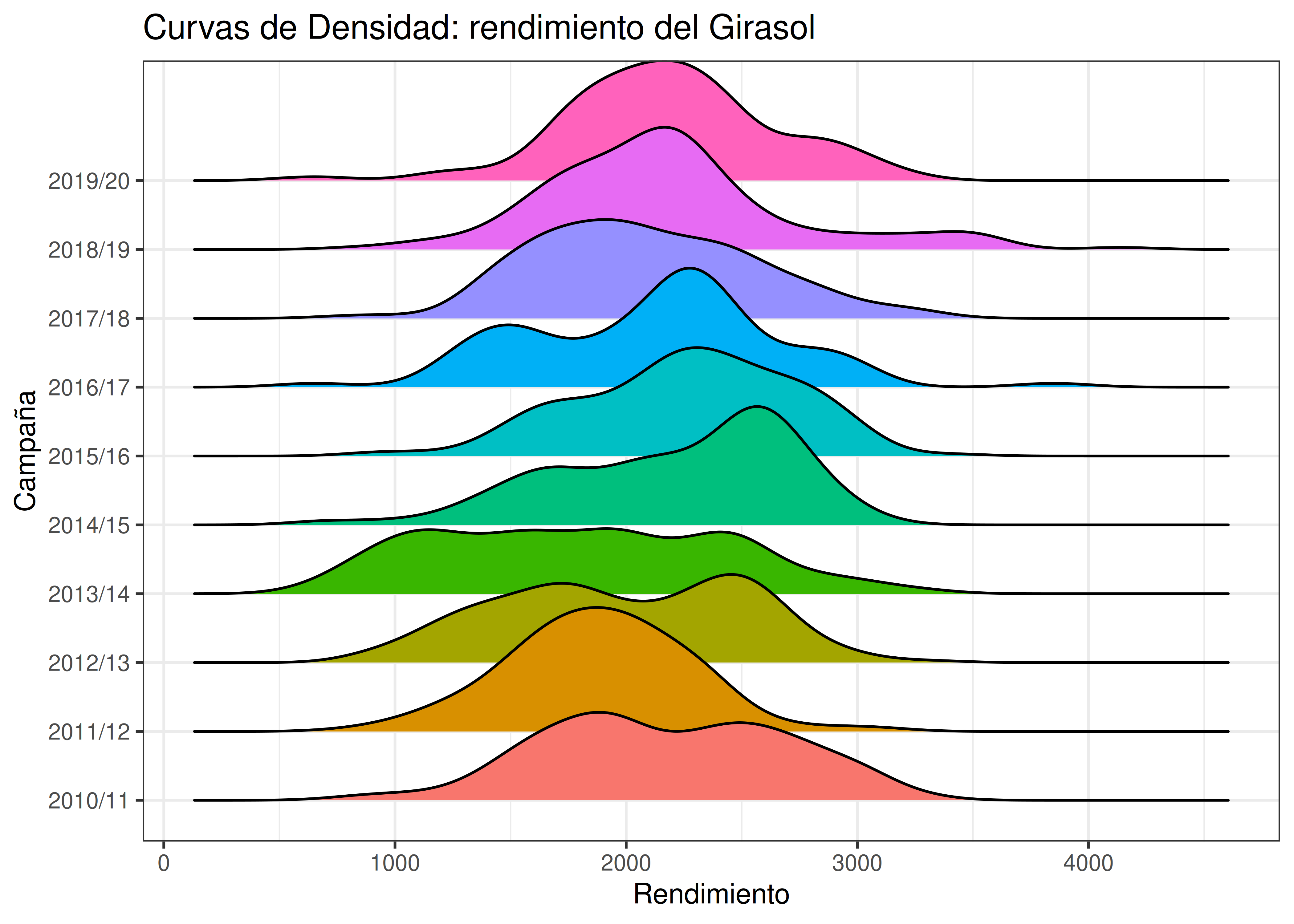
8.11.2 Dispersión 3D
Crear un gráfico de dispersión en 3D para las variables touches (toques), passes_pct (% de pases correctos) y ball_recoveries (pelotas recuperadas) utilizando a los jugadores de las 8 selecciones que alcanzaron los cuartos de final del Mundial de Qatar (ver variable ronda).
El recuadro a mostrar cuando se pasa el mouse en cada punto debe mostrar, además de las 3 variables graficadas, el nombre, selección y posición de cada jugador.
8.11.3 Gráfico animado
- Usando la base de datos de
gapminder, generar esta animación que muestra la evolución temporal del PBI y la esperanza de vida para tres países: Argentina, China y Francia.
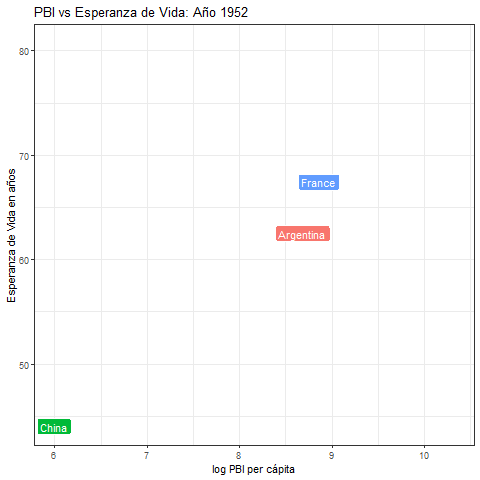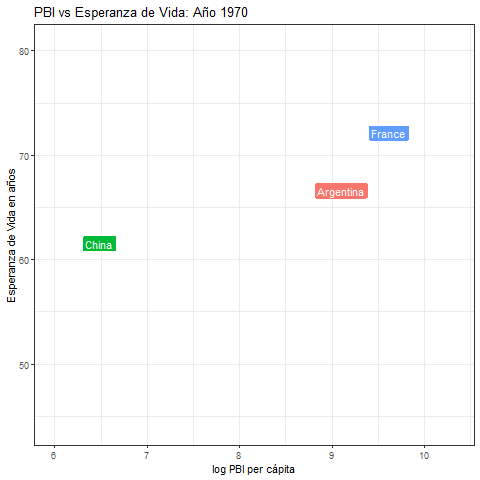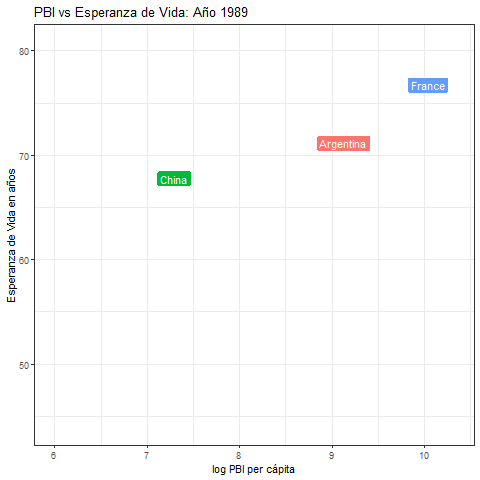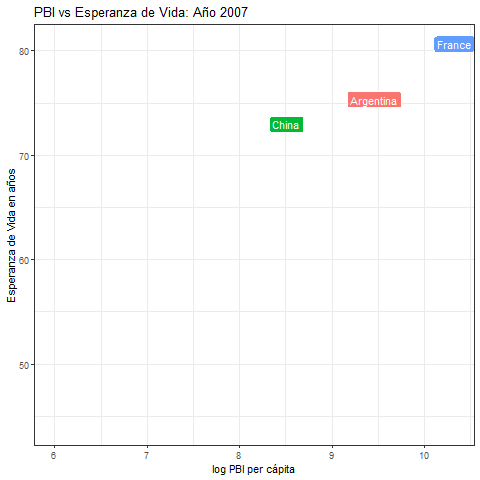
8.11.4 Radar
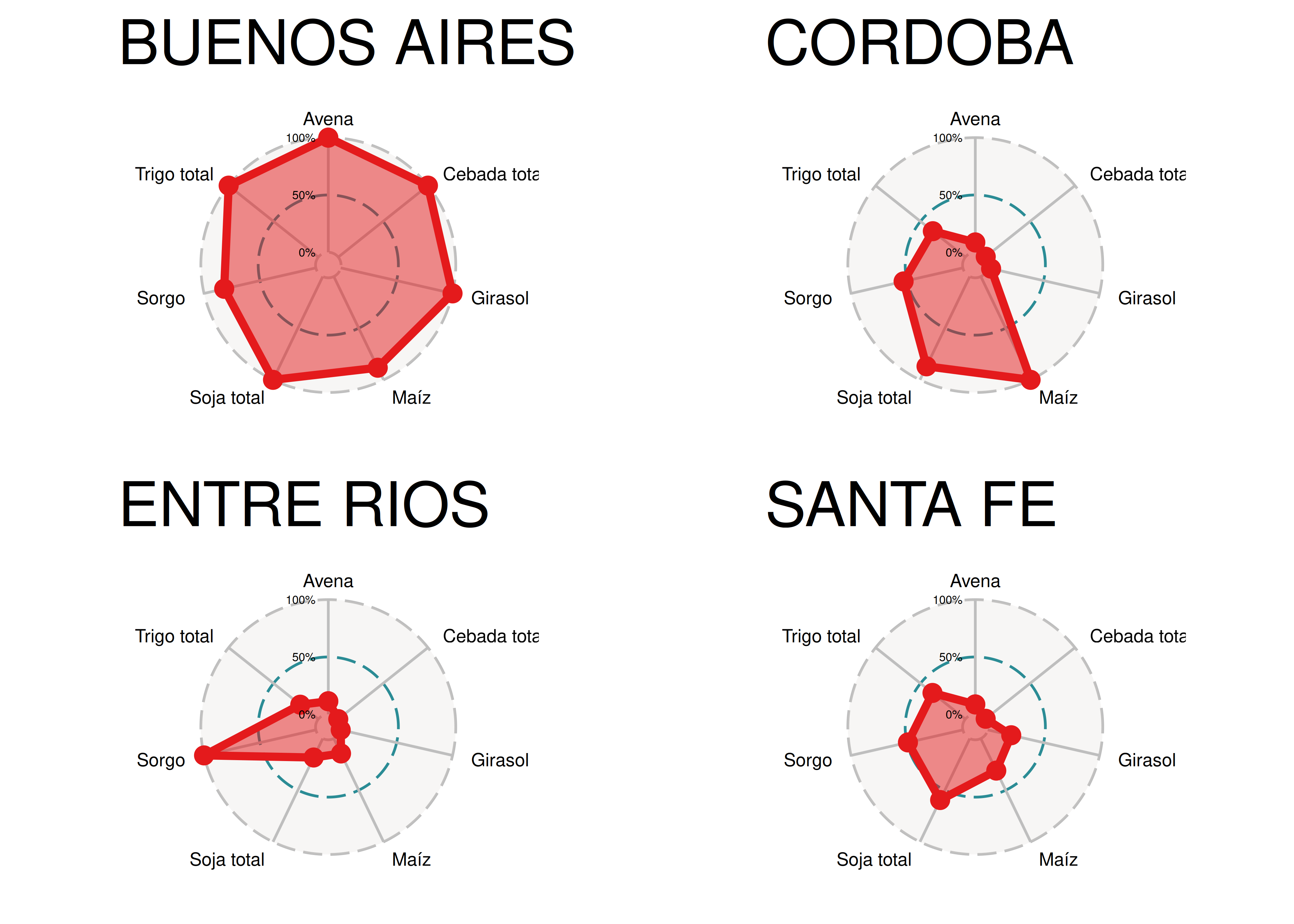
- Construir 4 radar charts que comparen las producciones de los siguientes cultivos: arveja, avena, cebada, girasol, maíz, soja, sorgo y trigo, considerando datos de la campaña 2018/19 en las provincias de Buenos Aires, Córdoba, Entre Ríos y Santa Fe.
8.11.5 Mapa de Calor
Resumir los datos del Mundial para obtener una base de datos con un registro por selección, que contenga la siguiente información: mediana de edad de los jugadores, mediana del % de pases correctos, y suma de las variables cards_red, cards_yellow, fouls y goals.
Con esta información construir un mapa de calor dividiendo a las selecciones en 5 clusters.