#Lectura y manipulación de datos
library(dplyr)
library(readxl)
library(ggplot2)
#Gráficos Varios
library(vcd)
library(plotly)
library(ggalluvial)
library(treemapify)
#Diagramas de Venn
library(grid)
library(ggvenn)
library(VennDiagram)
#Nubes de Palabras
library(igraph)
library(ggraph)
library(widyr)
library(tidytext)
library(ggwordcloud)7 Visualización de Variables Cualitativas
Análisis Exploratorio de Datos | Licenciatura en Estadística | FCEyE | UNR
7.1 Introducción
En esta unidad vamos a repasar gráficos útiles para visualizar y resumir variables categóricas.
Paquetes de R necesarios para reproducir los ejemplos:
7.1.1 Datos Titanic

El famoso transatlántico Titanic se hundió en abril de 1912 durante su viaje inaugural. El conjunto de datos
Titanicdel paquete de R Basedatasetscontiene información sobre qué pasajeros/as sobrevivieron a la tragedia y cuáles no, desagregada según edad, género y clase en la que viajaban.Vemos los datos en R:
as.data.frame(Titanic) Class Sex Age Survived Freq
1 1st Male Child No 0
2 2nd Male Child No 0
3 3rd Male Child No 35
4 Crew Male Child No 0
5 1st Female Child No 0
6 2nd Female Child No 0
7 3rd Female Child No 17
8 Crew Female Child No 0
9 1st Male Adult No 118
10 2nd Male Adult No 154
11 3rd Male Adult No 387
12 Crew Male Adult No 670
13 1st Female Adult No 4
14 2nd Female Adult No 13
15 3rd Female Adult No 89
16 Crew Female Adult No 3
17 1st Male Child Yes 5
18 2nd Male Child Yes 11
19 3rd Male Child Yes 13
20 Crew Male Child Yes 0
21 1st Female Child Yes 1
22 2nd Female Child Yes 13
23 3rd Female Child Yes 14
24 Crew Female Child Yes 0
25 1st Male Adult Yes 57
26 2nd Male Adult Yes 14
27 3rd Male Adult Yes 75
28 Crew Male Adult Yes 192
29 1st Female Adult Yes 140
30 2nd Female Adult Yes 80
31 3rd Female Adult Yes 76
32 Crew Female Adult Yes 20
- A continuación emplearemos esta base de datos para practicar la creación de diversos tipos de gráficos.
7.2 Barras
7.2.1 Univariadas
Una de las alternativas más populares para explorar variables cualitativas son los gráficos de barras. El alto de cada rectángulo representa la frecuencia (absoluta o relativa) de las diferentes categorías que estamos comparando.
Estos gráficos son simples de construir e interpretar: mientras más extensa la barra, mayor frecuencia posee la categoría asociada.
Usando los datos del Titanic podemos armar un gráfico de barras para la variable Class de la siguiente manera:
Paso 1: calculamos los conteos de cada clase
clase_titanic <- Titanic %>%
as.data.frame() %>%
group_by(Class) %>%
summarise(conteo = sum(Freq)) %>%
ungroup()
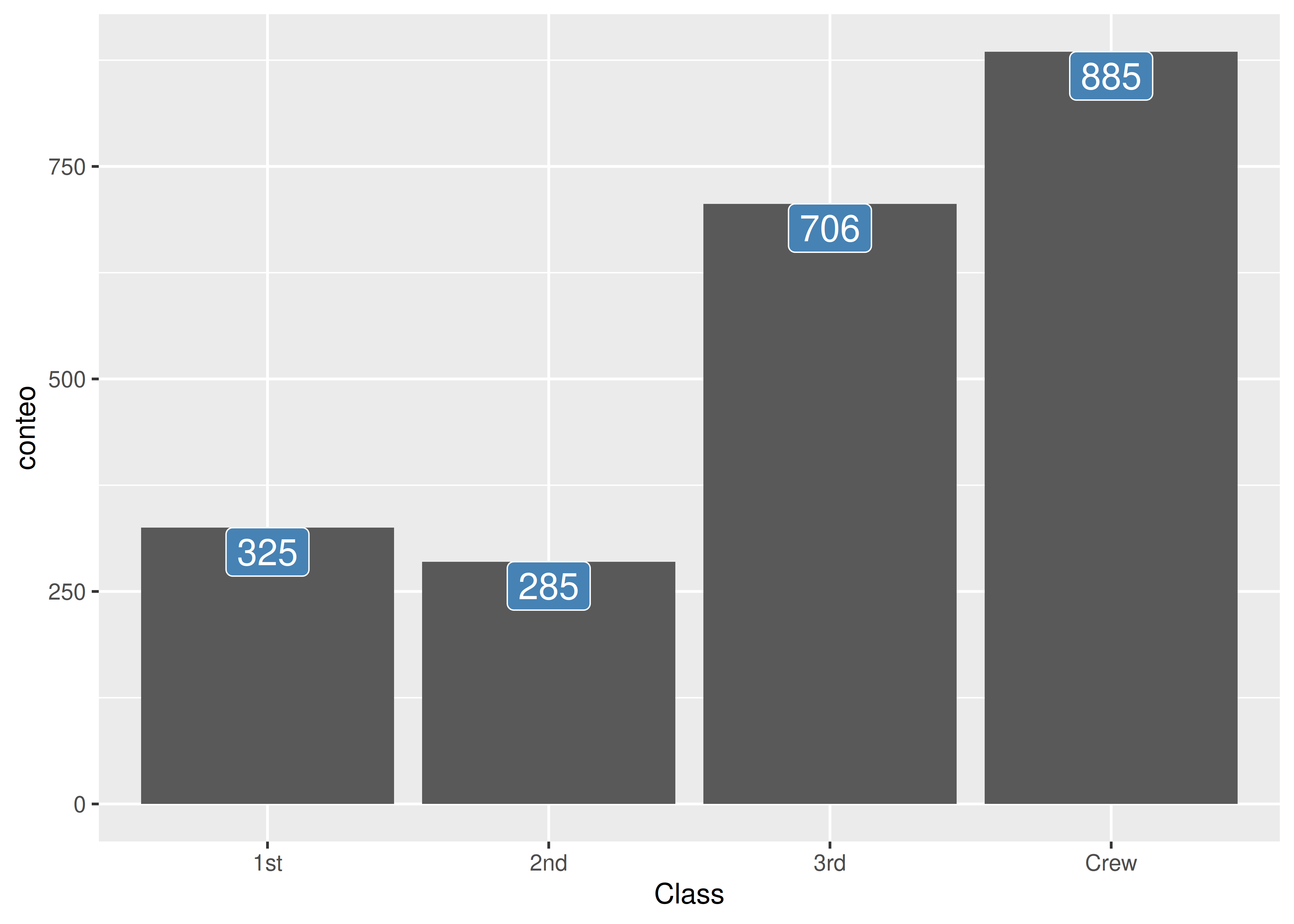
clase_titanic# A tibble: 4 × 2
Class conteo
<fct> <dbl>
1 1st 325
2 2nd 285
3 3rd 706
4 Crew 885
Paso 2: armamos el gráfico
ggplot(data = clase_titanic) +
aes(x = Class, y = conteo) +
geom_bar(stat = "identity")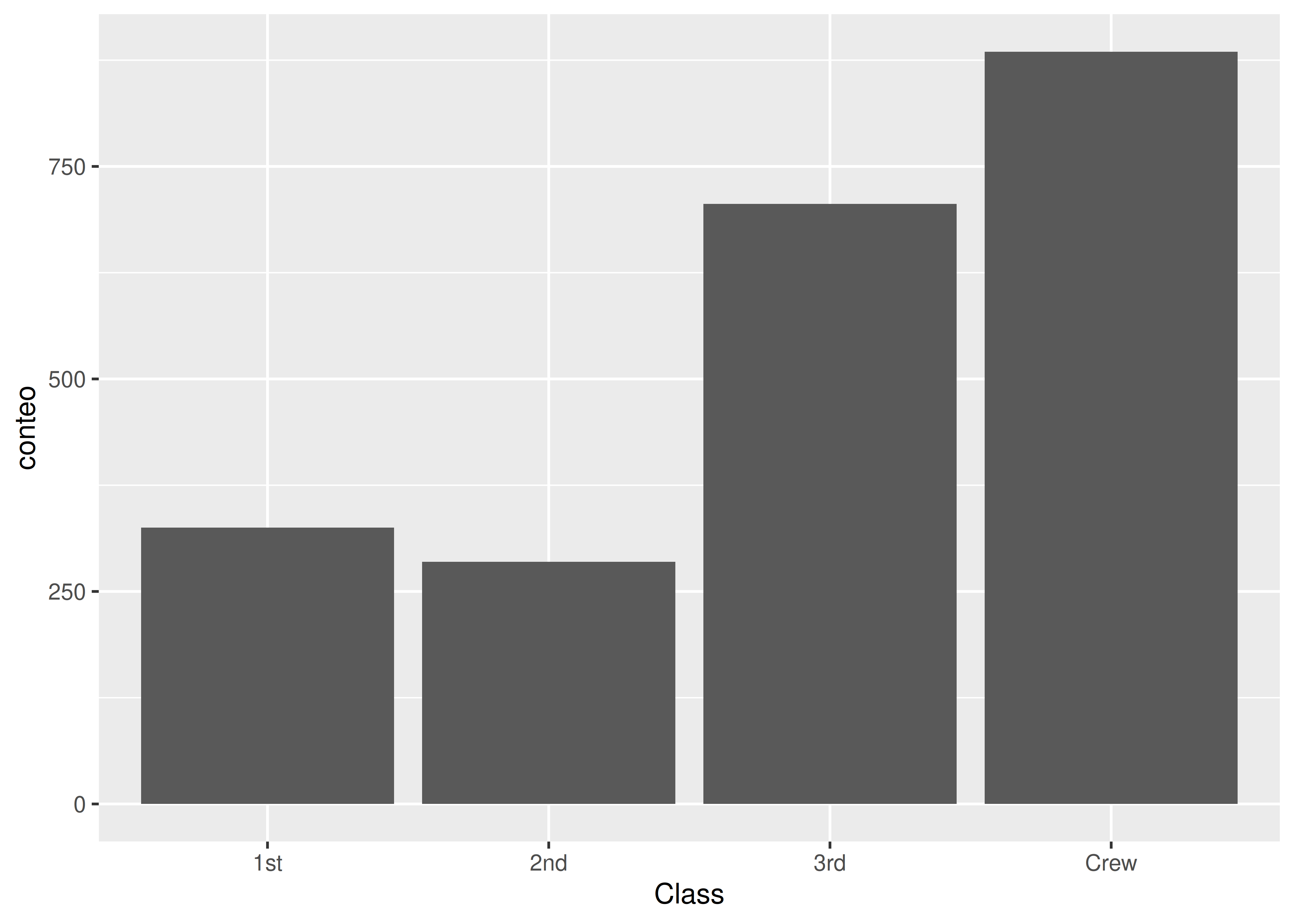
- Es importante remarcar que
ggplot2también puede armar este tipo de gráficos a partir de datos crudos (desagregados). Si hubiésemos tenido una base de datos con una fila para cada pasajero del Titanic, el código para generar el gráfico de barras es aún más simple que el anterior:
ggplot(data = titanic_desagregado) +
aes(x = Class) +
geom_bar()Notemos que en este caso no es necesario agregar en el mapeo la variable
y, asociada a la frecuencia de cada categoría. Además, dentro degeom_bar()usamos ahora la opción por defecto (stat = "count"), mientras que antes debíamos indicar el uso destat = "identity".La decisión entre usar datos agregados o desagregados no impacta en el resultado final, y depende casi exclusivamente del formato de la base de datos con la que estemos trabajando.
Colores
Un retoque que podemos incluir consiste en agregar una paleta de colores que remarque las diferencias entre categorías.
En general se asocian colores oscuros a categorías más frecuentes, y colores claros a categorías menos populares:
ggplot(data = clase_titanic) +
aes(x = Class, y = conteo, fill = conteo) +
geom_bar(stat = "identity") +
scale_fill_continuous(low = "lightgreen", high = "darkgreen")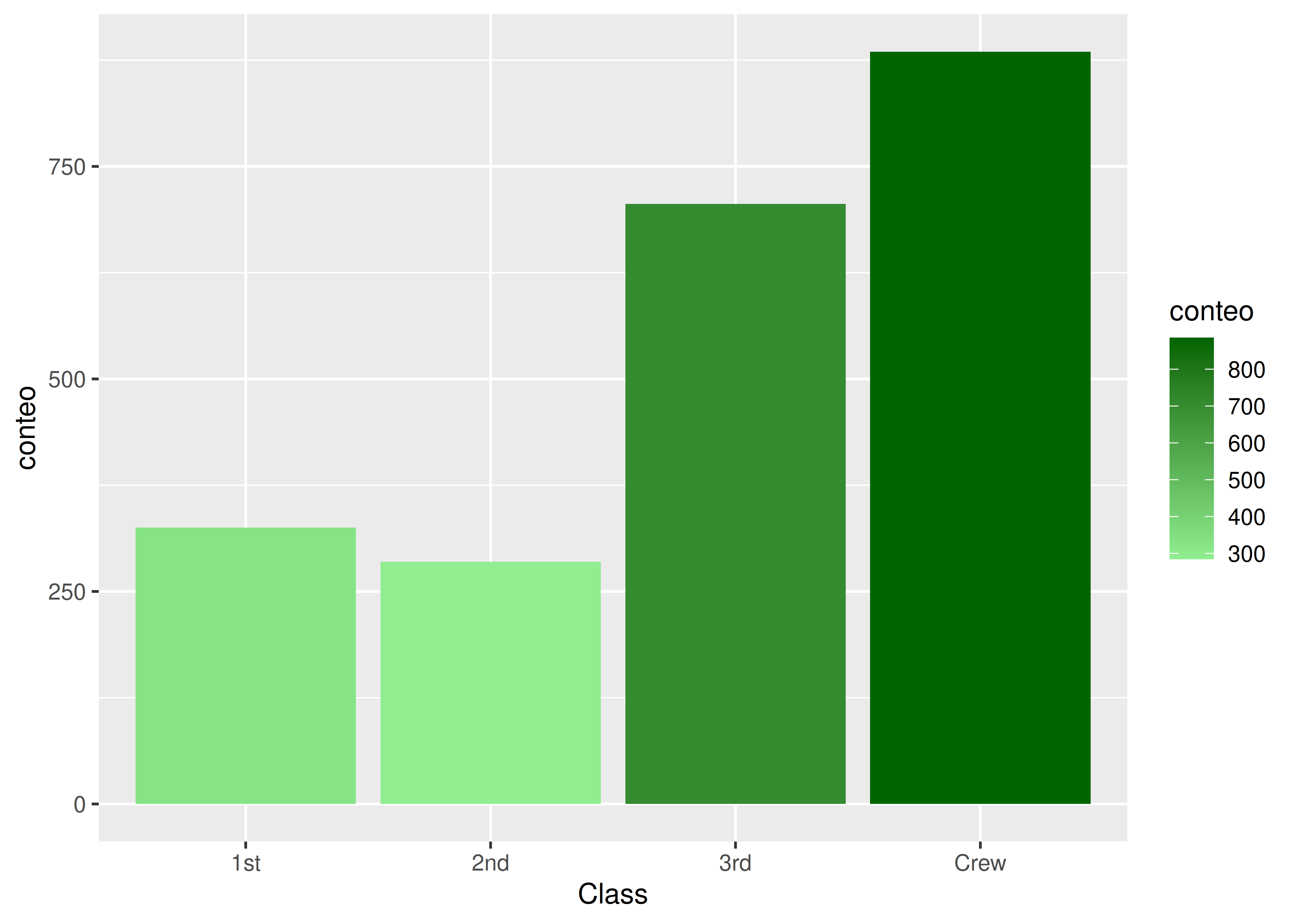
- En ocasiones, el color puede estar asociado a la categoría y no a su frecuencia (este caso sólo responde a cuestiones estéticas, ya que el color no aporta ninguna nueva información):
ggplot(data = clase_titanic) +
aes(x = Class, y = conteo, fill = Class) +
geom_bar(stat = "identity")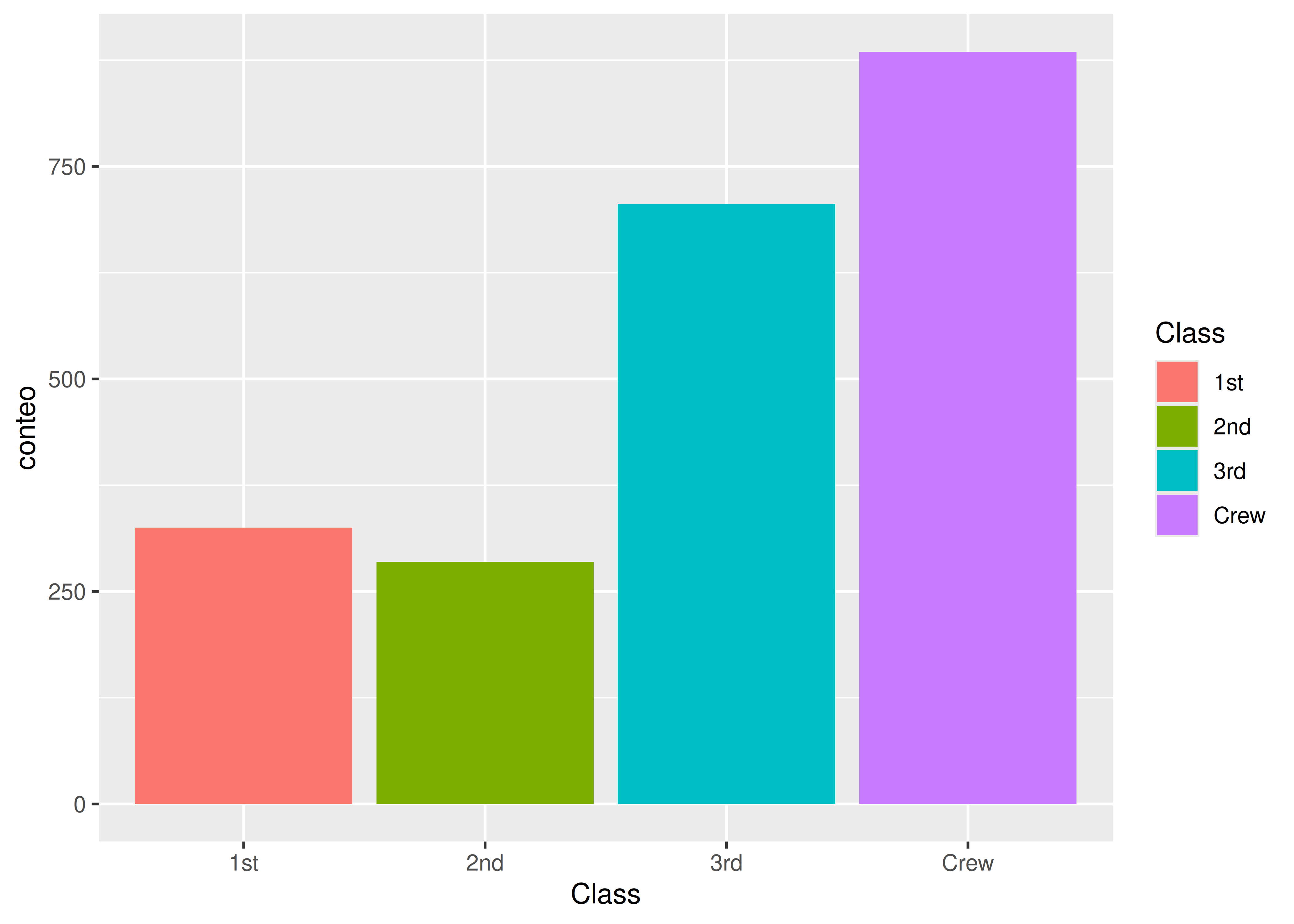
Frecuencias Relativas
Una alternativa común consiste en graficar proporciones o porcentajes en lugar de frecuencias absolutas.
El cálculo de las proporciones correspondientes puede hacerse de antemano (es decir, al momento en que generamos el dataset
clase_titanic) o bien dentro del mapeo estético, como vemos a continuación:
ggplot(data = clase_titanic) +
aes(x = Class, y = conteo/sum(conteo)) +
geom_bar(stat = "identity") +
scale_y_continuous(name = "Porcentaje", labels = scales::percent)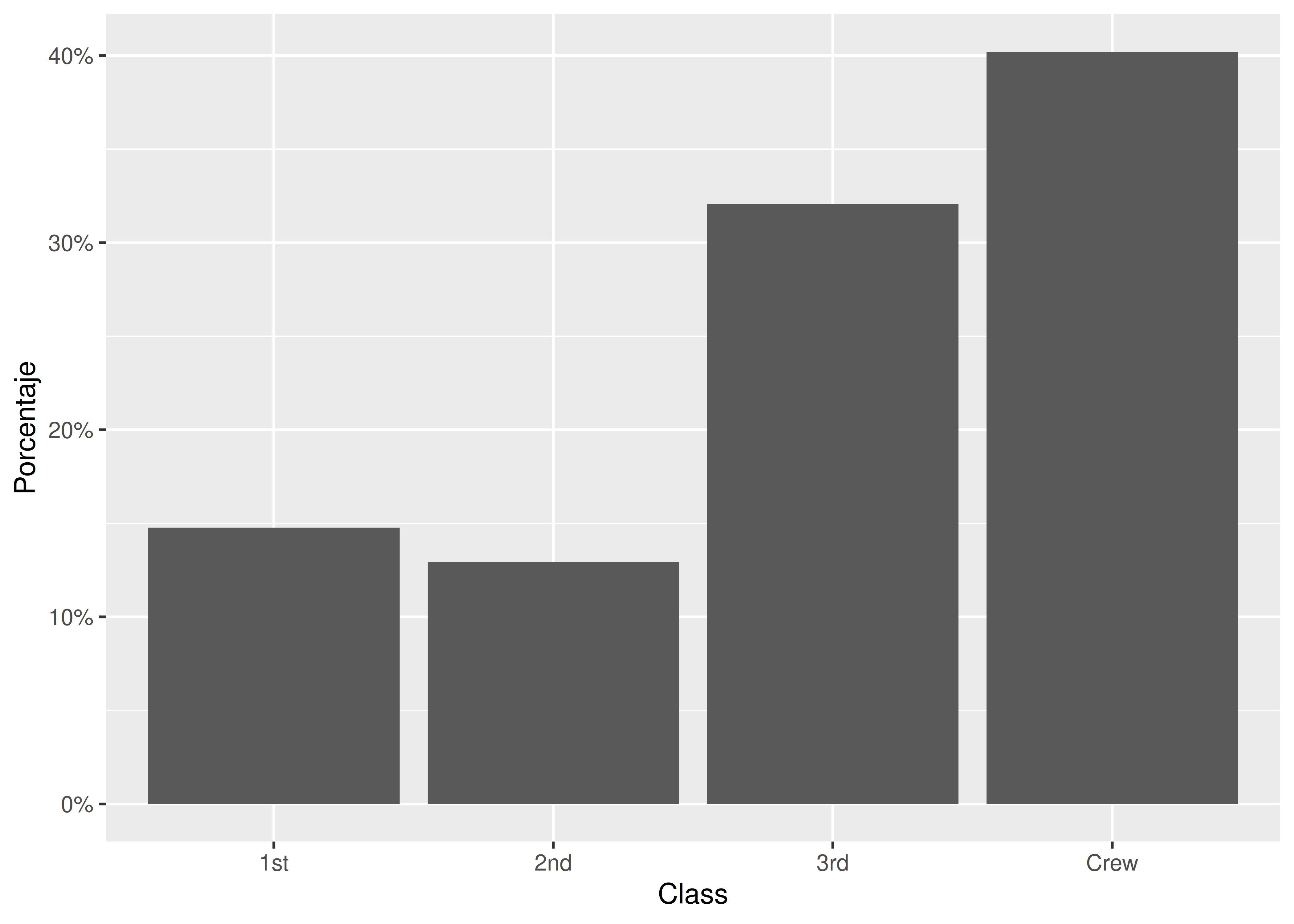
- Aclaración: la función
percent()del paquetescalesaplica el formato necesario al eje vertical para que la escala figure en porcentajes.
Reordenamiento
Si la variable en estudio es de tipo
character,ggplot2emplea el orden alfabético de las categorías para graficar las barras. En caso de que la variable sea de tipofactor, el orden utilizado respeta el ordenamiento de sus niveles.Sin embargo, en varias ocasiones vamos a preferir un orden personalizado, ya sea porque no nos convence el orden alfabético, o los niveles del factor no siguen un orden lógico, o preferimos mostrar las categorías según su frecuencia, etc.
La manera más directa de modificar el orden en que se muestran las barras es convirtiendo la variable a
factory asignando el orden deseado a los niveles. Veamos un ejemplo donde el orden depende de la frecuencia observada:
clase_titanic %>%
arrange(desc(conteo)) %>%
#Factor con niveles ordenados según frecuencia
mutate(Class = factor(Class, levels = unique(Class))) %>%
ggplot() +
aes(x = Class, y = conteo) +
geom_bar(stat = "identity")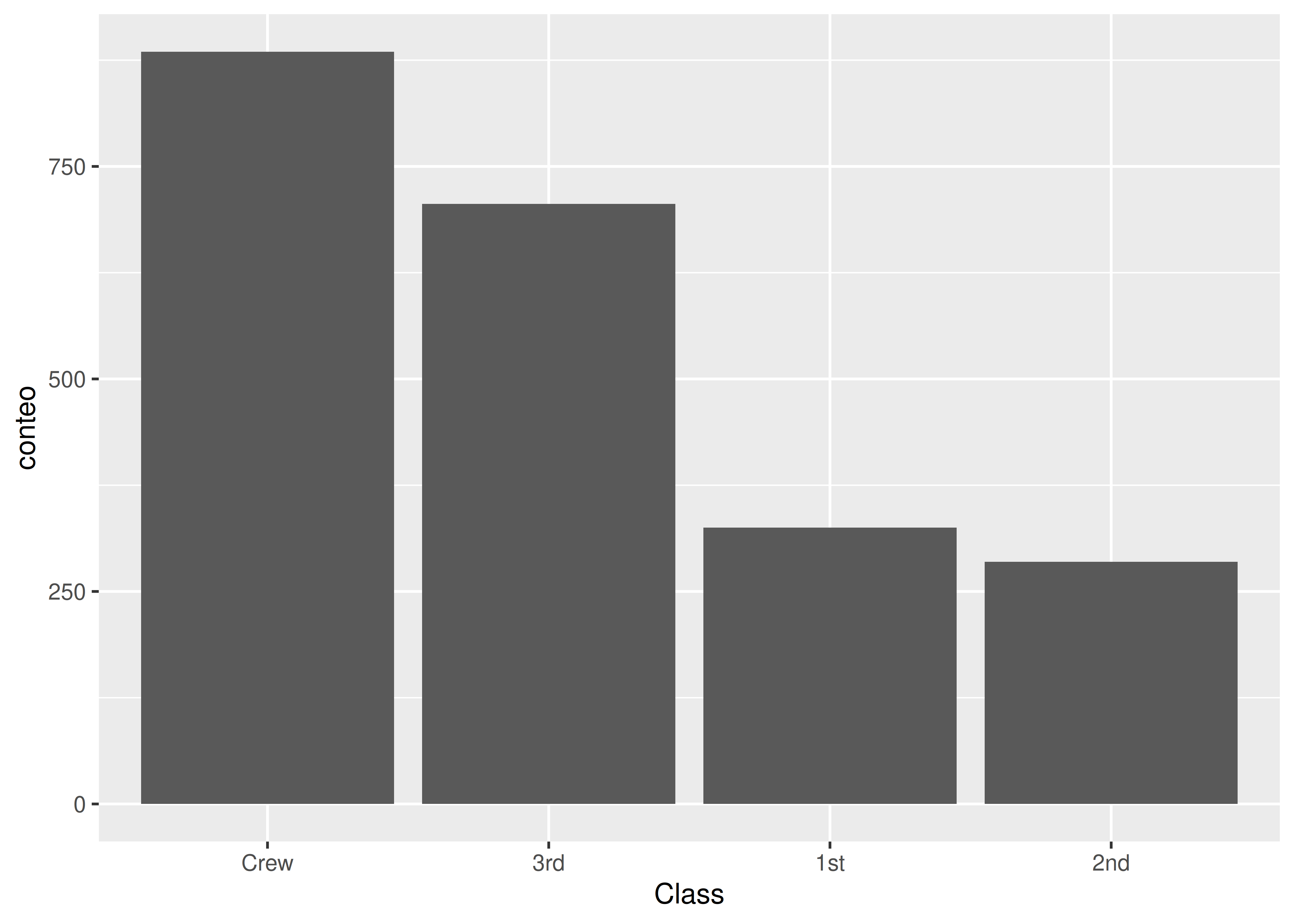
Etiquetas
Otro agregado común consiste en incluir una etiqueta con el valor asociado a cada barra, reforzando así el mensaje visual y eliminando la necesidad de mostrar la tabla de frecuencias de la variable graficada.
Esto se logra aplicando la capa
geom_label():
ggplot(data = clase_titanic) +
aes(x = Class, y = conteo) +
geom_bar(stat = "identity") +
geom_label(
aes(label = conteo), #texto a mostrar en cada barra (en este caso, el conteo)
vjust = 1, #justificacion vertical, en este caso arriba de todo
size = 5, #tamaño de la etiqueta
fill = "steelblue", #color de fondo
color = "white" #color del texto
)
7.2.2 Bivariadas
- Para ejemplificar los gráficos de barras bivariados vamos a agregar al análisis la variable Sex del dataset Titanic:
titanic_bivariado <- Titanic %>%
as.data.frame() %>%
group_by(Class, Sex) %>%
summarise(conteo = sum(Freq)) %>%
ungroup()
titanic_bivariado# A tibble: 8 × 3
Class Sex conteo
<fct> <fct> <dbl>
1 1st Male 180
2 1st Female 145
3 2nd Male 179
4 2nd Female 106
5 3rd Male 510
6 3rd Female 196
7 Crew Male 862
8 Crew Female 23Barras Apiladas
Una manera de visualizar dos variables categóricas al mismo tiempo es a través de un gráfico de barras apiladas.
En estos casos cada barra se subdivide en las categorías de la segunda variable, siendo las alturas proporcionales a la cantidad de individuos que presentan ambas características a la vez.
ggplot(data = titanic_bivariado) +
aes(x = Class, fill = Sex, y = conteo) +
geom_bar(stat = "identity")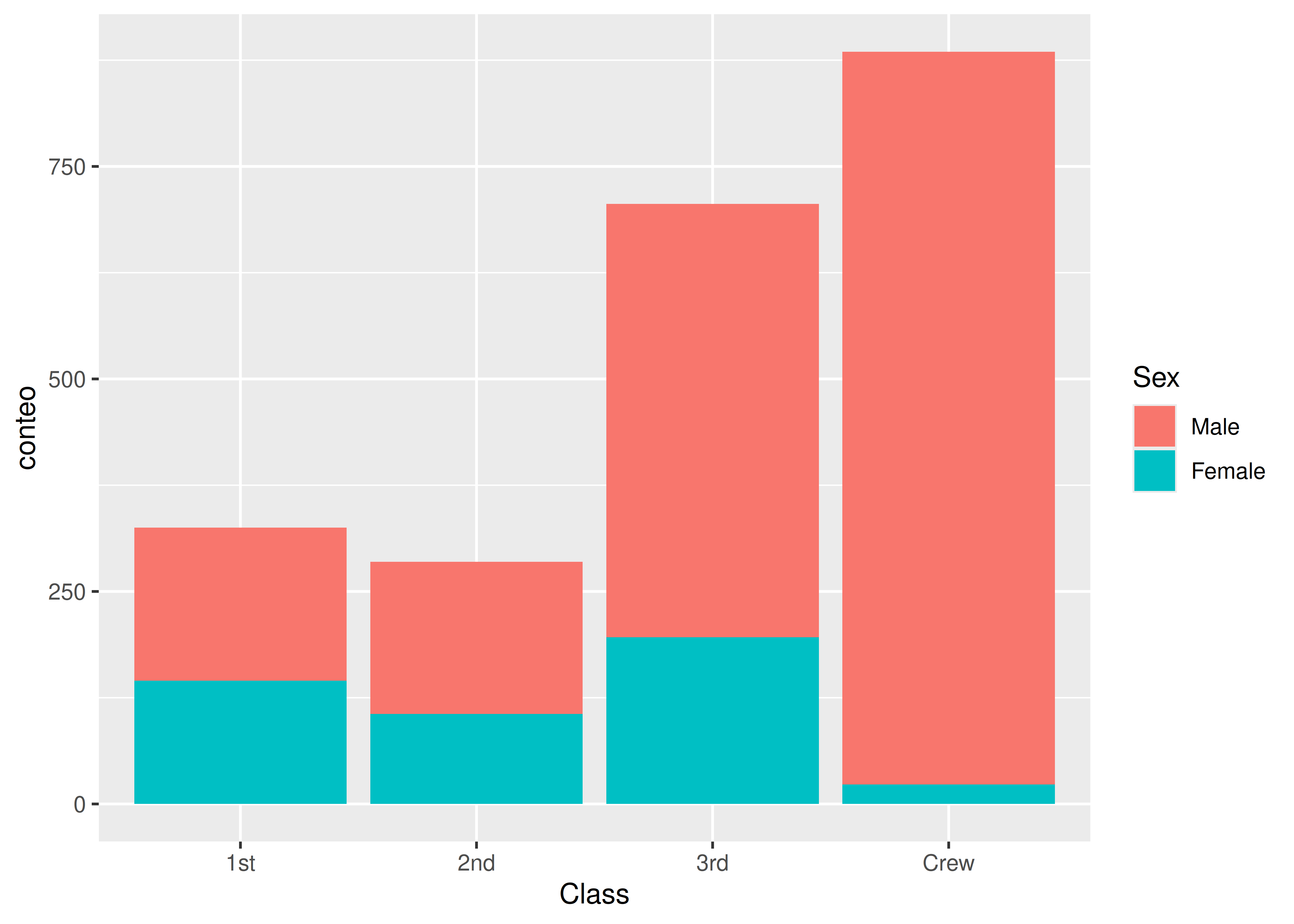
En este gráfico, cada subdivisión de la barra posee un alto igual al de su frecuencia absoluta.
Una alternativa mucho más conveniente, utilizada sobre todo cuando los tamaños de muestra entre grupos son muy disímiles, consiste en fijar el alto total de cada barra en 100% y calcular las alturas de las subdivisiones como proporciones intra-grupo.
En R esto se logra añadiendo la opción
position = "fill":
ggplot(data = titanic_bivariado) +
aes(x = Class, fill = Sex, y = conteo) +
geom_bar(stat = "identity", position = "fill")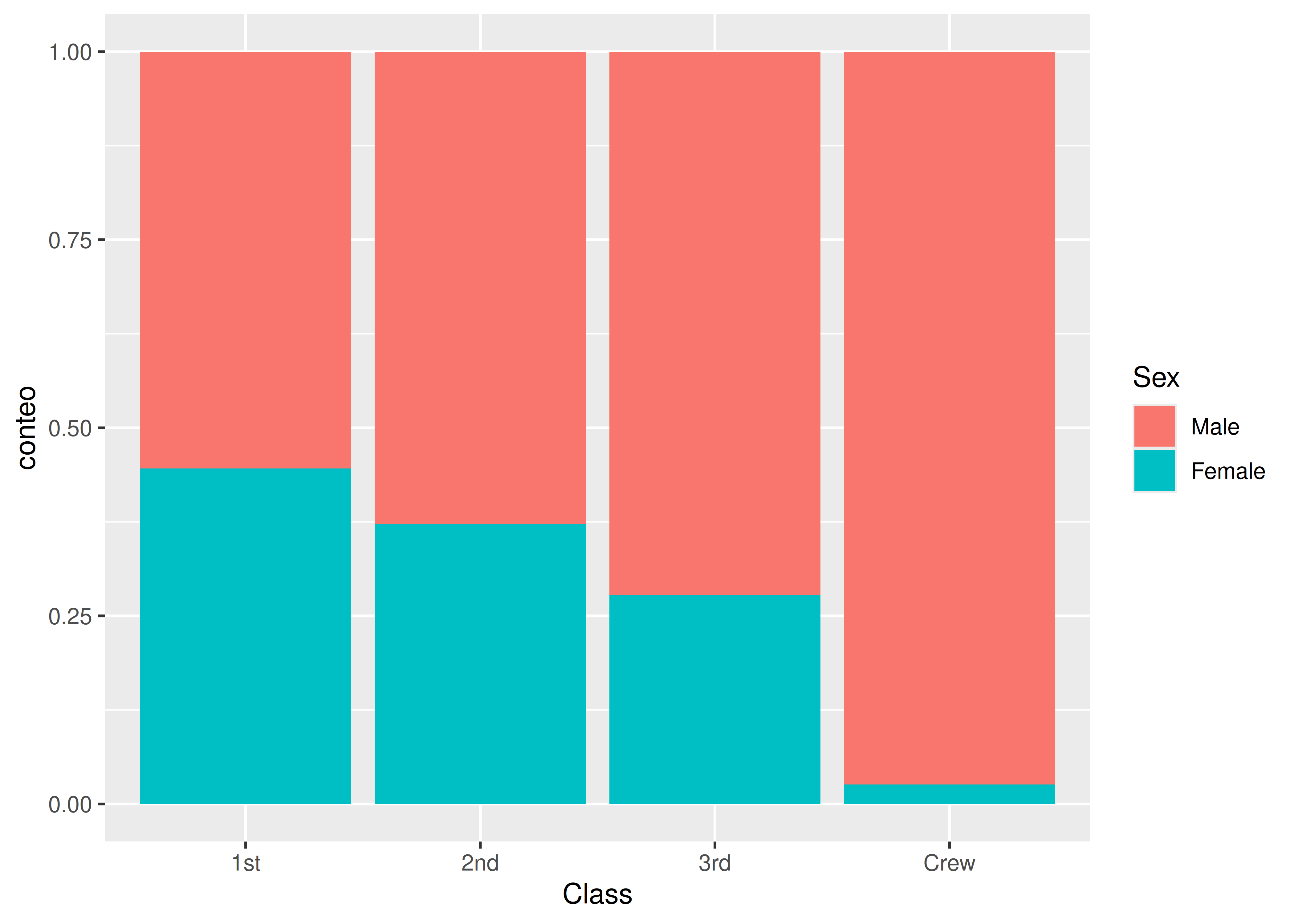
Importante
En caso de existir una relación de explicativa y respuesta entre las variables graficadas, por convención se ubica la explicativa en el eje horizontal, mientras que la respuesta se asocia a los diferentes colores de cada barra.
En estos casos se asume que el interés está enfocado en visualizar la distribución condicional de Y dado X.
Barras lado a lado
- Si no nos gustan las barras apiladas, podemos construir nuestro gráfico con barras contiguas (
position = "dodge"):
ggplot(data = titanic_bivariado) +
aes(x = Class, fill = Sex, y = conteo) +
geom_bar(stat = "identity", position = "dodge")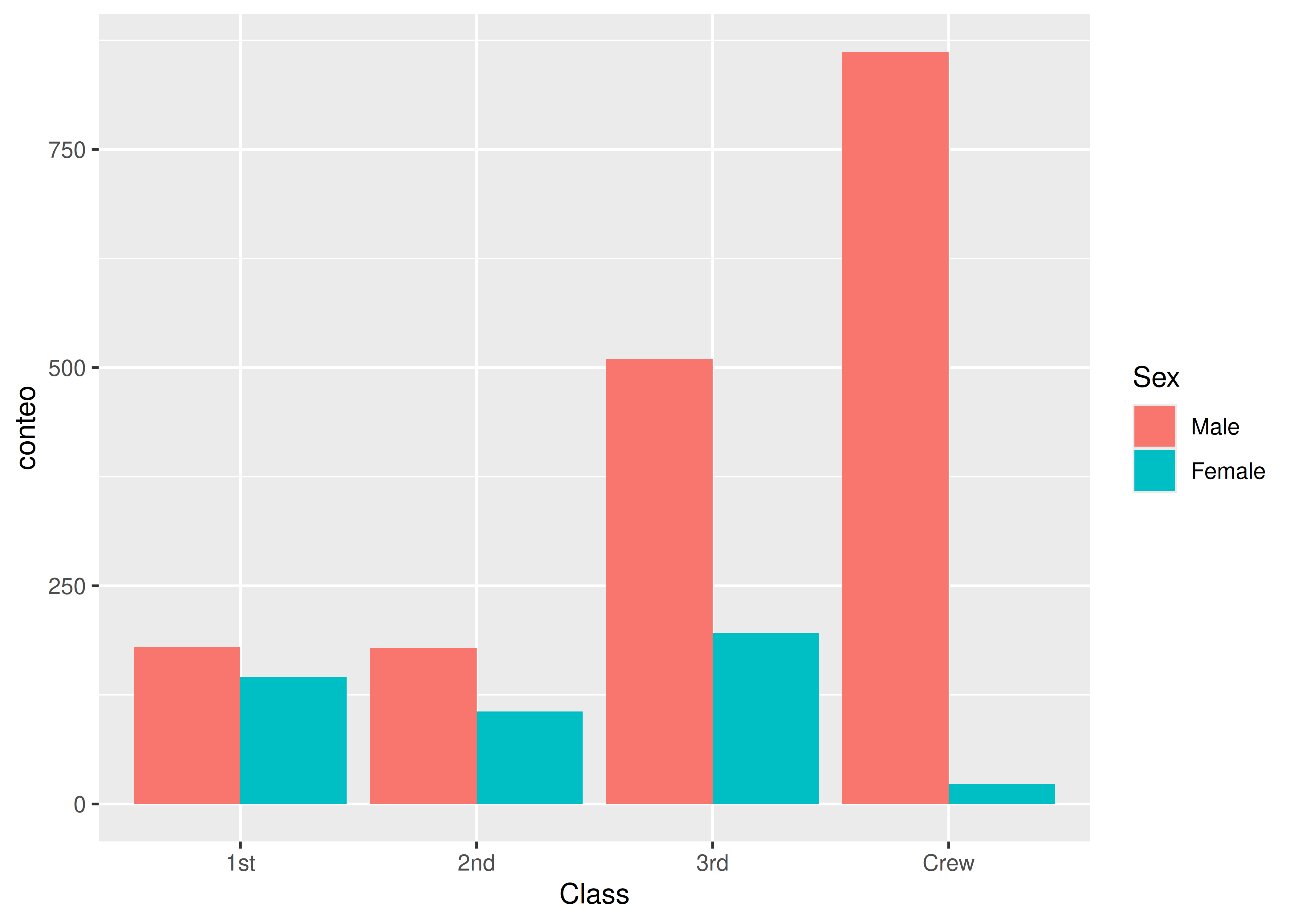
- Esta manera de visualizar los datos es recomendable únicamente cuando los tamaños de muestra entre grupos son similares, y la cantidad posible de combinaciones entre niveles de ambas variables (es decir, la cantidad de barras) no resulte demasiado alta.
Importante
Cuando usamos barras lado a lado se asume que estamos interesados en visualizar la distribución conjunta de las 2 variables, a diferencia de lo que ocurre con las barras apiladas, donde nos interesa la condicional.
7.2.3 Ejercicio
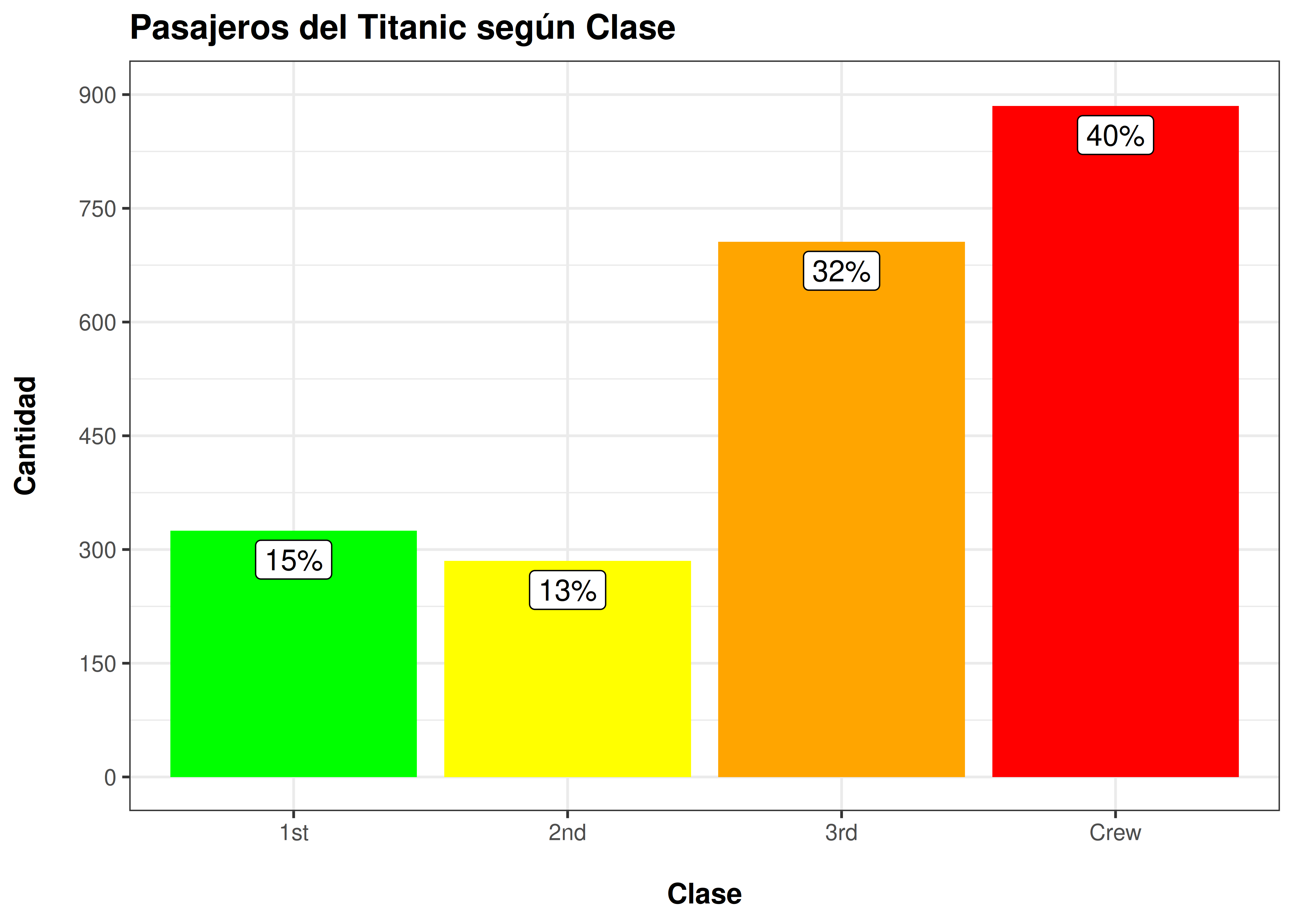
- Aplicando los conceptos presentados en esta sección y tus conocimientos previos sobre
ggplot2, tratar de reconstruir el siguiente gráfico:
7.3 Tortas
Los gráficos de torta (pie charts en inglés), también conocidos como gráficos de sectores circulares, son una herramienta de visualización orientada a la comparación de frecuencias entre los distintos niveles de una variable categórica.
En este sentido, su objetivo es exactamente el mismo que el de los gráficos de barras.
Para su construcción se divide un círculo en tantas “porciones” como categorías tenga la variable, de tal manera que el ángulo de cada sector resulte proporcional a la cantidad de individuos correspondientes a esa categoría.
Si quisiéramos construir a mano un pie chart de la variable Class, debemos multiplicar cada frecuencia relativa por 360°, obteniendo así los grados de cada ángulo:
clase_titanic %>%
mutate(
prop = conteo/sum(conteo),
angulo = round(360 * prop, 2)
)# A tibble: 4 × 4
Class conteo prop angulo
<fct> <dbl> <dbl> <dbl>
1 1st 325 0.148 53.2
2 2nd 285 0.129 46.6
3 3rd 706 0.321 115.
4 Crew 885 0.402 145. - En R podemos generar un gráfico de este estilo usando la misma función que antes,
geom_bar(), pero cambiando el sistema de coordenadas (pasamos a las polares):
ggplot(data = clase_titanic) +
aes(x = "", y = conteo, fill = Class) +
geom_bar(stat = "identity") +
coord_polar("y") +
theme(
panel.grid = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank()
)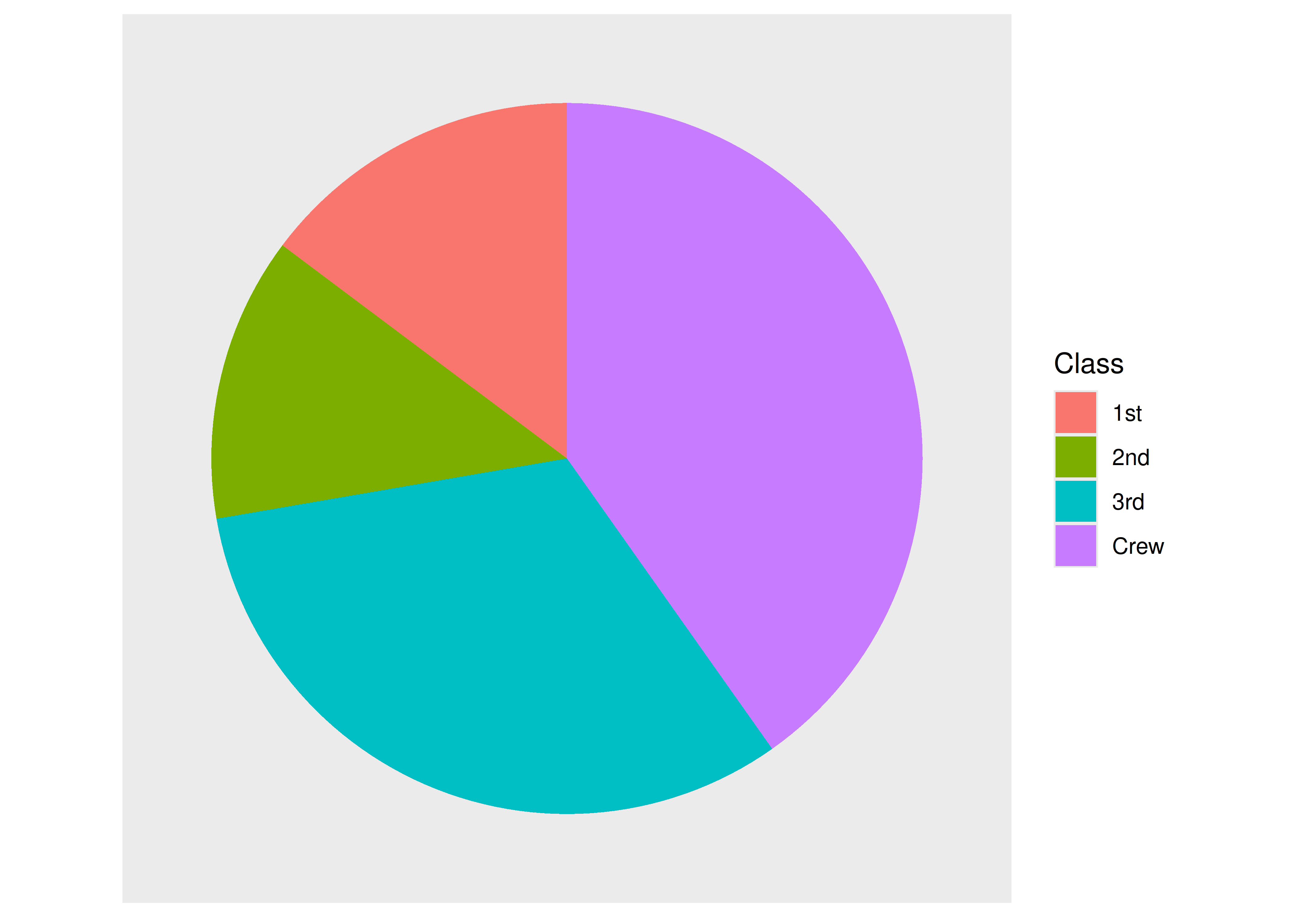
La pregunta que surge es, ¿son realmente útiles estos gráficos?
Veámoslo desde este punto de vista: para lograr nuestro objetivo de comparar visualmente las categorías más populares tenemos dos opciones:
- Armar un gráfico de barras, donde la longitud de cada barra corresponde a la frecuencia absoluta o relativa registradas en esa categoría.
- Armar un gráfico de torta, donde el ángulo de cada sector es proporcional a la cantidad de respuestas en esa categoría.
Creemos que nadie en su sano juicio preferiría la opción 2 en lugar de la 1.
Si esto les parece exagerado, traten de ordenar las categorías desde la más hasta la menos frecuente mirando el siguiente par de gráficos. ¿Con cuál de los dos resulta más fácil hacer comparaciones?
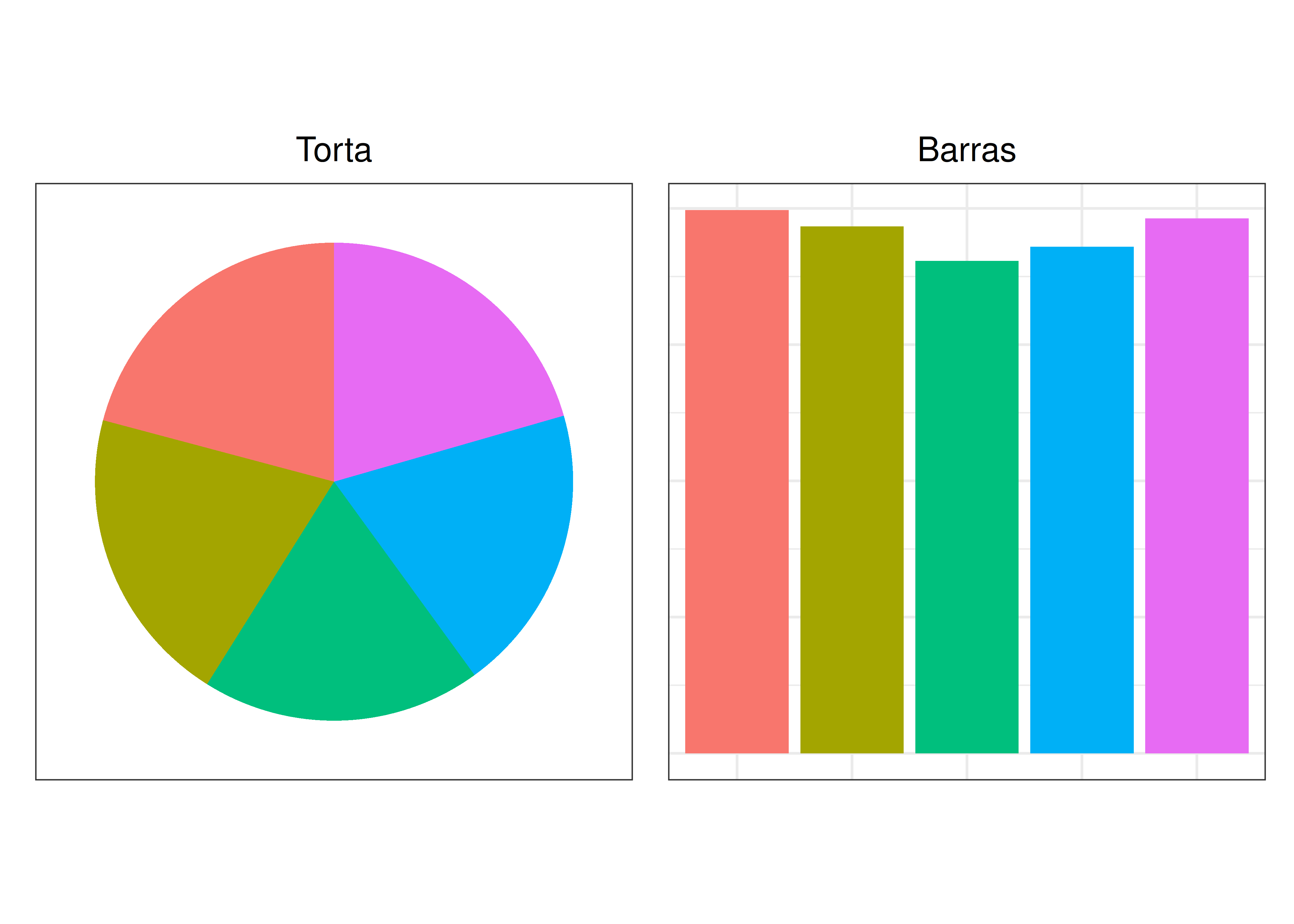
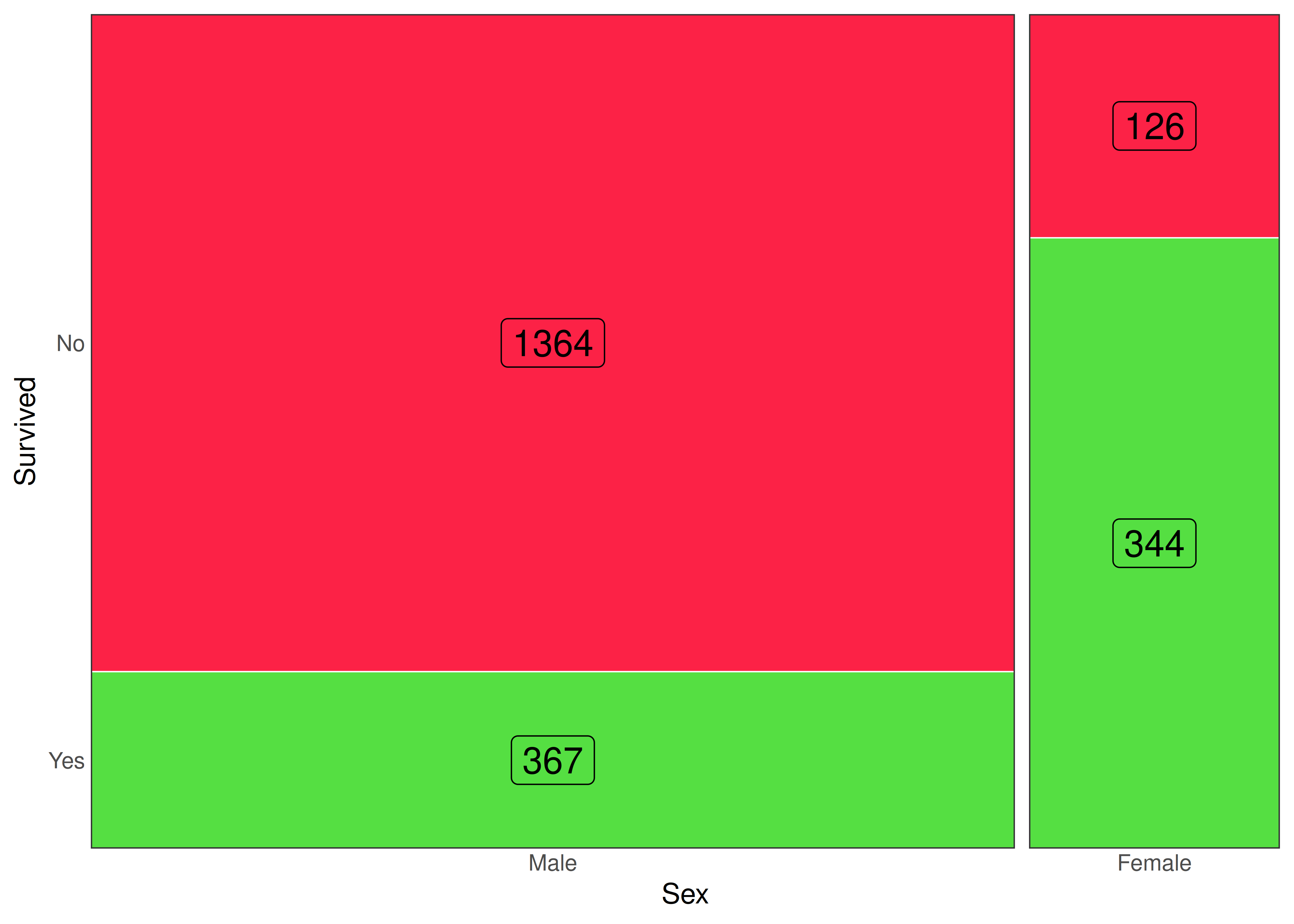
7.4 Mosaicos
Los gráficos de mosaico son alternativas a los gráficos de barras bivariados. La principal diferencia entre ambos es que, en los mosaicos, el ancho de las barras es variable y depende de la frecuencia de cada categoría ubicada sobre el eje horizontal.
Retomando los datos de Titanic, supongamos que deseamos estudiar la relación entre género del pasajero y supervivencia al hundimiento.
Construimos una tabla de contingencia y obtenemos el siguiente resultado:
Survived Male Female Total
No 1364 126 1490
Yes 367 344 711
Total 1731 470 2201
- Para trasladar esta información a un gráfico de mosaico empleamos el paquete
vcd:
library(vcd)
mosaic(
formula = ~ Sex + Survived,
data = Titanic,
direction = "v"
)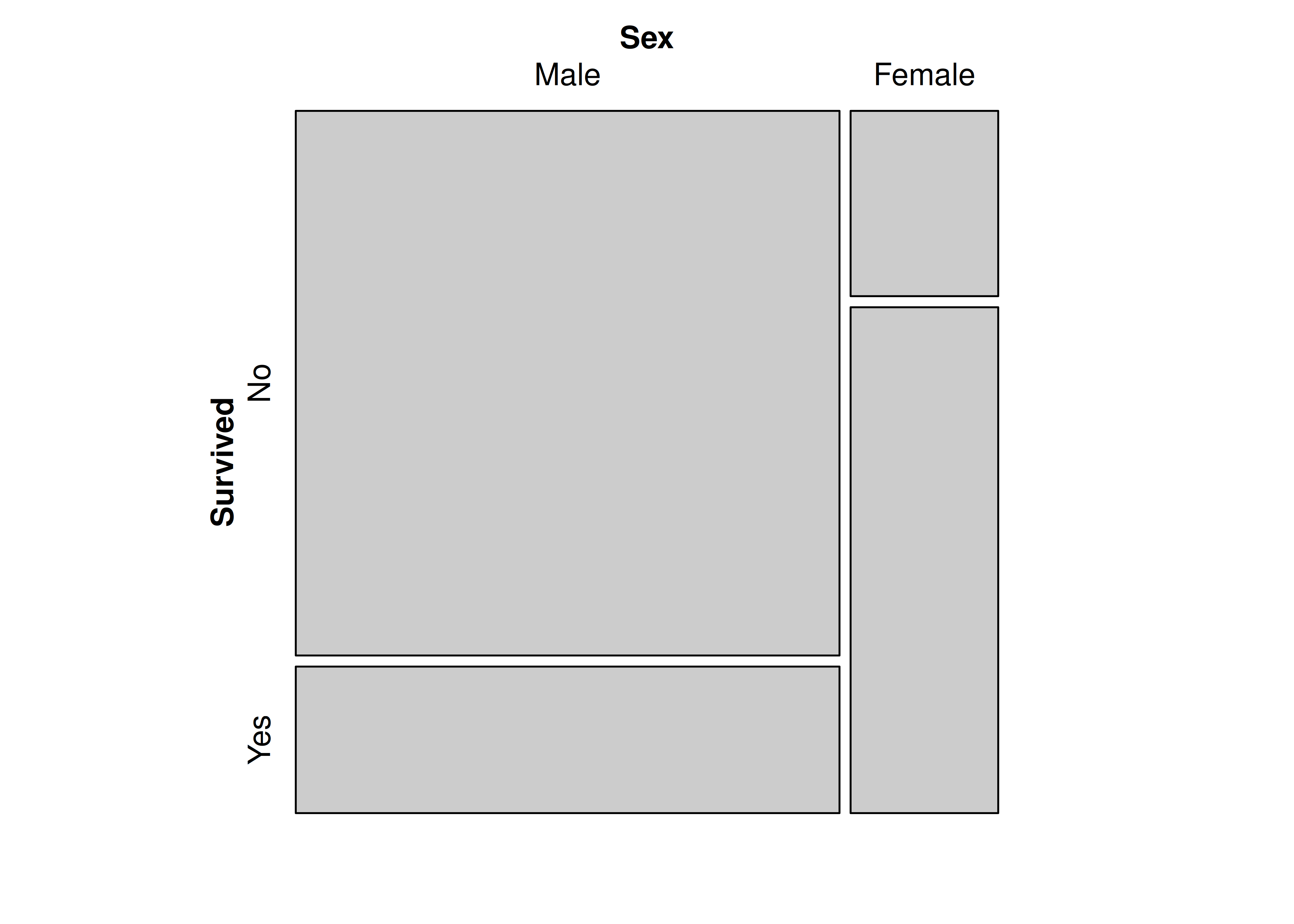
En este tipo de visualizaciones, el área de cada rectángulo puede interpretarse de dos maneras diferentes:
- Distribución conjunta: el porcentaje de área que ocupa el rectángulo asociado a las categorías \(\left( X_i, Y_j \right)\), con respecto al gráfico entero, coincide con la proporción de individuos en la base que comparten las características \(\left( X_i, Y_j \right)\).
- Distribución condicional: el porcentaje de área que ocupa el rectángulo asociado a las categorías \(\left( X_i, Y_j \right)\), dentro de la columna donde se encuentra, coincide con la proporción de individuos de la categoría \(X_i\) que poseen la característica \(Y_j\).
Por ejemplo, el área del rectángulo mayor (varones que no sobrevivieron) ocupa el \(1364/2201 \approx 62\%\) del área total y, al mismo tiempo, ocupa el \(1364/1731 \approx 79\%\) de la columna izquierda.
En términos probabilísticos, los anchos de los rectángulos son estimaciones de las probabilidades marginales \(P(sexo_i)\), mientras que las alturas son estimaciones de las probabilidades condicionales \(P(sobrevive_j / sexo_i)\).
Por lo tanto, el área de cada rectángulo representa una estimación de la probabilidad conjunta:
\[ base \times altura = P(sexo_i) \times P(sobrevive_j / sexo_i) = P(sexo_i \cap sobrevive_j) \]
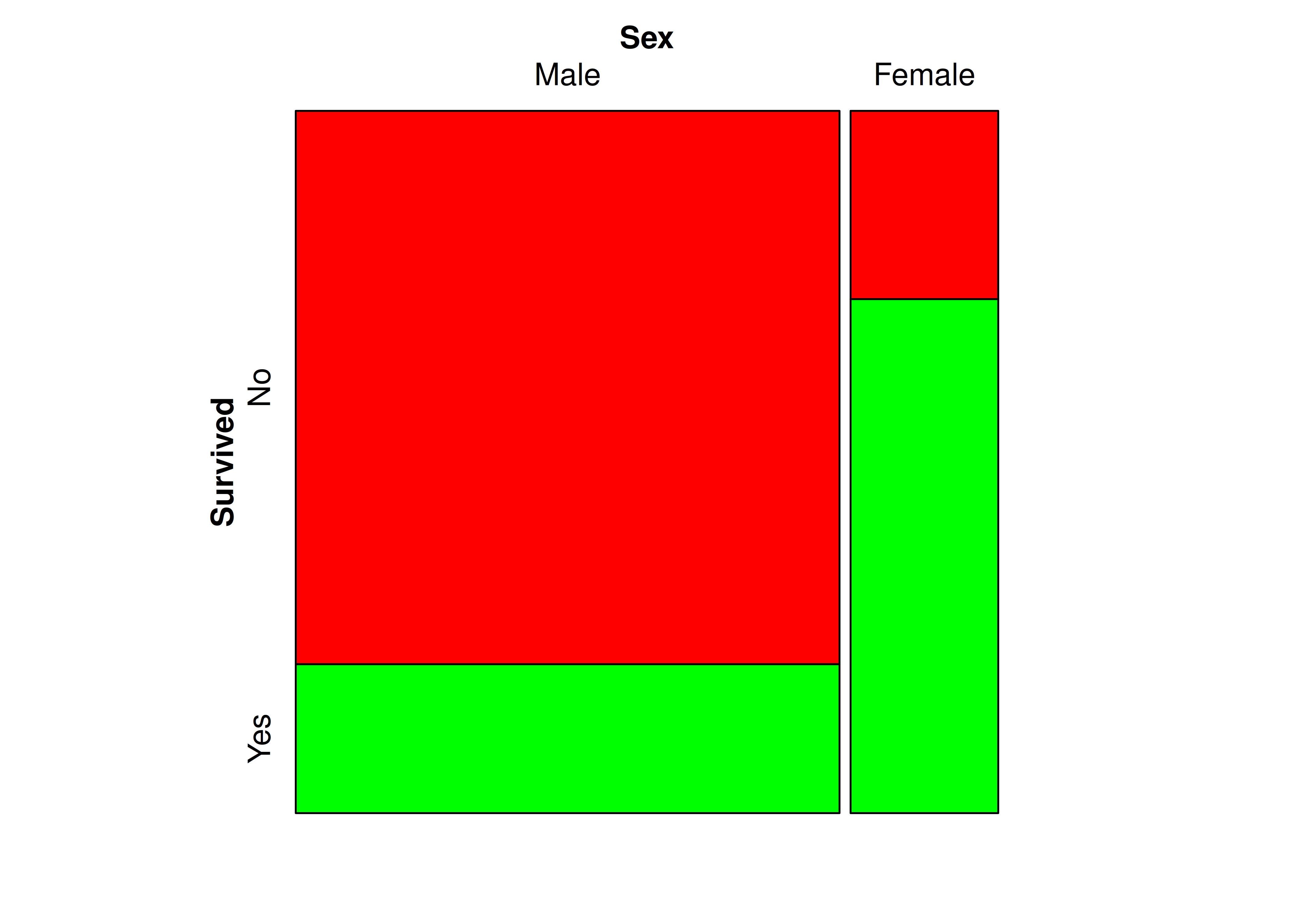
- Podemos agregar una paleta de colores para una de las dos variables graficadas, de la siguiente manera:
mosaic(
formula = ~ Sex + Survived,
data = Titanic,
direction = "v",
highlighting = "Survived",
highlighting_fill = c("red", "green")
)
7.4.1 Independencia
Otra manera de colorear los mosaicos es a partir de los residuos que se obtienen al tratar de ajustar un modelo de independencia a los datos.
Recordemos que en el Test de Independencia Chi-Cuadrado para tablas de contingencia, el valor esperado de cada celda bajo la hipótesis nula es: \[E_{ij} = \dfrac{n_{i.} \times n_{.j}}{n}\] es decir, se calcula como el producto entre los totales de su respectiva fila y columna, dividido por el total de individuos en la muestra.
A partir de este supuesto de independencia, la función
mosaic()calcula los residuos de Pearson: \[r_{ij}=\dfrac{n_{ij} - E_{ij}}{\sqrt{E_{ij}}}\].Utilizando estos residuos se obtiene la estadística \(\chi^2 = \sum\limits_{ij} r_{ij}^2\), la cual se utiliza para llevar a cabo el test de independencia.
La coloración de mosaicos en base a estos residuos se agrega mediante el argumento
shade:
mosaic(
formula = ~ Sex + Survived,
data = Titanic,
direction = "v",
shade = TRUE
)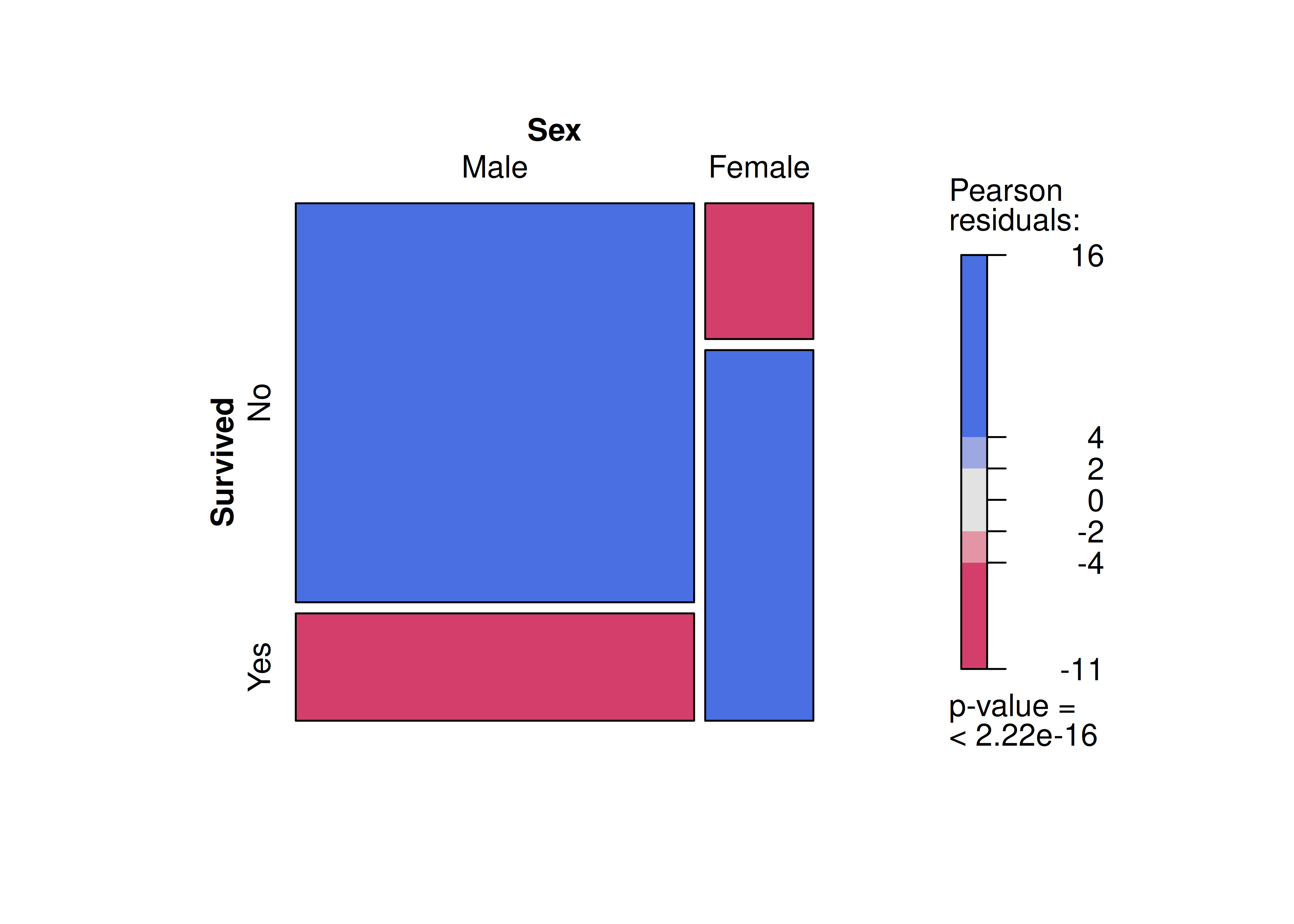
Observamos que el p-value asociado al test es prácticamente nulo, por lo tanto rechazamos la hipótesis de independencia (algo totalmente previsible dadas las características de los datos).
Por ejemplo, vemos que el residuo asociado a mujeres sobrevivientes es extremadamente alto, cercano a 16 unidades. Esto indica que las mujeres que viajaron en el Titanic salvaron su vida en mucha mayor proporción que la esperada bajo el supuesto de independencia.
Cálculo a mano del residuo:
\[E_{22} = \dfrac{n_{2.} \times n_{.2}}{n} = \dfrac{470 \times 711}{2201} \approx 152\]
\[r_{22} = \dfrac{n_{22} - E_{22}}{\sqrt{E_{22}}} = \dfrac{344 - 152}{\sqrt{152}} \approx 15.6 \]
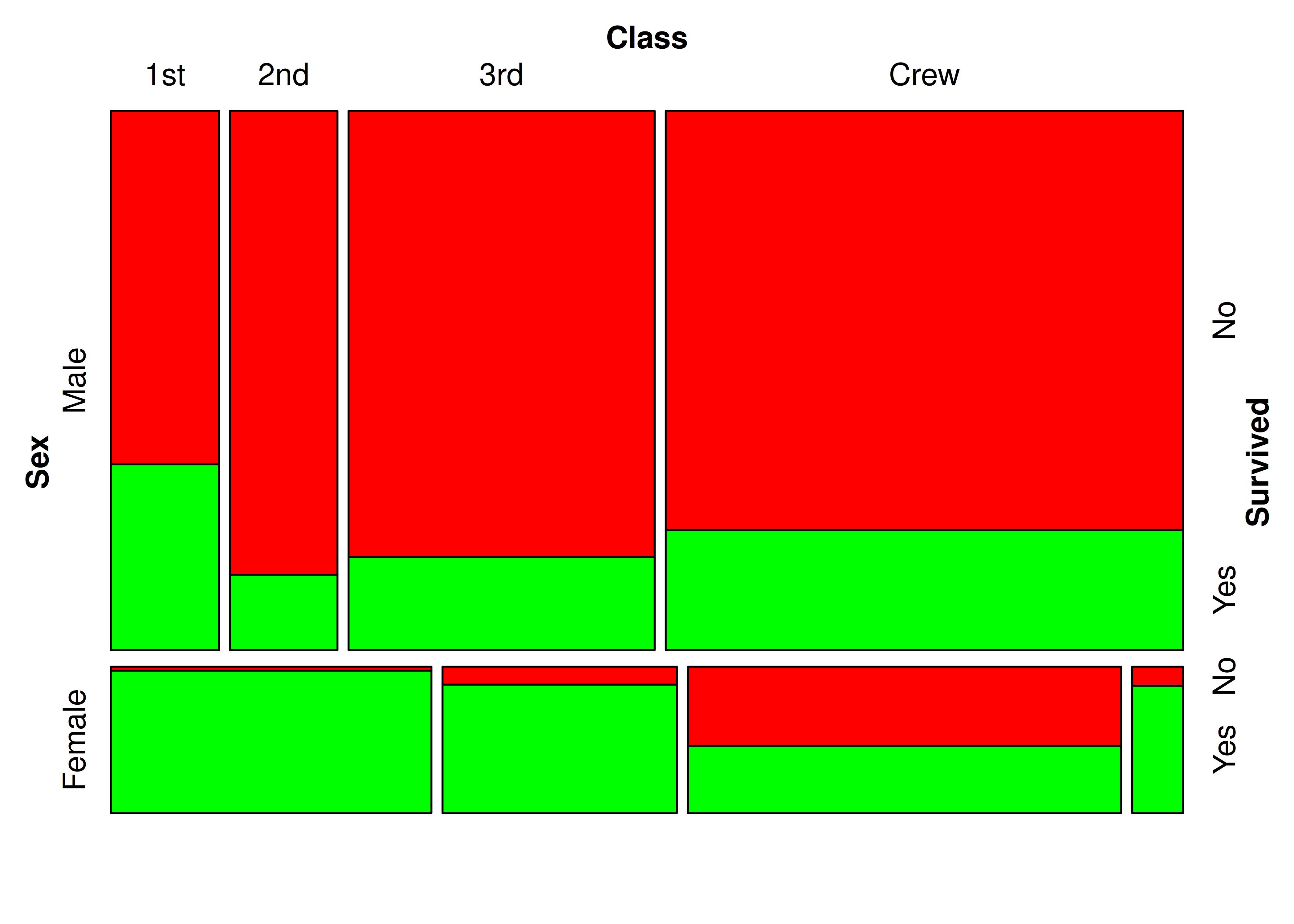
7.4.2 Más de 2 variables
Si bien las interpretaciones pueden volverse algo complejas, los gráficos de mosaico permiten analizar múltiples variables al mismo tiempo.
Veamos qué ocurre si agregamos la variable Class:
mosaic(
formula = ~ Sex + Class + Survived,
data = Titanic,
highlighting = "Survived",
highlighting_fill = c("red", "green")
)
7.4.3 Usando ggplot2
- Los gráficos de mosaico también pueden generarse a partir de
ggplot2, aunque el código necesario puede llegar a ser algo extenso:
mosaico_gg <- Titanic %>%
as.data.frame() %>%
group_by(Sex, Survived) %>%
summarise(conteo = sum(Freq), .groups = "drop") %>%
group_by(Sex) %>%
mutate(
ancho = sum(conteo),
alto = conteo / ancho,
y = 1 - (cumsum(conteo) - 0.5 * conteo) / ancho,
) %>%
ungroup()
ggplot(data = mosaico_gg) +
aes(x = Sex, y = alto, width = ancho, fill = Survived) +
geom_bar(stat = "identity", position = "fill", colour = "white", linewidth = 0.25) +
geom_label(aes(label = conteo, y = y), size = 5) +
facet_grid(~ Sex, scales = "free_x", space = "free_x") +
scale_fill_manual(values = c("#fc2246", "#55df42")) +
scale_y_continuous(
name = "Survived",
expand = c(0, 0),
breaks = mosaico_gg$y[mosaico_gg$Sex == "Male"],
labels = mosaico_gg$Survived[mosaico_gg$Sex == "Male"]
) +
theme_bw() +
theme(
line = element_blank(),
strip.text = element_blank(),
axis.ticks.length = unit(0, "pt"),
legend.position = "none"
)
7.5 Alluvial
Los diagramas alluvial (también conocidos como parallel sets) tienen un objetivo similar al de los gráficos de mosaico: representar las distribuciones conjuntas y/o condicionales entre múltiples variables categóricas.
La palabra alluvial es un término inglés relacionado a la idea de aluvión, es decir, un gran flujo de algo (por ejemplo aluvión de agua, de personas, etc.).
Estos gráficos reciben este nombre ya que las relaciones entre variables se dibujan como curvas cuyo ancho está asociado a la frecuencia observada en cada combinación de categorías, dando la sensación de “flujos” de agua que conectan grupos.
Para graficarlos utilizamos el paquete
ggalluvial. Retomamos el ejemplo del Titanic:
library(ggalluvial)
Titanic %>%
as.data.frame() %>%
ggplot() +
aes(axis1 = Sex, axis2 = Class, fill = Survived, y = Freq) +
geom_alluvium() + #flujos
geom_stratum( #columnas
fill = "black",
color = "lightgrey",
width = 0.1
) +
geom_label( #etiquetas
stat = "stratum",
aes(label = after_stat(stratum)),
fill = "white",
size = 2
) +
scale_x_discrete(limits = c("Sexo", "Clase"), expand = c(0, 0)) +
scale_y_continuous(name = "Frecuencias", breaks = seq(0, 2250, 250))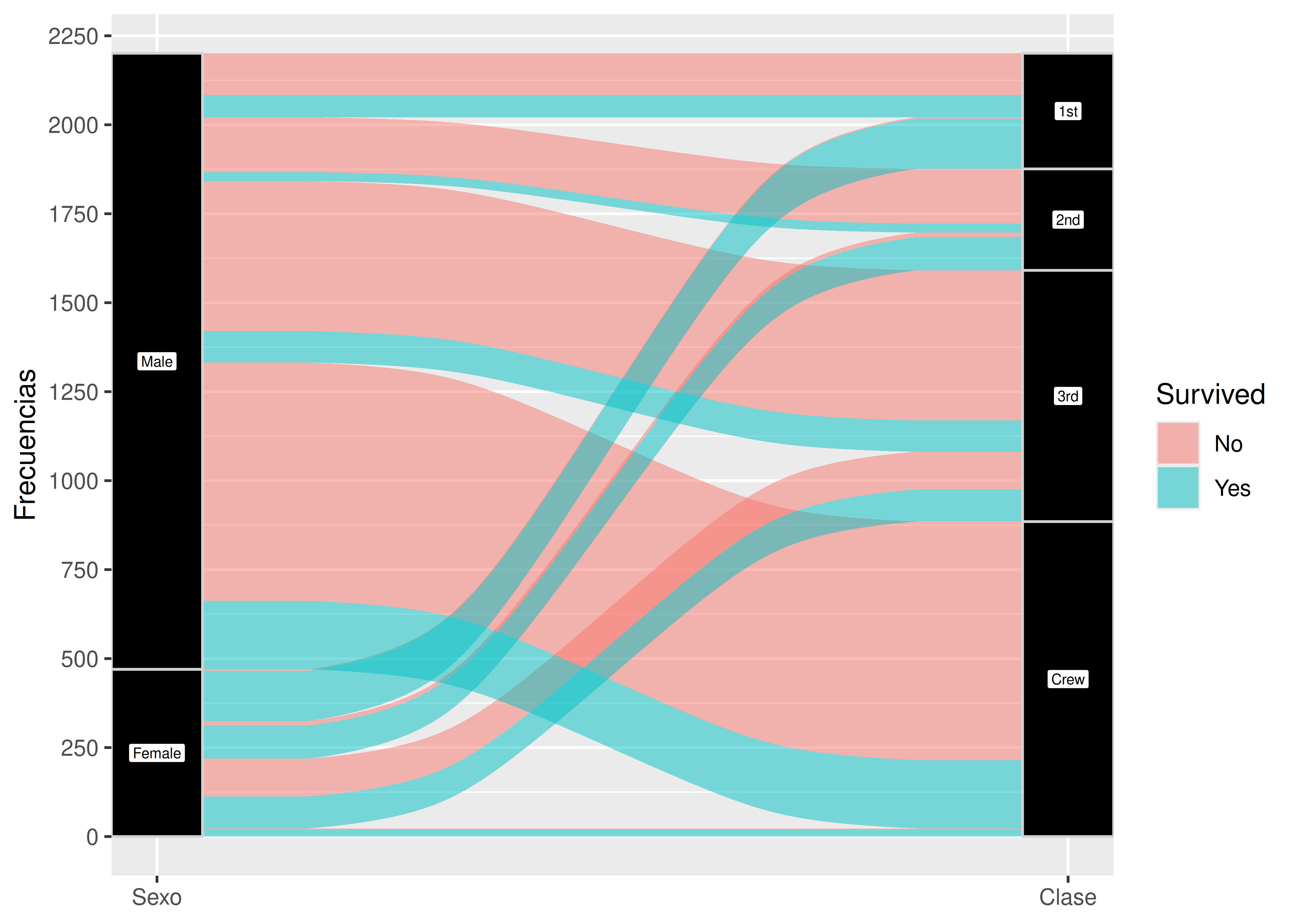
En este caso todas las alturas representan frecuencias absolutas:
- El alto del rectángulo ‘Female’ coincide con la cantidad total de pasajeras mujeres en el Titanic (470).
- El alto del flujo celeste que conecta los rectángulos
Sexo = FemaleyClase = 1stcoincide con la cantidad total de mujeres que viajaron en primera y sobrevivieron (140).
- Una alternativa al gráfico anterior consiste en incluir la supervivencia como una columna (estrato) más:
Titanic %>%
as.data.frame() %>%
ggplot() +
aes(
axis1 = Survived,
axis2 = Sex,
axis3 = Class,
fill = Survived,
y = Freq
) +
geom_alluvium() + #flujos
geom_stratum( #columnas
fill = "black",
color = "lightgrey",
width = 0.15
) +
geom_label( #etiquetas
stat = "stratum",
aes(label = after_stat(stratum)),
fill = "white",
size = 1.5
) +
scale_x_discrete(limits = c("Sobrevivió", "Sexo", "Clase"), expand = c(0, 0)) +
scale_y_continuous(name = "Frecuencias", breaks = seq(0, 2250, 250))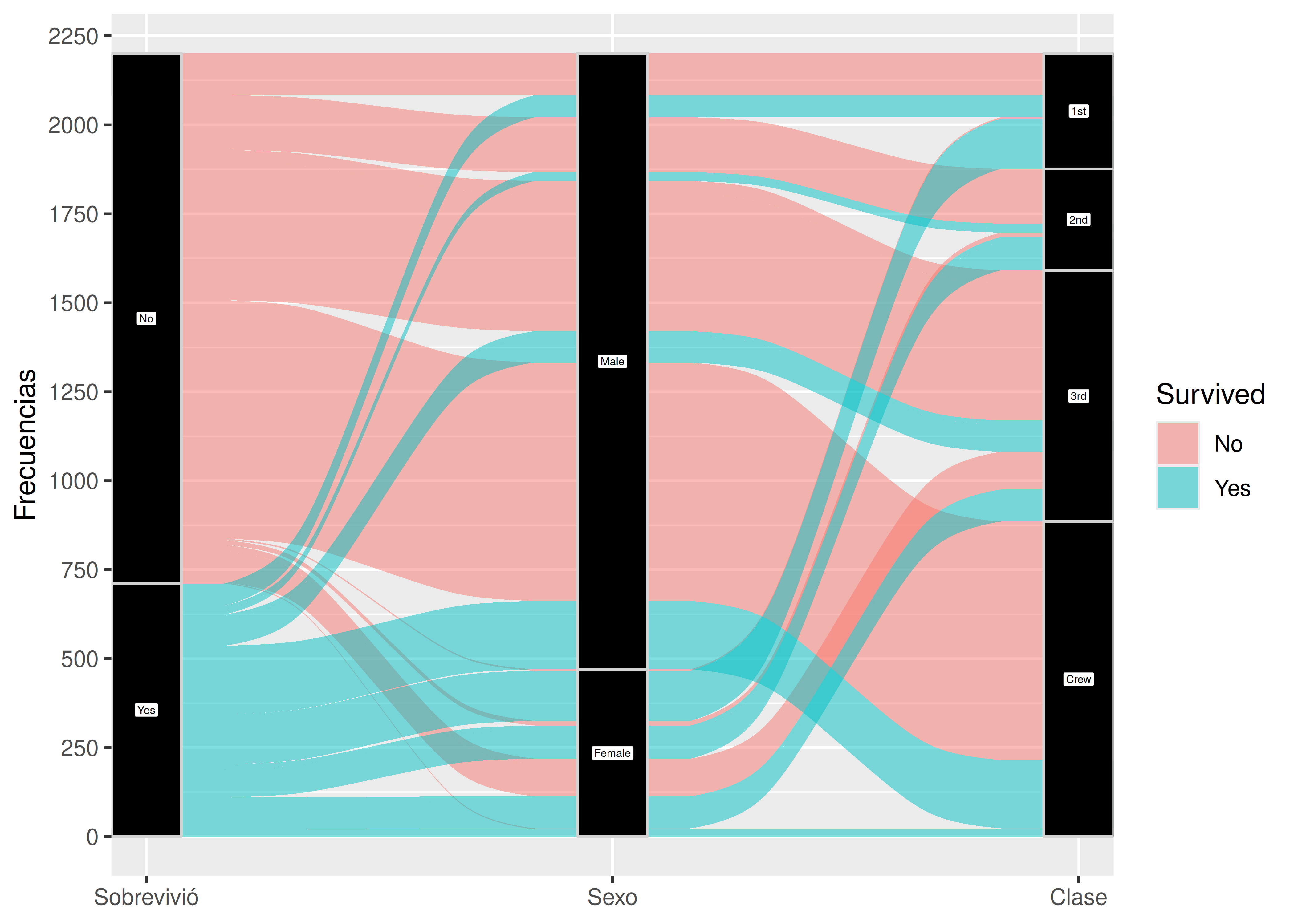
Comentarios sobre el código:
ggalluvialinteractúa de manera extraña conggplot2, por lo tanto algunas opciones asociadas a ejes y escalas pueden no funcionar como de costumbre (recomendamos leer la viñeta del paquete).- Una alternativa que vale la pena mencionar es la que ofrece el paquete
ggforcemediante su funcióngeom_parallel_sets(), la cual otorga resultados similares a los deggalluvial. - Agregando la función
coord_flip()podemos rotar los estratos para que queden ubicados de manera horizontal en vez de vertical:
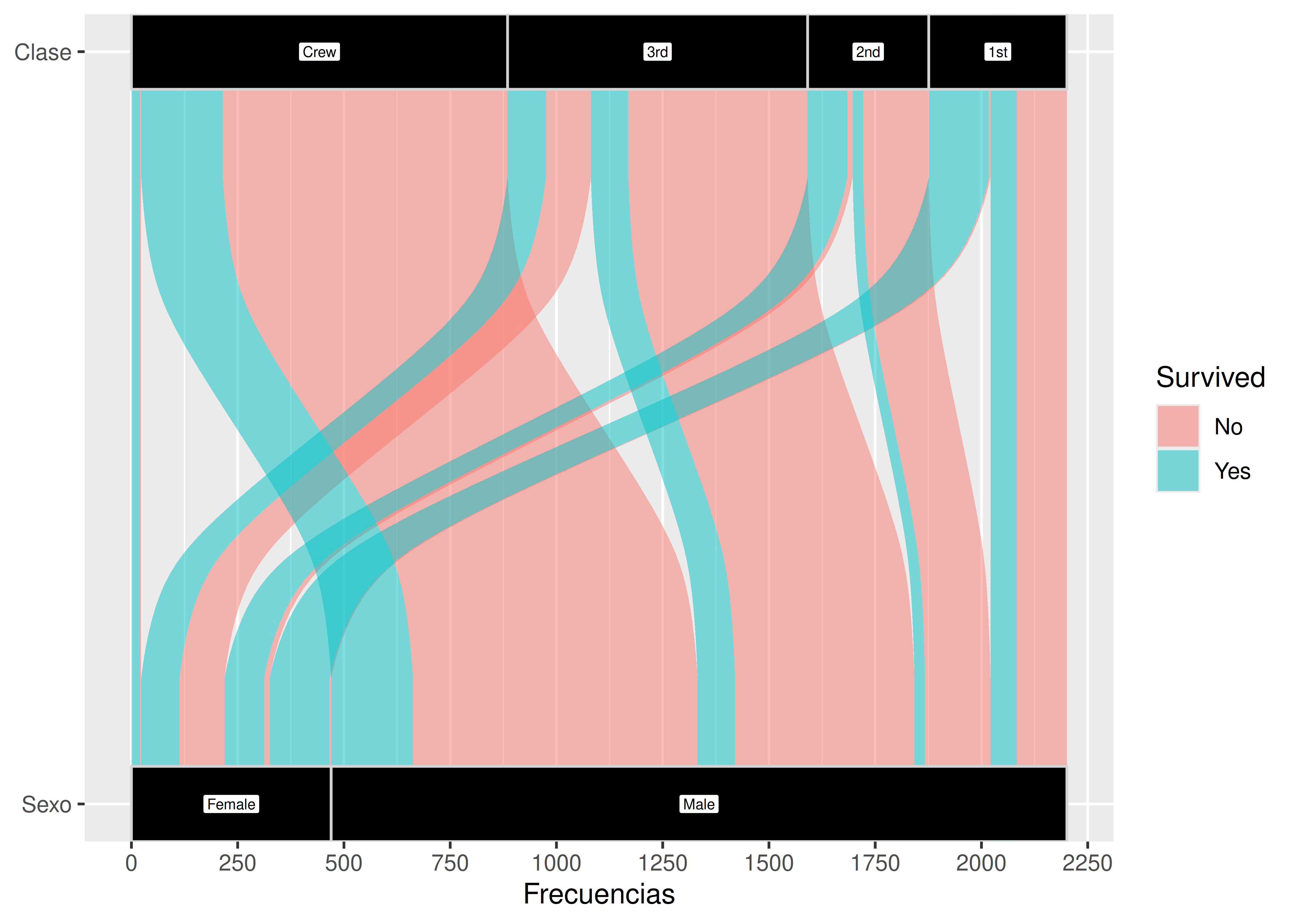
7.6 Treemaps
Un treemap es un tipo de gráfico de mosaico donde el área de cada rectángulo se asocia a su frecuencia, o bien a otra variable numérica de interés.
Esta dualidad permite que utilicemos treemaps tanto para variables respuesta categóricas (área = frecuencia) como para respuestas numéricas (área = total en cada grupo).
A diferencia de lo que ocurre con los mosaicos, donde todos los niveles de una variable se pueden combinar con todos los niveles de la otra variable, los treemaps pueden usarse aún cuando las subdivisiones de un grupo son completamente distintas a las subdivisiones del otro. De hecho, se los suele emplear específicamente cuando no tiene sentido mostrar todas las “cruzas” entre las categorías de las variables.
Al igual que en un gráfico de mosaico, en un treemap se toma un rectángulo y se lo subdivide en rectángulos más pequeños cuyas áreas representan proporciones. Sin embargo, el método por el cual se colocan los rectángulos más pequeños dentro de los más grandes es diferente: en un treemap se hace recursivamente.
Para ejemplificar los treemaps vamos a retomar los datos de cultivos que presentamos en clases anteriores. Veamos los cultivos con mayor producción en la provincia de Santa Fe durante 2019/20:
cultivos <- read_excel("../data/unidad03/cultivos.xlsx", na = "-")
santafe <- cultivos %>%
filter(
prov == "SANTA FE",
campaña == "2019/20",
!cultivo %in% c("Soja 1ra", "Soja 2da")
) %>%
group_by(cultivo) %>%
summarise(prod = sum(prod, na.rm = TRUE)) %>%
ungroup() %>%
arrange(desc(prod))
santafe# A tibble: 13 × 2
cultivo prod
<chr> <dbl>
1 Soja total 9399967
2 Maíz 7370856
3 Trigo total 4186876
4 Girasol 426328
5 Sorgo 363345
6 Arroz 149600
7 Algodón 90440
8 Cebada total 50272
9 Arveja 40530
10 Avena 36545
11 Lenteja 26664
12 Maní 20800
13 Centeno 499
- En R podemos crear un treemap de estos datos mediante el paquete
treemapify:
library(treemapify)
ggplot(data = santafe) +
aes(area = prod, fill = prod/(10^6), label = cultivo) +
geom_treemap() +
geom_treemap_text() +
labs(fill = "Producción\n(millones de Tn.)") +
scale_fill_gradient(low = "yellow", high = "forestgreen", breaks = seq(1, 9, 2))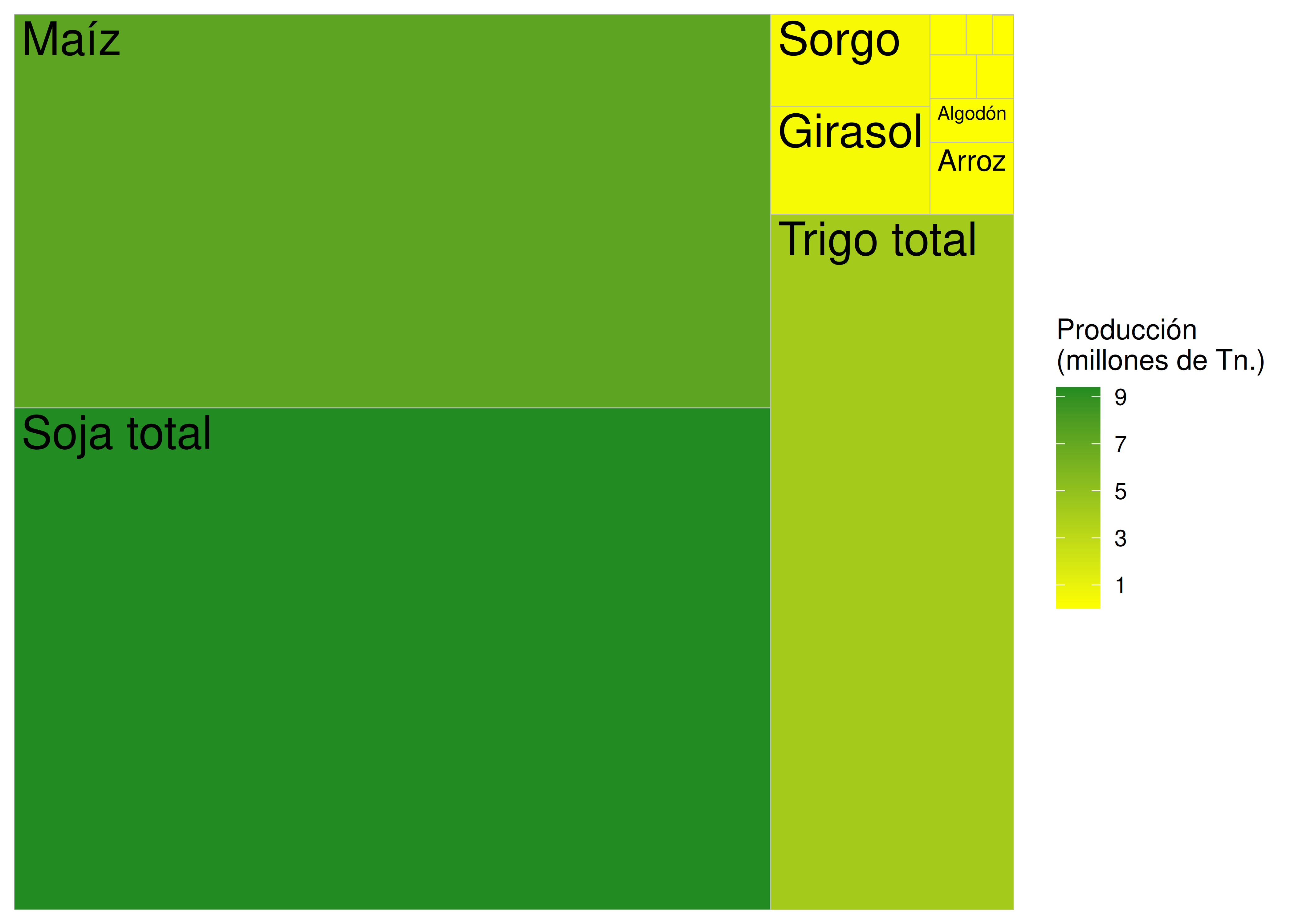
- Un problema común en este tipo de gráficos es que las categorías menos frecuentes no pueden visualizarse, tal como ocurre en este ejemplo con la cebada, la arveja, etc.
7.6.1 Treemaps dinámicos
- Una posible solución al inconveniente mencionado arriba consiste en usar el paquete
plotlypara generar treemaps dinámicos:
library(plotly)
plot_ly(
type = "treemap",
labels = santafe$cultivo,
parents = "",
values = santafe$prod
)La utilidad de los treemaps confeccionados con
plotlyse aprecia aún más cuando agregamos otra variable al gráfico.Supongamos que queremos visualizar las toneladas cosechadas de cada cultivo desagregadas según departamento.
En primer lugar, confeccionamos la base de datos necesaria:
deptos <- cultivos %>%
filter(
prov == "SANTA FE",
campaña == "2019/20",
!cultivo %in% c("Soja 1ra", "Soja 2da")
) %>%
group_by(dpto, cultivo) %>%
summarise(
prod = sum(prod, na.rm = TRUE),
.groups = "drop"
)
deptos# A tibble: 134 × 3
dpto cultivo prod
<chr> <chr> <dbl>
1 9 DE JULIO Algodón 64400
2 9 DE JULIO Avena 0
3 9 DE JULIO Girasol 51230
4 9 DE JULIO Maíz 174240
5 9 DE JULIO Soja total 269220
6 9 DE JULIO Sorgo 29760
7 9 DE JULIO Trigo total 233750
8 BELGRANO Avena 1081
9 BELGRANO Cebada total 6696
10 BELGRANO Centeno 499
# ℹ 124 more rows
- En segundo lugar, agregamos los totales por departamento y luego asignamos etiquetas únicas a cada registro de la base (en general, este es el paso más complejo del proceso). La base resultante se ve así:
deptos_tot <- deptos %>%
#Calculo totales por depto
group_by(dpto) %>%
summarise(prod = sum(prod, na.rm = TRUE)) %>%
ungroup() %>%
rename(cultivo = dpto) %>%
mutate(dpto = "Total Santa Fe") %>%
#Uno con dataset original
bind_rows(deptos) %>%
#Genero etiquetas únicas
mutate(etiq = ifelse(dpto != "Total Santa Fe", paste0(cultivo, "_", dpto), cultivo))
deptos_tot# A tibble: 153 × 4
cultivo prod dpto etiq
<chr> <dbl> <chr> <chr>
1 9 DE JULIO 822600 Total Santa Fe 9 DE JULIO
2 BELGRANO 1127600 Total Santa Fe BELGRANO
3 CASEROS 1541017 Total Santa Fe CASEROS
4 CASTELLANOS 1999437 Total Santa Fe CASTELLANOS
5 CONSTITUCION 1159655 Total Santa Fe CONSTITUCION
6 GARAY 90715 Total Santa Fe GARAY
7 GENERAL LOPEZ 5036462 Total Santa Fe GENERAL LOPEZ
8 GENERAL OBLIGADO 535935 Total Santa Fe GENERAL OBLIGADO
9 IRIONDO 1505450 Total Santa Fe IRIONDO
10 LA CAPITAL 148791 Total Santa Fe LA CAPITAL
# ℹ 143 more rows- Ahora sí estamos en condiciones de graficar el treemap bivariado:
plot_ly(
type = 'treemap',
labels = deptos_tot$etiq, #variable de menor jerarquía (etiqueta única)
parents = deptos_tot$dpto, #variable de mayor jerarquía
values = deptos_tot$prod, #tamaño de cada rectangulo
hoverinfo = "label+value+percent parent+percent root",
textinfo = "label+value+percent parent+percent root"
) %>%
add_trace(branchvalues = "total", name = "")Moviendo el mouse sobre el treemap, podemos enterarnos que, por ejemplo, la producción del departamento Rosario representa sólo el 2% del total provincial.
Haciendo click en Rosario, observamos que de las 546.155 toneladas producidas allí, el 36% corresponde a soja, lo que equivale al 1% de la producción de Santa Fe (abarcando todos los cultivos).
7.6.2 Ejercicio
- Tomar los datos del Titanic y tratar de replicar este treemap dinámico que muestra los porcentajes de supervivencia según la clase en la que viajaba cada pasajero:
7.7 Diagramas de Venn
Los diagramas de Venn son un tipo de gráfico útil para mostrar visualmente relaciones lógicas (unión, intersección, complemento, etc.) entre los elementos de diferentes conjuntos.
Pueden ser utilizados de dos maneras:
- Para contabilizar la cantidad de observaciones que presentan (o no) 2 o más características de interés. En este caso su objetivo es el de visualizar proporciones anidadas, con lo cual puede tomarse como una alternativa a los gráficos presentados anteriormente para tal fin: mosaicos, treemaps y alluvial.
- Para mostrar específicamente qué individuos poseen (o no) 2 o más características de interés. En este caso no nos interesa comparar cantidades ni proporciones, sino cuáles son las observaciones que figuran en cada región.
7.7.1 Proporciones anidadas
- Empleamos el paquete
VennDiagrampara mostrar qué porcentaje de los cultivos verifican las siguientes 3 condiciones: la superficie sembrada es mayor a 1000 hectáreas, la producción obtenida es menor a 1500 toneladas, y el rendimiento es mayor a 2000 kg. por hectárea.
library(grid)
library(VennDiagram)
#Creamos un dataset sin datos faltantes
cultivos_sinNA <- cultivos %>%
filter(
!is.na(sup_cosechada),
!is.na(prod),
!is.na(rend)
)
#Armamos una lista con individuos que verifican las 3 condiciones a comparar
lista <- list(
grupo1 = which(cultivos_sinNA$sup_sembrada > 1000),
grupo2 = which(cultivos_sinNA$prod < 1500),
grupo3 = which(cultivos_sinNA$rend > 2000)
)
#Generamos diagrama de Venn
diagrama <- venn.diagram(
x = lista,
category.names = c(
"Sup. > 1000 ha.",
"Prod. < 1500 tn.",
"Rendimiento > 2000 kg. por ha."
),
fill = c("red", "blue", "green"),
filename = NULL,
print.mode = "percent" #para ver % en vez de cantidades
)
grid.draw(diagrama)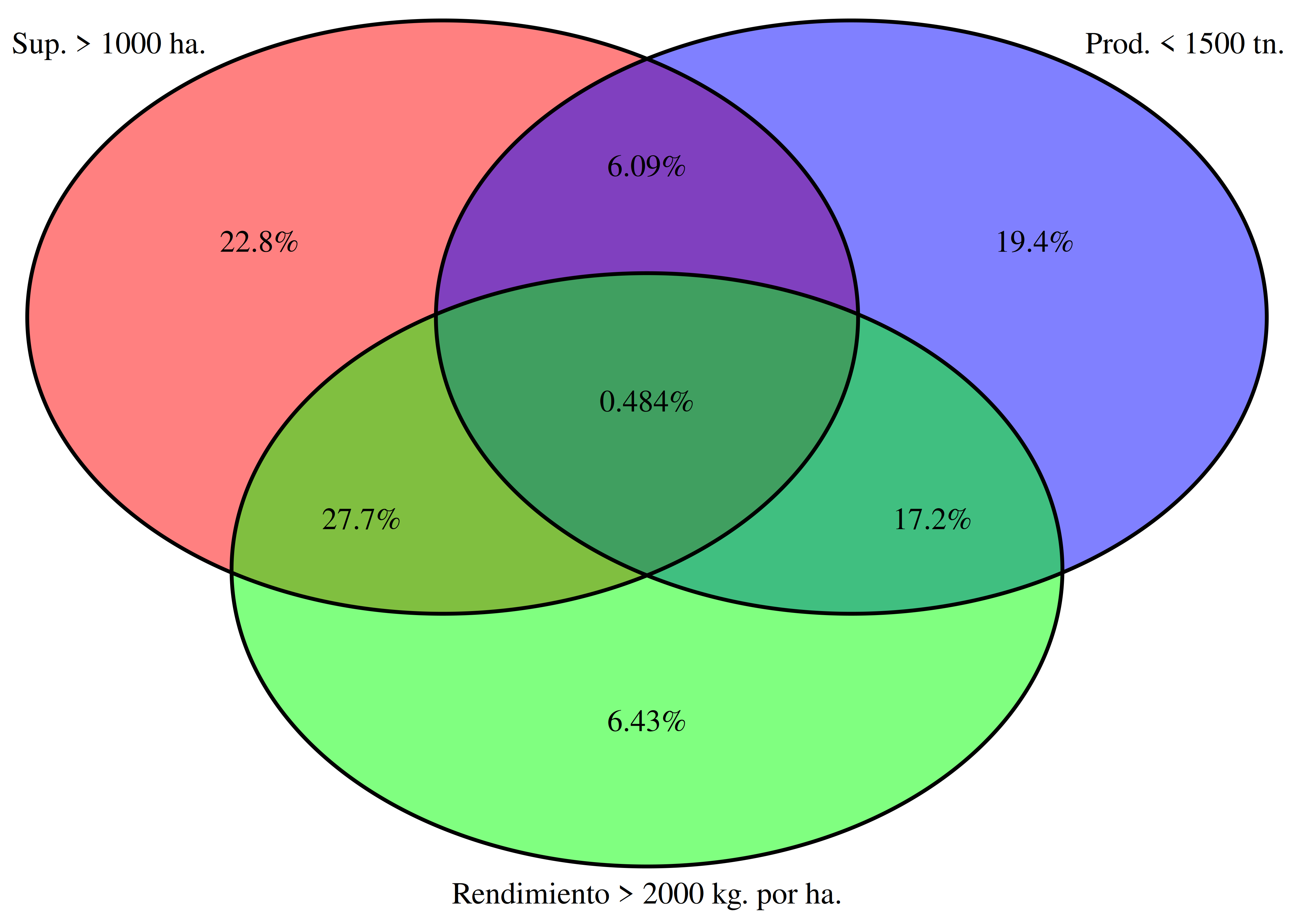
7.7.2 Características compartidas entre individuos
- En este caso usamos el paquete
ggvenn, una extensión deggplot2, para hacer un diagrama clásico de Venn que compara un conjunto de individuos según 2 variables:
library(ggvenn)
lista <- list(
Fútbol = c("Argentina", "Alemania", "Uruguay", "Brasil",
"España", "Italia", "Inglaterra", "Francia"),
Basket = c("Argentina", "Alemania", "Brasil", "España",
"Estados Unidos", "Unión Soviética", "Yugoslavia")
)
ggvenn(
data = lista,
fill_color = c("red", "blue"),
show_elements = TRUE,
label_sep = "\n",
text_size = 5
) +
ggtitle("Campeones Mundiales de...\n") +
theme(title = element_text(size = 14))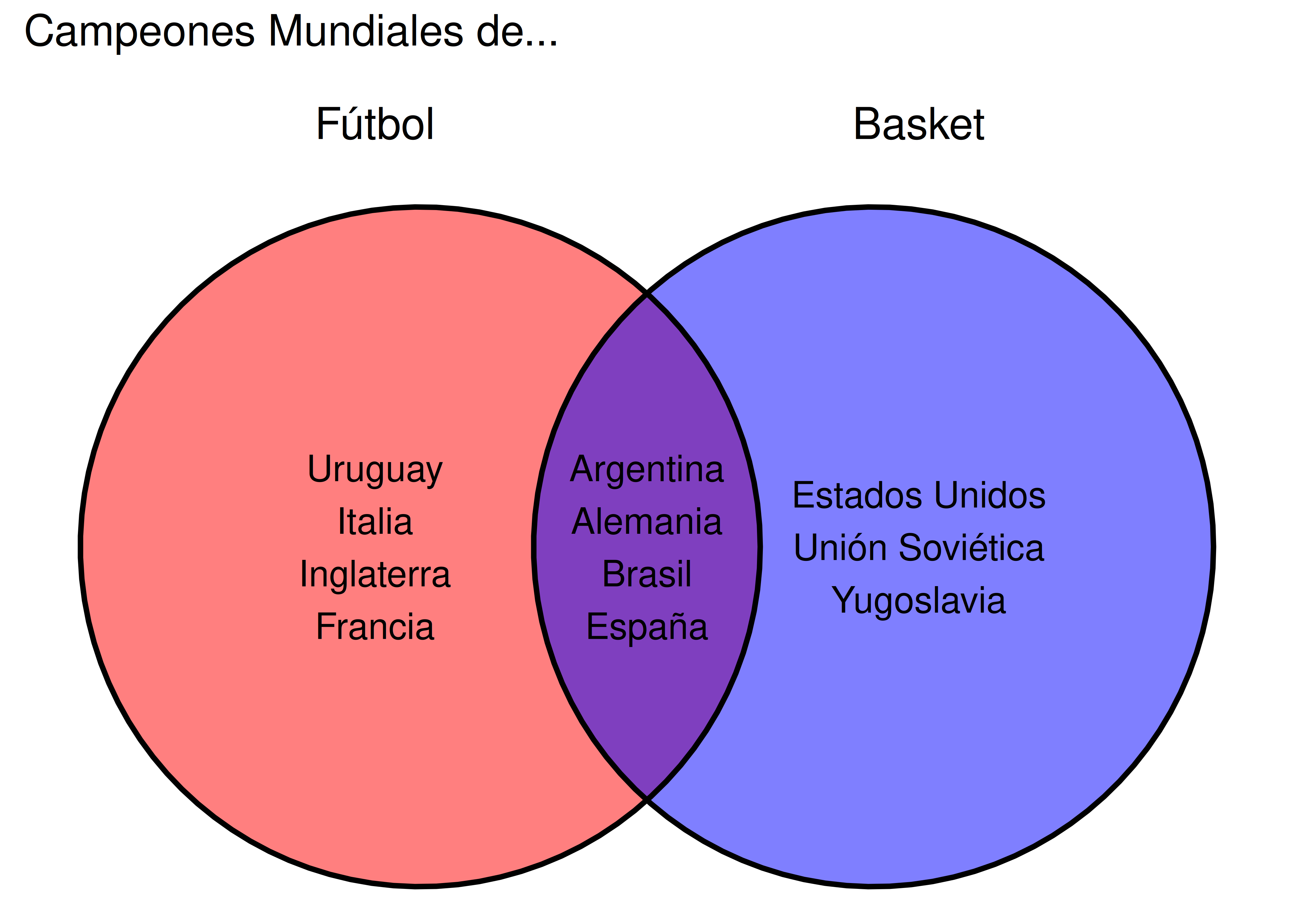
7.8 Nubes de Palabras
En los últimos tiempos se han desarrollado herramientas muy interesantes y sofisticadas para el trabajo con datos de tipo textual. En esta sección veremos dos de ellas, que suelen estar presentes en análisis exploratorios iniciales del conjunto de documentos analizados:
- Estudio de las frecuencias de palabras: se contabiliza cuántas veces aparece cada palabra para poder identificar a las más frecuentes. Los resultados suelen representarse en las llamadas nubes de palabras, las cuales generan una visualización atractiva de los vocablos presentes.
- Estudio de la co-ocurrencia de palabras: se estudia la asociación que puede haber entre palabras mediante el análisis de cuántas veces aparecen juntas (o no) en los documentos. Los resultados suelen representarse en grafos.
Ambos tipos de análisis pueden utilizarse para comparar grupos de documentos, por ejemplo de distintos autores, diferentes estilos literarios, etc.
Vamos a ejemplificar el uso de estas herramientas analizando tweets (posteos en la red social Twitter, ahora conocida como X). En particular, nos concentraremos en tweets que incluyan el hashtag
#messipublicados entre el 9 y el 13 de diciembre de 2022.La descarga de la base se realizó el día 13/12/2022, después del partido entre Argentina y Croacia por las semifinales del Mundial de Fútbol de Qatar, en el que nuestra selección ganó por 3 a 0.
Para obtener estos datos se utilizó el paquete de R
rtweet, el cual se conecta con la API de Twitter y permite descargar tweets que coincidan con los criterios de búsqueda que nos interesen. Desde que Elon Musk compró Twitter, el acceso a la API se encuentra restringido y el paquetertweetha dejado de funcionar, por lo que hoy en día no es tan sencillo acceder a este tipo de información libremente.Una vez descargados los tweets es necesario someterlos a un extenso proceso de depuración, el cual incluye filtrado de spam, unificación de criterios de escritura de palabras, borrado de términos no importantes (artículos, preposiciones, conectores, etc.) y muchas otras cuestiones relativas a la limpieza de la base.
El resultado de este proceso se encuentra almacenado en el archivo
tweets.RData, el cual contiene información sobre más de 15.000 tweets con el hashtag#messipublicados en las fechas mencionadas. Sus primeras 10 filas lucen así:
load("../data/unidad03/tweets.RData")
head(tweets, 10)# A tibble: 10 × 7
id created_at text retweet_count favorite_count source limpios
<chr> <dttm> <chr> <int> <int> <chr> <chr>
1 160127… 2022-12-09 18:02:24 "Aho… 0 0 Twitt… ahora …
2 160127… 2022-12-09 18:02:36 "Vam… 0 0 Twitt… vamos …
3 160127… 2022-12-09 18:02:44 "Que… 0 1 Twitt… gane e…
4 160127… 2022-12-09 18:02:52 "Ser… 0 0 Twitt… sera v…
5 160127… 2022-12-09 18:02:59 "#Me… 0 0 Twitt… merece…
6 160127… 2022-12-09 18:03:07 "Que… 1 1 Twitt… quedam…
7 160127… 2022-12-09 18:03:10 "Sol… 0 0 Twitt… solo q…
8 160127… 2022-12-09 18:03:12 "@Ma… 0 0 Twitt… result…
9 160127… 2022-12-09 18:03:27 "Tra… 0 6 Twitt… tranqu…
10 160127… 2022-12-09 18:03:48 "Tod… 0 0 Twitt… puesto…7.8.1 Frecuencias y nubes de palabras
- Vamos a detectar cuáles son las palabras más frecuentes en esta base. Mediante la función
unnest_tokens()del paquetetidytextextraemos las palabras que componen cada tweet y ubicamos cada una de ellas en las filas de un nuevo dataset. Luego agregamos su frecuencia absoluta y nos quedamos con aquellos términos con al menos 4 caracteres:
library(tidytext)
frecuencias <- tweets %>%
unnest_tokens(palabras, limpios) %>%
count(palabras, sort = TRUE, name = "frec") %>%
filter(nchar(palabras) > 3) %>%
arrange(-frec)
frecuencias# A tibble: 16,340 × 2
palabras frec
<chr> <int>
1 argentina 2355
2 messi 2044
3 vamos 1340
4 mundial 1132
5 bobo 1117
6 mundo 882
7 mejor 839
8 partido 837
9 futbol 741
10 final 721
# ℹ 16,330 more rows
Para comparar las frecuencias de estos términos podríamos emplear un gráfico de barras, pero en este caso optamos por una nube de palabras. La idea de ambas visualizaciones es la misma: representar palabras en un gráfico, donde el tamaño o color de cada una depende de cierta variable numérica (generalmente la frecuencia relativa o absoluta de la palabra dentro del texto analizado).
Para crear una nube de palabras con nuestro ejemplo usamos el paquete
ggwordcloud. Se incluyen únicamente aquellos términos que hayan aparecido más de 100 veces:
library(ggwordcloud)
frecuencias %>%
filter(frec > 100) %>%
ggplot() +
aes(label = palabras, size = frec, color = frec) +
geom_text_wordcloud(eccentricity = 1) + #forma de la elipse
scale_size_area(max_size = 20) +
scale_color_gradient(low = "red", high = "darkred") +
theme_minimal()
7.8.2 Co-ocurrencia, asociación entre palabras y grafos
Otro análisis básico para datos textuales consiste en identificar cuáles son los pares de palabras que aparecen juntas frecuentemente (no necesariamente una después de la otra, sino en los mismos documentos).
Para contar la cantidad de tweets en donde aparece cada par de palabras, vamos a valernos del paquete
widyry la funciónpairwise_count():
palabras_tweet <- tweets %>%
select(id, limpios) %>%
unnest_tokens(palabras, limpios) %>%
filter(nchar(palabras) > 3)
pares_frec <- pairwise_count(palabras_tweet, palabras, id, sort = TRUE)
pares_frec# A tibble: 756,550 × 3
item1 item2 n
<chr> <chr> <dbl>
1 miras bobo 472
2 bobo miras 472
3 argentina vamos 445
4 vamos argentina 445
5 messi argentina 433
6 argentina messi 433
7 bajos paises 429
8 paises bajos 429
9 bobo anda 353
10 anda bobo 353
# ℹ 756,540 more rowsLos binomios más comunes son “miras bobo” (de la famosa frase de Messi, qué mirás bobo, andá pa’ allá bobo), “vamos argentina”, “paises bajos”, etc.
Podemos buscar palabras de nuestro interés para saber con qué términos se asocian frecuentemente:
filter(pares_frec, item1 == "dibu")# A tibble: 887 × 3
item1 item2 n
<chr> <chr> <dbl>
1 dibu martinez 66
2 dibu messi 54
3 dibu argentina 51
4 dibu penales 24
5 dibu gracias 23
6 dibu semifinales 23
7 dibu vamos 19
8 dibu seleccion 18
9 dibu paises 17
10 dibu bajos 17
# ℹ 877 more rowsfilter(pares_frec, item1 == "scaloneta") # A tibble: 291 × 3
item1 item2 n
<chr> <chr> <dbl>
1 scaloneta argentina 19
2 scaloneta vamos 15
3 scaloneta seleccion 9
4 scaloneta mundo 7
5 scaloneta messi 6
6 scaloneta final 5
7 scaloneta qatar 5
8 scaloneta juega 5
9 scaloneta mundial 4
10 scaloneta pase 4
# ℹ 281 more rowsfilter(pares_frec, item1 == "muchachos")# A tibble: 409 × 3
item1 item2 n
<chr> <chr> <dbl>
1 muchachos vamos 30
2 muchachos argentina 23
3 muchachos gracias 20
4 muchachos ilusionar 19
5 muchachos volvimos 18
6 muchachos ahora 14
7 muchachos mundial 11
8 muchachos campeon 11
9 muchachos quiero 10
10 muchachos ganar 9
# ℹ 399 more rows
Un par de palabras que ocurren muchas veces juntas podrían no estar específicamente asociadas entre sí, sobre todo si una de ellas posee alta frecuencia en términos generales (por ej., arriba vimos que la palabra argentina aparece muy asociada a dibu, scaloneta y muchachos).
Para saber qué par de palabras se asocian entre sí, pero generalmente a ninguna otra, se emplea un coeficiente de asociación entre variables binarias llamado \(\phi\).
Podemos calcular este coeficiente para cada par de palabras con la función
pairwise_cor().
pares_corr <- palabras_tweet %>%
group_by(palabras) %>%
filter(n() >= 20) %>%
pairwise_cor(palabras, id, sort = TRUE)
filter(pares_corr, item1 == "muchachos") # A tibble: 881 × 3
item1 item2 correlation
<chr> <chr> <dbl>
1 muchachos ilusionar 0.356
2 muchachos volvimos 0.355
3 muchachos tercera 0.159
4 muchachos podemos 0.100
5 muchachos gracias 0.0889
6 muchachos cielo 0.0822
7 muchachos vamos 0.0766
8 muchachos felices 0.0694
9 muchachos campeon 0.0592
10 muchachos ahora 0.0565
# ℹ 871 more rows
Arriba apreciamos las palabras que mayor correlación poseen con muchachos: desaparecieron términos genéricos como vamos o argentina, pero se mantuvieron palabras como volvimos o ilusionar. Esto se debe a que estas últimas generalmente sólo aparecen cuando alguien escribe la letra de la famosa canción, y no resultan tan comunes en otros contextos.
Una visualización interesante de toda esta información se logra con un grafo, el cual se define como una red de nodos conectados. En este caso, cada palabra es un nodo.
La línea que une dos nodos representa la asociación entre las correspondientes palabras: a mayor oscuridad en la línea, mayor es la fuerza de asociación; palabras no conectadas no están asociadas.
Para esta tarea hacemos uso de los paquetes
igraphyggraph:
set.seed(2022)
pares_corr %>%
filter(correlation > 0.2) %>%
graph_from_data_frame() %>%
ggraph(layout = "fr") + # Algoritmo de Fruchterman-Reingold para posicionar los nodos
geom_edge_link(aes(edge_alpha = correlation), show.legend = FALSE) +
geom_node_point(color = "skyblue", size = 3) +
geom_node_text(aes(label = name), repel = TRUE, size = 3) +
theme_void()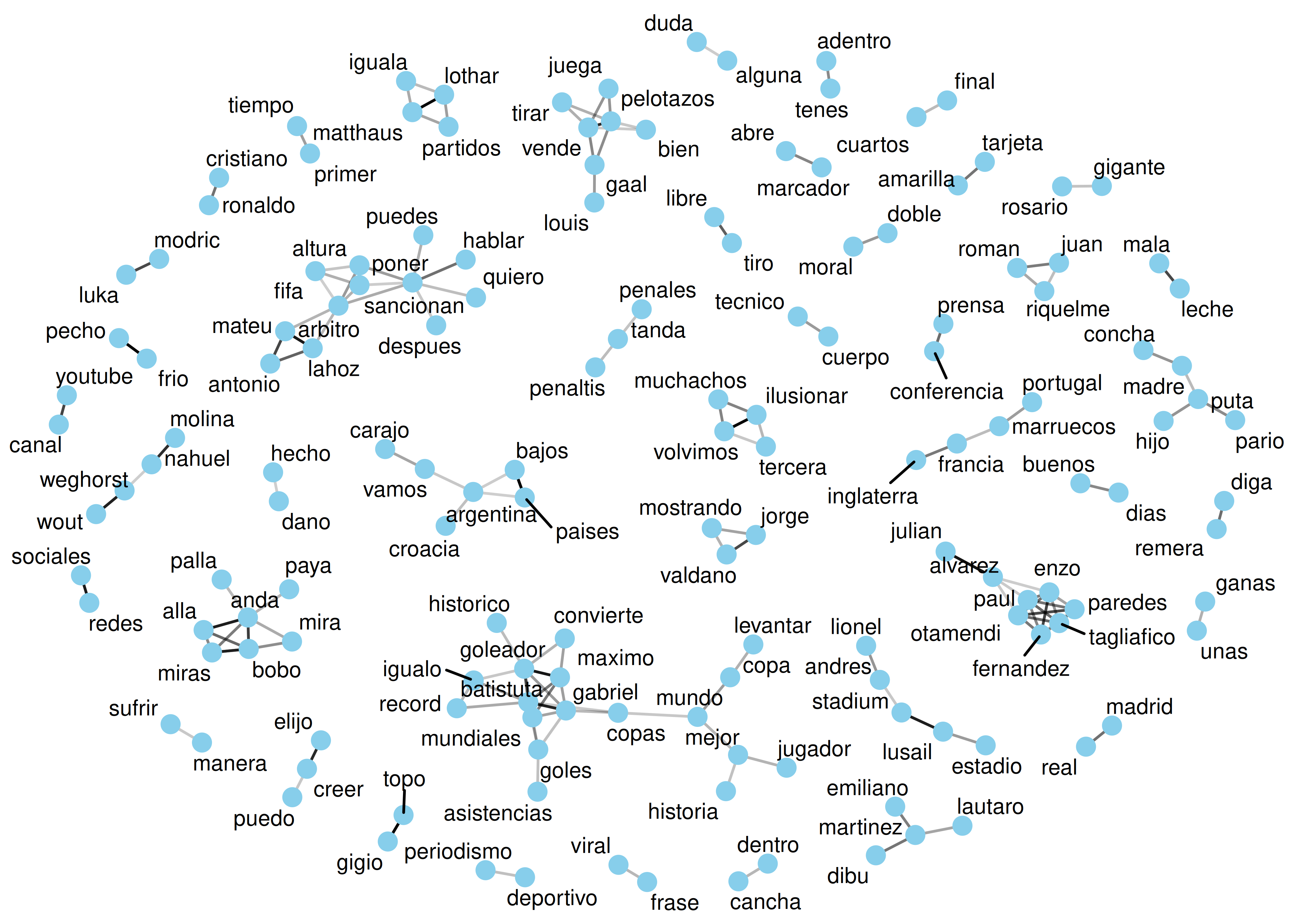
Importante
Parte del material sobre nubes de palabras y grafos es de la autoría del Prof. Marcos Prunello.