2 Buenas Prácticas para la Visualización de Datos
Análisis Exploratorio de Datos | Licenciatura en Estadística | FCEyE | UNR
2.1 Principio de la tinta proporcional
En ciertos gráficos, los valores representados se asocian a dos elementos distintos de la visualización empleada. Pensemos por ejemplo en un gráfico de barras: el valor que le corresponde a cada una se puede transmitir a través de la escala del eje Y (o del eje X, si usamos barras horizontales), pero también se transmite visualmente mediante la longitud de la barra.
En estos casos, si elegimos iniciar el eje en un valor distinto de 0, la longitud de la barra puede no representar fielmente el valor que le corresponde, creando una inconsistencia en el mensaje transmitido.
Ante esta situación, ciertos autores proponen respetar el “principio de la tinta proporcional”: las áreas sombreadas en un gráfico deben ser proporcionales a los valores numéricos que representan.
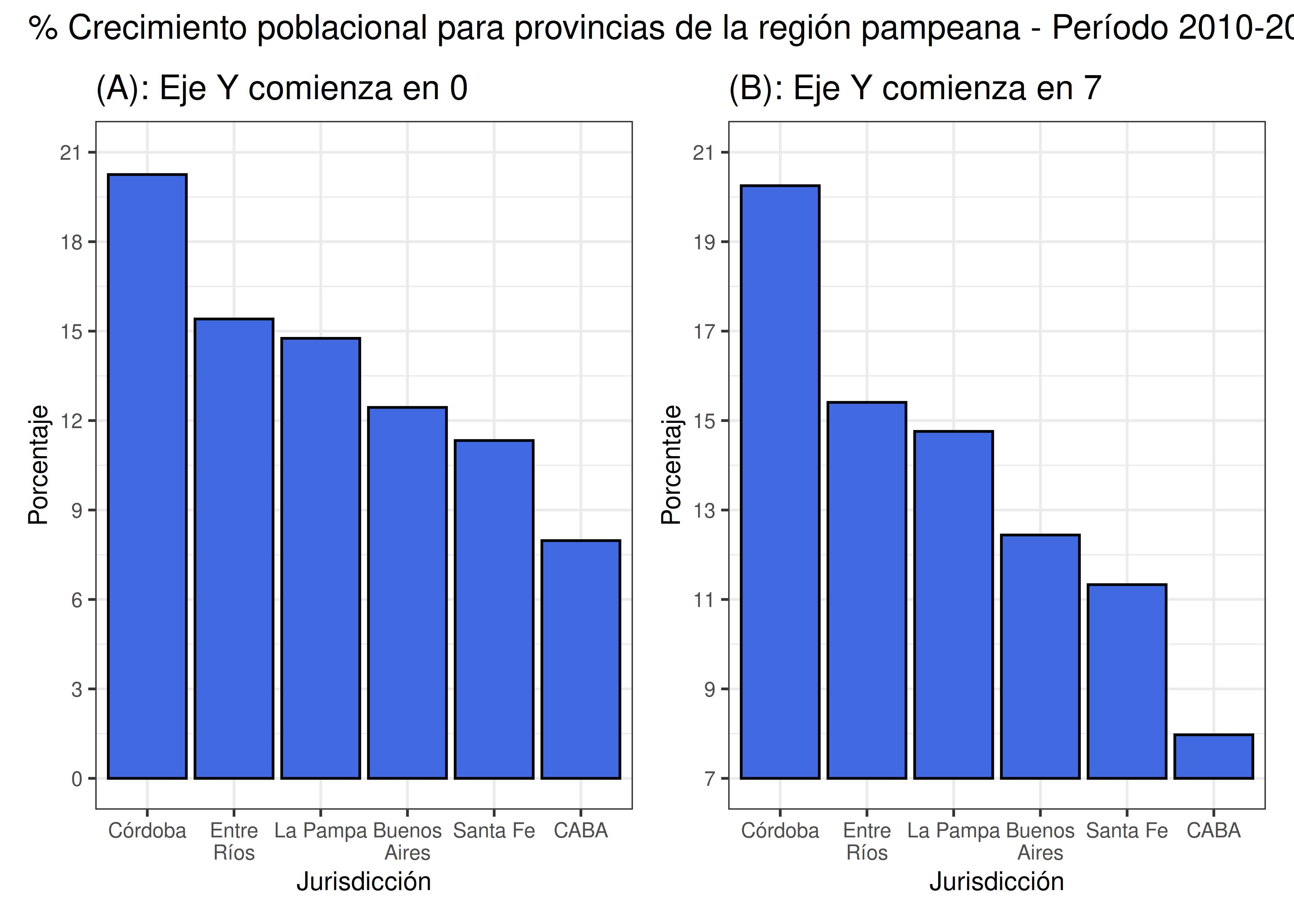
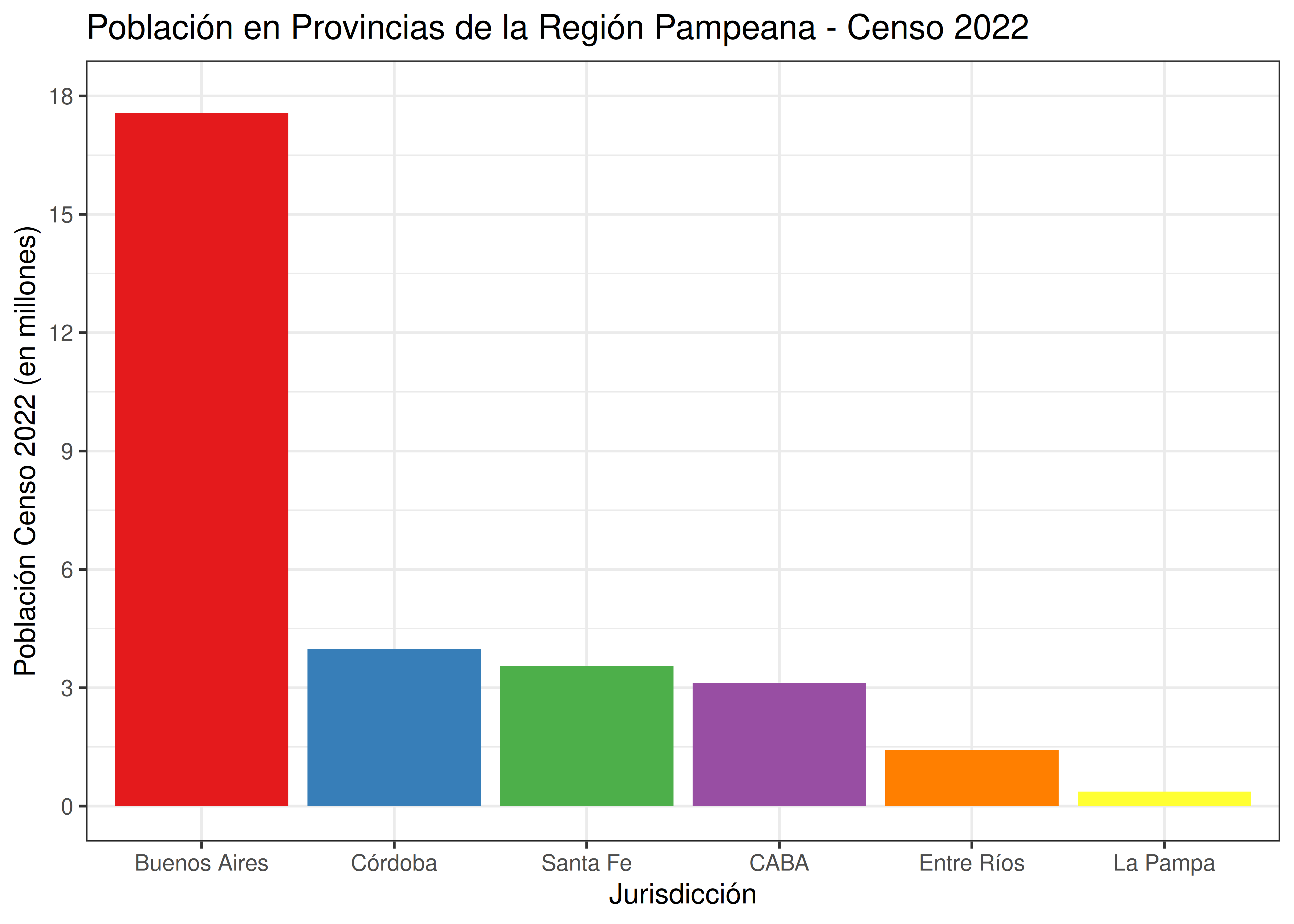
En el panel A del gráfico de arriba, vemos que la altura de la barra correspondiente a CABA (7.97%) es consistente con la altura de la barra correspondiente a Santa Fe (11.3%). La razón entre las alturas de ambas barras, \(7.97/11.3 = 0.7\), coincide con la razón entre los valores numéricos que representan.
Esto no ocurre con el gráfico del panel B. En este caso, la razón entre las alturas de las barras resulta (\(0.97/4.3 = 0.22\)), muy lejano del 70% correcto. Al modificar el punto inicial del eje, podemos hacer que la diferencia percibida entre individuos se exagere considerablemente.
En consecuencia, el gráfico del panel B no cumple con el principio de tinta proporcional. La moraleja de esta historia es que los gráficos de barra deben comenzar su escala en el valor 0.
Algo similar ocurre con los gráficos para series de tiempo, sobre todo si elegimos sombrear el área bajo la línea. Debajo vemos la evolución de la cantidad de nacimientos registrados en la Maternidad Martin de Rosario, entre enero de 2015 y diciembre de 2018 (datos descargados del Portal de Datos Abiertos de la Municipalidad de Rosario):
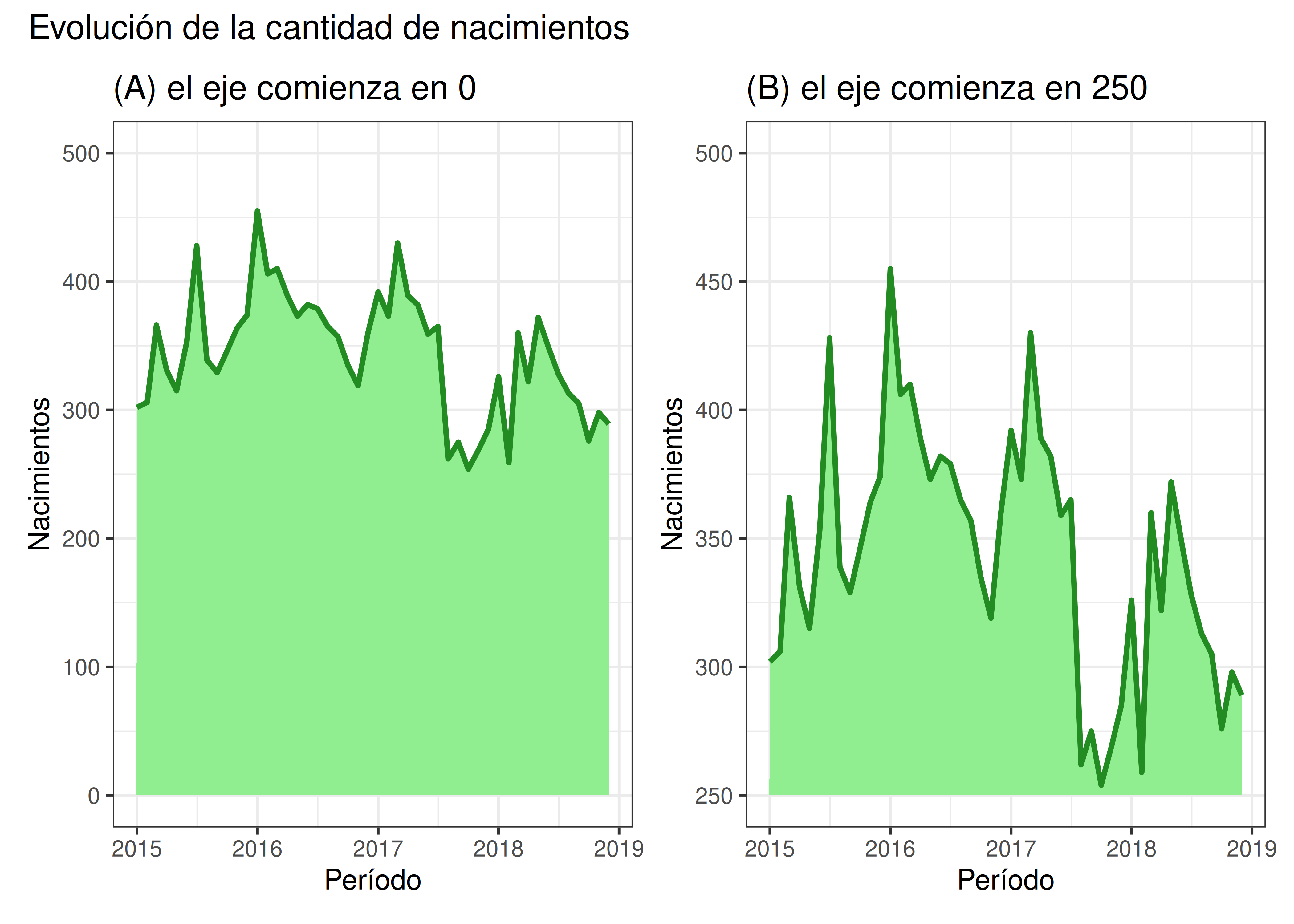
- Una vez más, vemos que los cambios entre períodos adyacentes se exageran cuando recortamos la escala del eje Y. Si bien hubo una baja pronunciada de nacimientos entre julio y agosto de 2017 (bajaron de 365 a 262, más del 28%), esta diferencia se percibe mucho mayor en el gráfico B que en el gráfico A.
2.1.1 Tinta proporcional usando áreas
En los ejemplos anteriores, vimos cómo respetar este principio mediante alturas de barras o líneas, es decir, cuando la dimensión a considerar es una sola.
Ahora veremos casos donde los valores representados comprenden 2 dimensiones. En particular, analizaremos 2 tipos de gráficos: el de sectores circulares (torta) y el de áreas rectangulares (treemap).
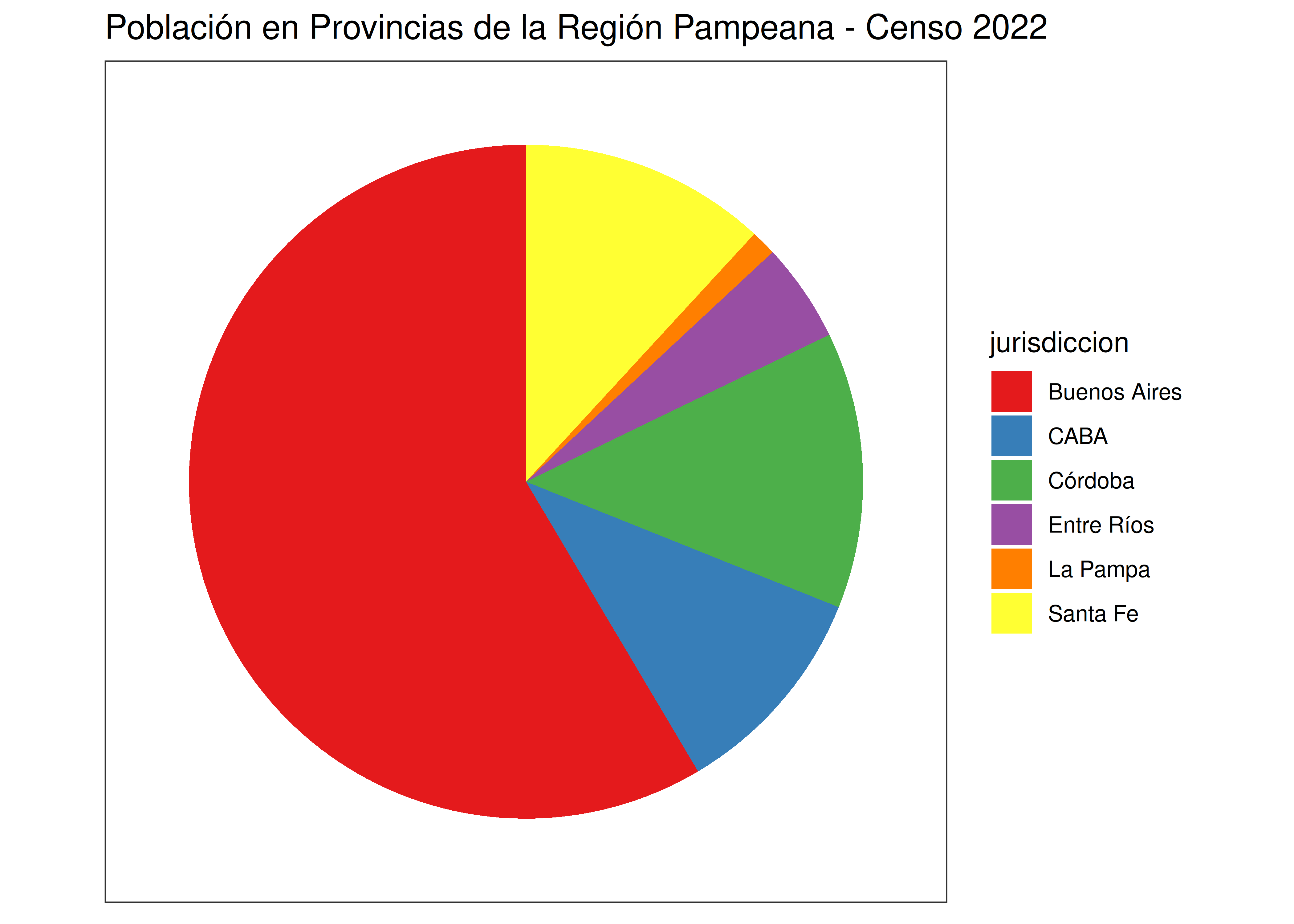
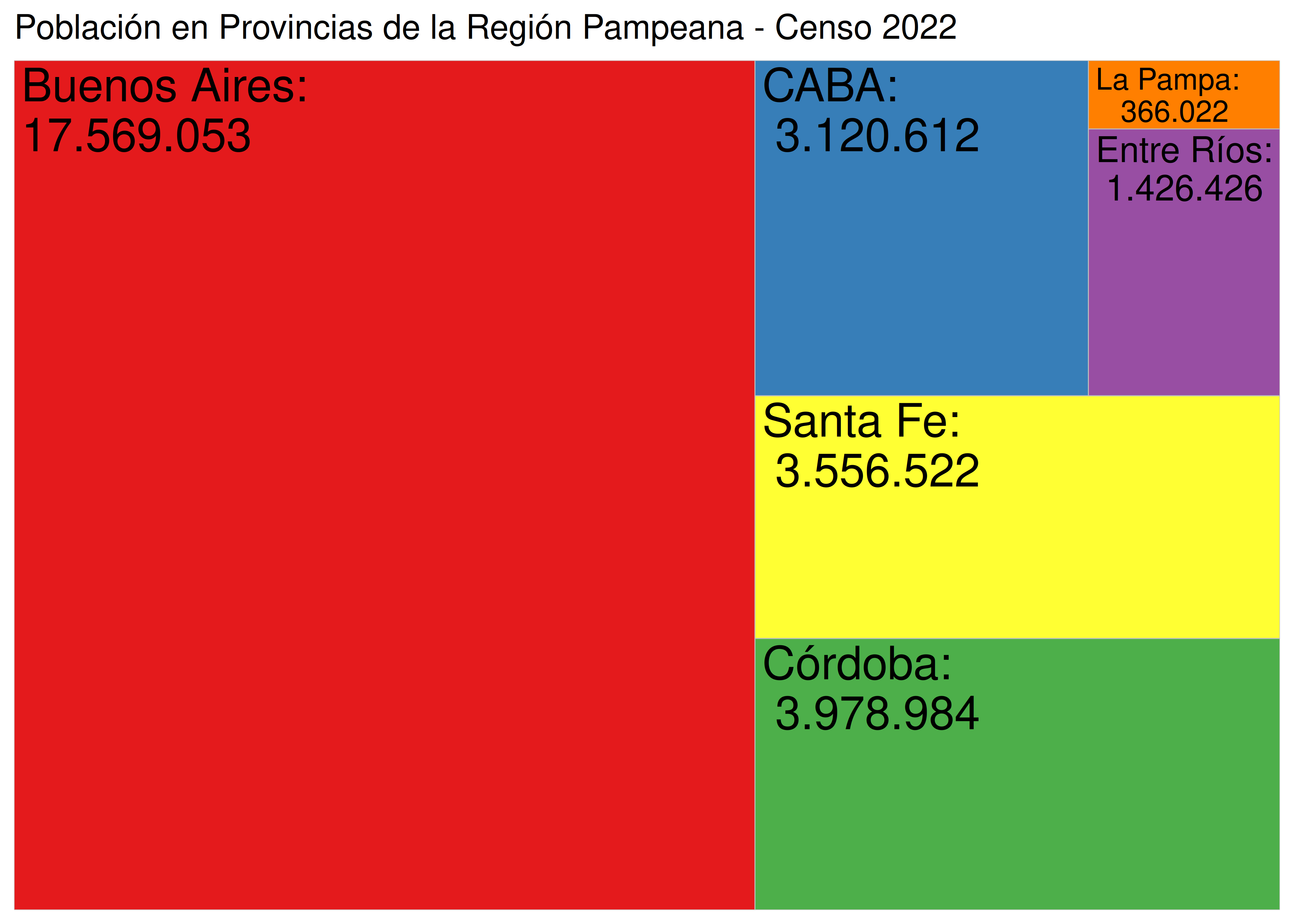
En estos dos ejemplos se verifica el principio de tinta proporcional: el área ocupada por cada región (ya sean porciones de círculo o rectángulos) con respecto al área total del gráfico, resulta proporcional a su valor correspondiente.
Por ejemplo, teniendo en cuenta que el 58% de la población que vive en la región pampeana lo hace en la provincia de Buenos Aires, sabemos que el 58% del área del círculo corresponde a Buenos Aires (ángulo de \(0.58\times360º = 211º\)) y también que el rectángulo rojo ocupa un 58% del área total del gráfico treemap.
En ambos casos, al no haber un origen de eje desde el cual comenzar a contar, el principio de tinta proporcional es “difícil” de incumplir.
Para concluir, mencionamos que los gráficos que utilizan el recurso del área para comparar magnitudes tienden a achicar visualmente las diferencias entre individuos, en comparación a lo que ocurre en un gráfico de barras, donde estas diferencias se magnifican.
Veamos una vez más los datos de población para provincias pampeanas, pero a través de un gráfico de barras verticales: la proporción correspondiente a Buenos Aires parece mucho mayor que el 58%:
2.2 Puntos superpuestos
Cuando queremos armar un diagrama de dispersión a partir de un conjunto de datos muy extenso, usualmente nos encontramos con el problema de la superposición de puntos: muchas observaciones con valores similares que se “pisan” unas a otras en el gráfico resultante, ocultando información valiosa.
Algo similar suele ocurrir si trabajamos con variables discretas, o cuyos valores hayan sido redondeados: en estos casos, aún con un conjunto de datos pequeño, es común encontrar perfiles idénticos de respuesta que se superponen en un diagrama de dispersión.
Ejemplo: partos en Rosario durante 2015/2018:
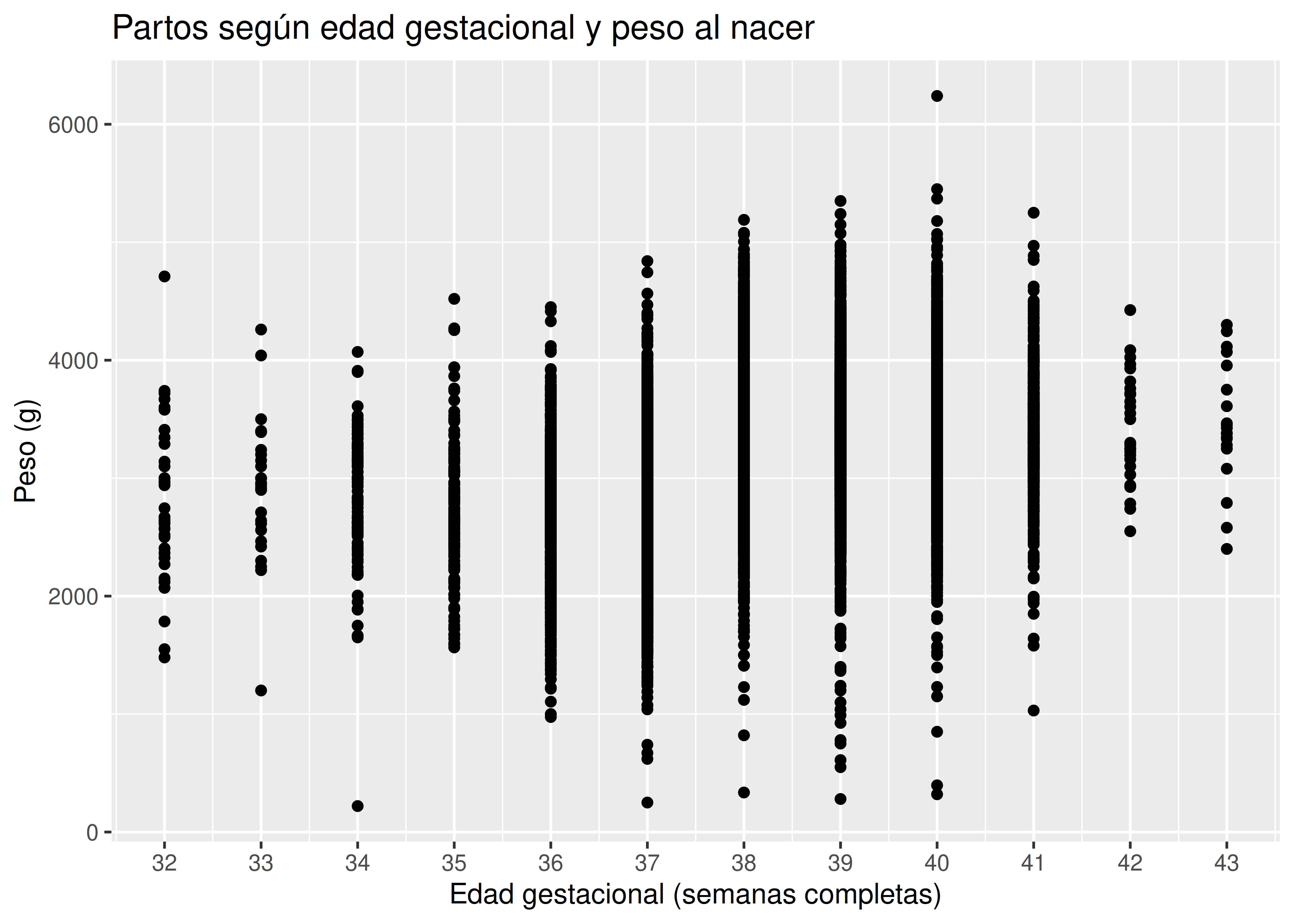
- A continuación veremos algunas maneras de remediar, al menos parcialmente, este problema.
2.2.1 Transparencia + Perturbación
La más común de las propuestas consiste en utilizar puntos con cierto nivel de transparencia para representar a cada observación. En el código de
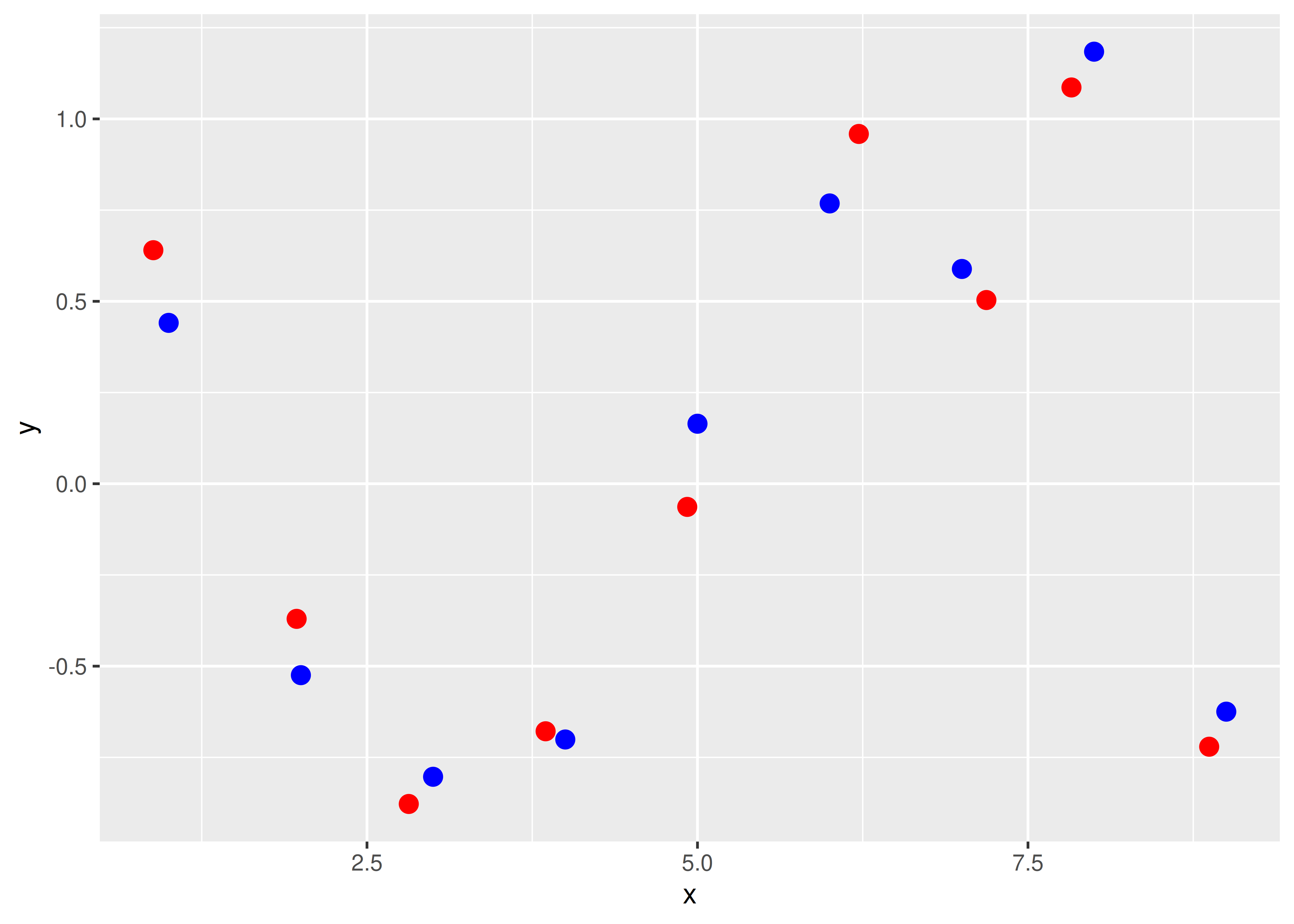
ggplot2se la define mediante el parámetroalpha, el cual puede tomar valores desde 0 (totalmente transparente, es decir, no se ve el punto) hasta 1 (color sólido, el valor por defecto).De todas maneras, graficar 10 puntos transparentes uno encima de otro no cambia nada: vamos a seguir perdiendo información a la hora de visualizar los datos. Por esto es que se agrega una perturbación aleatoria (jitter en inglés) que modifica levemente la posición original de cada punto.
Ejemplo: puntos originales (azul) y puntos nuevos (rojo) luego de aplicar una perturbación de a lo sumo 0.25 unidades en cualquier dirección (horizontal y/o vertical).
- Retomando el ejemplo de los partos, aplicamos una transparencia de 0.25 y un nivel de perturbación de 1 unidad en el sentido del eje X (es decir, sumamos o restamos 1 semana de gestación al valor real):
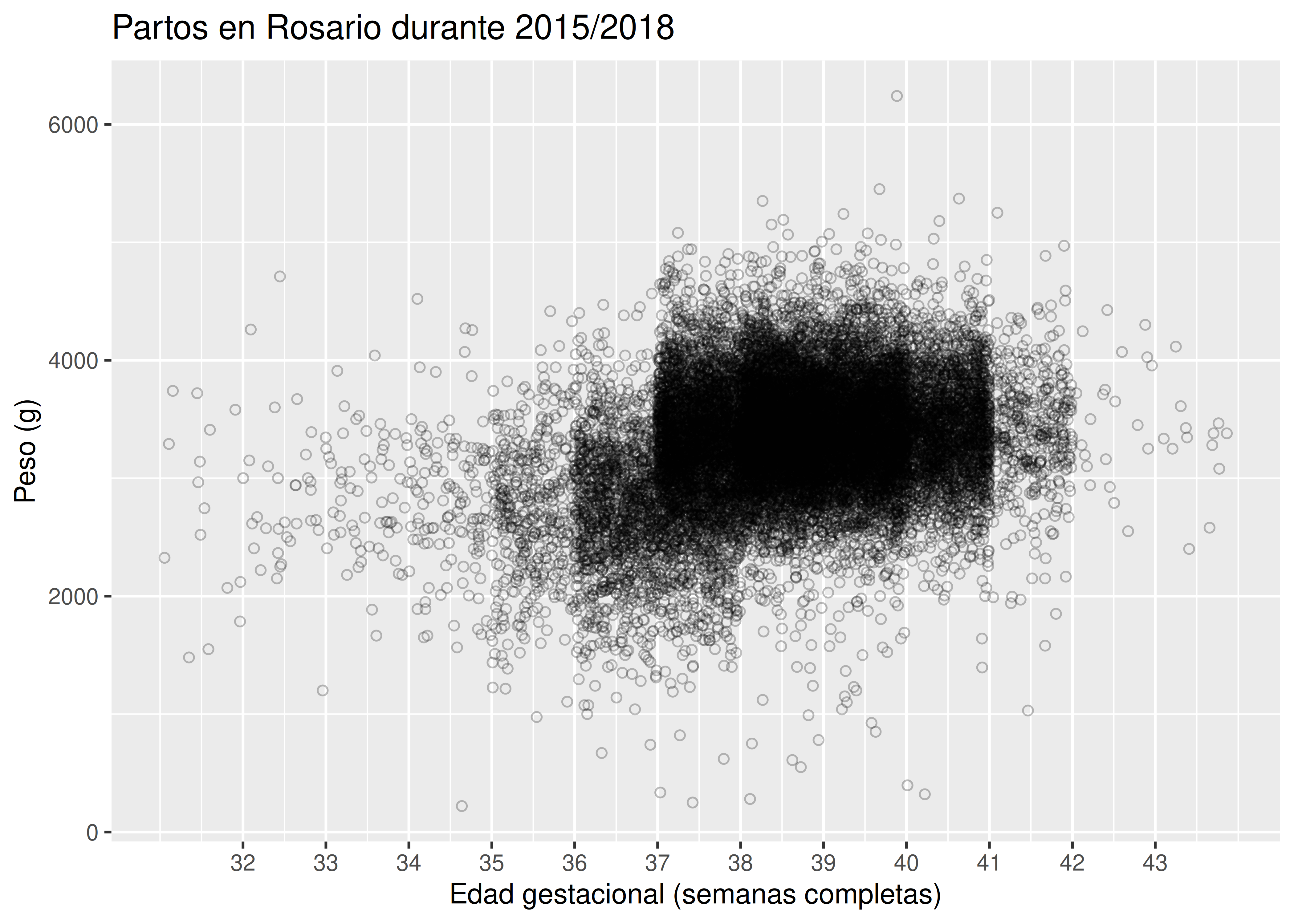
La apariencia de este gráfico de dispersión es muy diferente en comparación al que obtuvimos originalmente. Si bien el patrón general se mantiene, ahora se aprecia un volumen mucho mayor de datos en la sección central del gráfico (recordemos que estamos analizando más de 20.000 partos; en el gráfico original, se pueden apreciar a simple vista aproximadamente entre 350 y 600 puntos diferentes, dependiendo de la agudeza visual para distinguir diferencias en el sentido vertical).
El nivel de perturbación aleatoria que se aplica debe ser lo suficientemente alto como para permitir la separación de puntos, pero al mismo tiempo no ser tan elevado como para “desacomodar” la verdadera relación entre variables.
Aclaración: al ser aleatoria, la perturbación aplicada genera diferentes versiones del mismo gráfico cada vez que se la vuelve a utilizar. Para replicar los resultados, debemos usar una semilla aleatoria específica mediante
set.seed().
2.2.2 Hexágonos
Estos gráficos, también conocidos como “histogramas 2D”, tratan de solucionar el problema de la superposición agrupando observaciones con valores similares en ambas dimensiones.
Se divide al plano en múltiples hexágonos regulares de 6 lados, y luego se cuenta la cantidad de observaciones que existen dentro de cada hexágono. A cada uno se le asigna un color de acuerdo al volumen de datos que encierra:
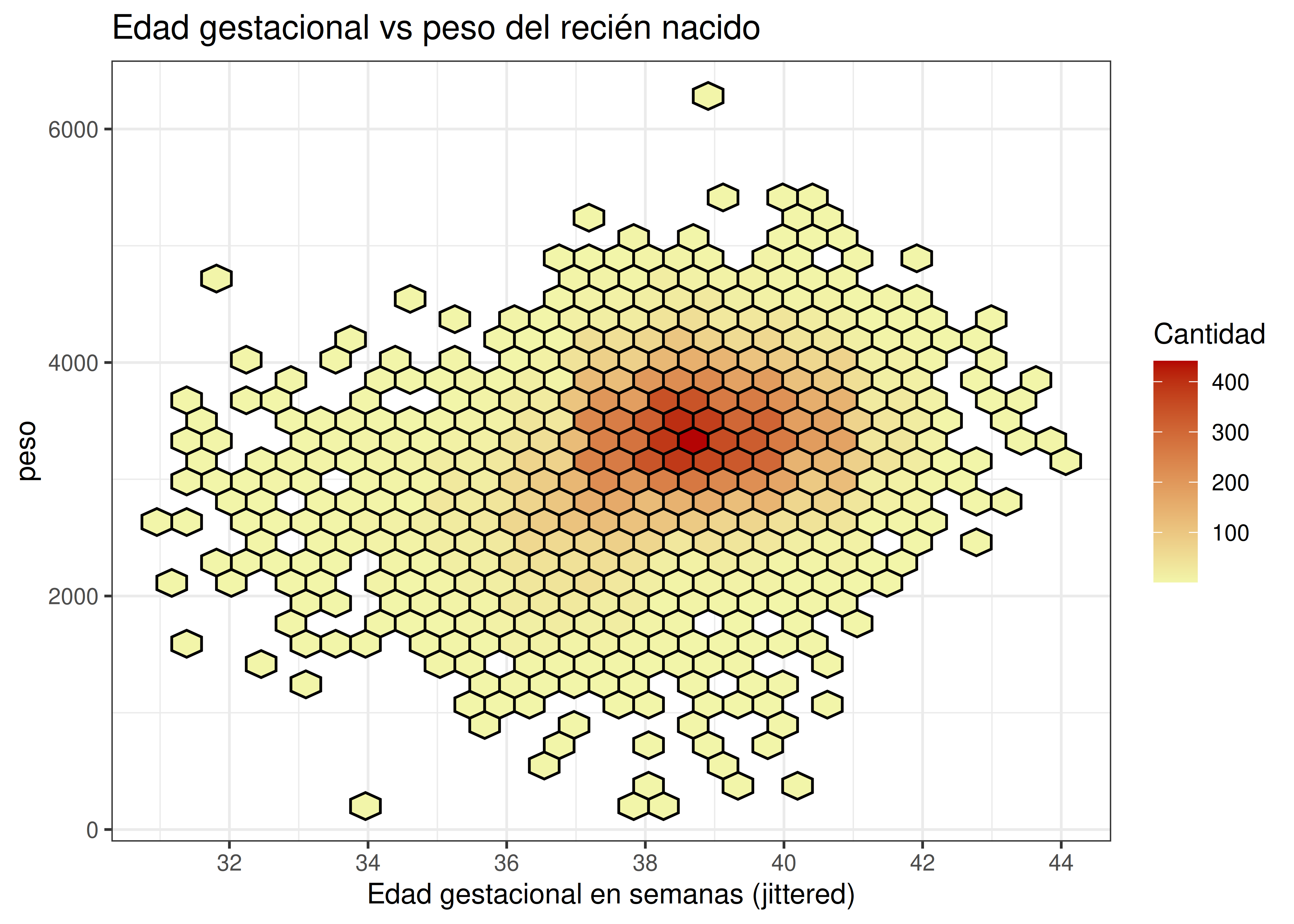
La ventaja de este método es que no necesitamos modificar aleatoriamente los datos originales, como ocurre con el caso del jittering; de todas maneras, al agrupar (categorizar) observaciones continuas estamos perdiendo información.
En general se lo aplica cuando la solución del jittering no es suficiente, es decir, cuando seguimos viendo “manchas” de puntos que no se distinguen unos de otros. En estos gráficos no existe superposición, ya que cada hexágono posee su lugar correspondiente.
2.2.3 Gráficos de contorno
Una última alternativa consiste en crear gráficos de contornos, en los cuales se realiza una estimación de la función de densidad bivariada definida por las variables X e Y. Áreas del plano con igual nivel de densidad estimada se diferencian mediante líneas de contorno, las cuales pueden estar coloreadas usando una paleta secuencial.
No todos los conjuntos de datos son adecuados para este tipo de gráficos: para poder apreciarlos mejor, la densidad estimada debe crecer o decrecer lentamente en ambas direcciones.
Veamos cómo resulta el gráfico de contornos para el ejemplo de semanas de gestación vs peso del bebé:
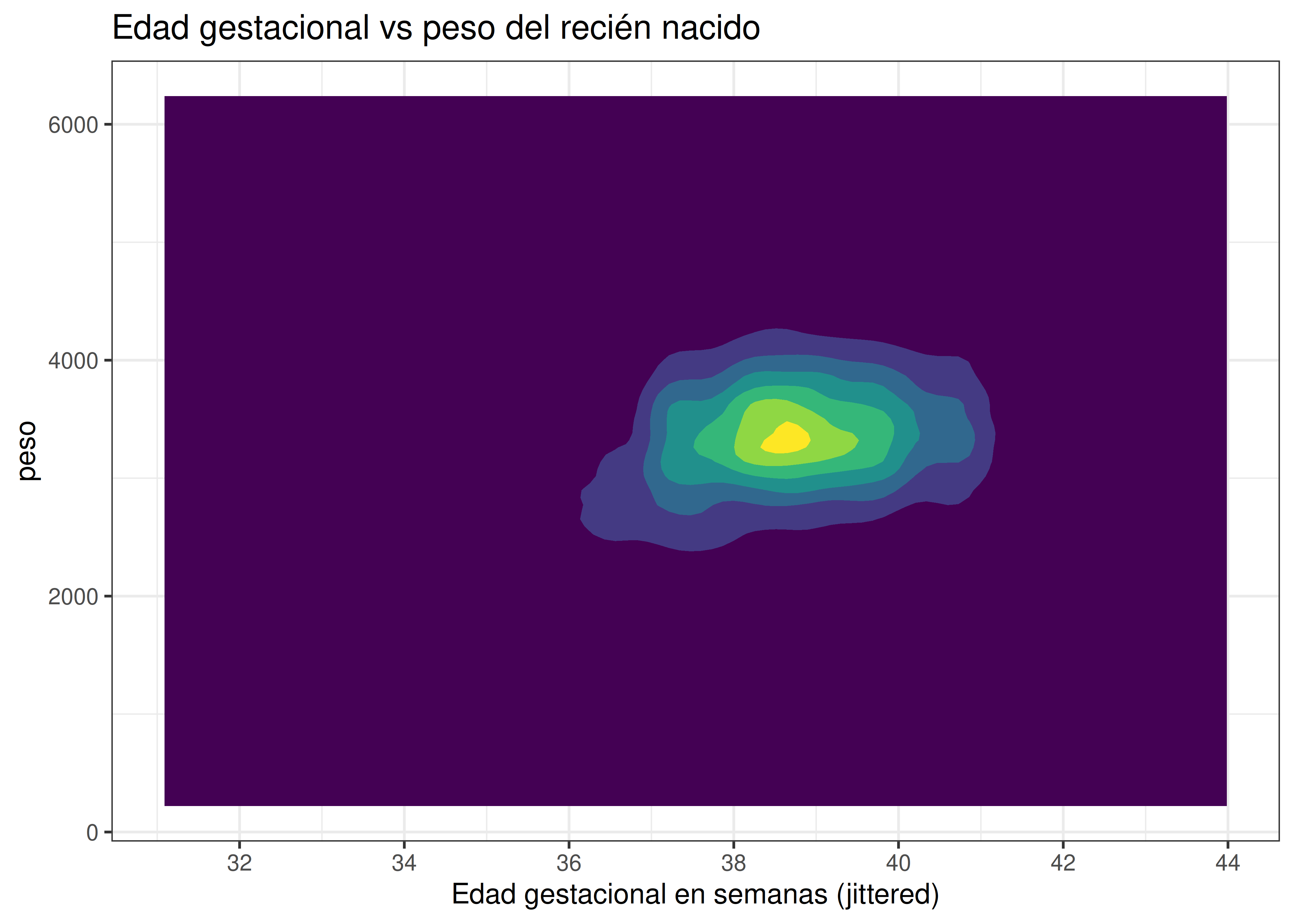
Con la escala utilizada, áreas de colores “fuertes” (amarillo, verde) se asocian a densidades más elevadas, mientras que las tonalidades azules y violeta corresponden a sectores del plano con menor densidad de puntos.
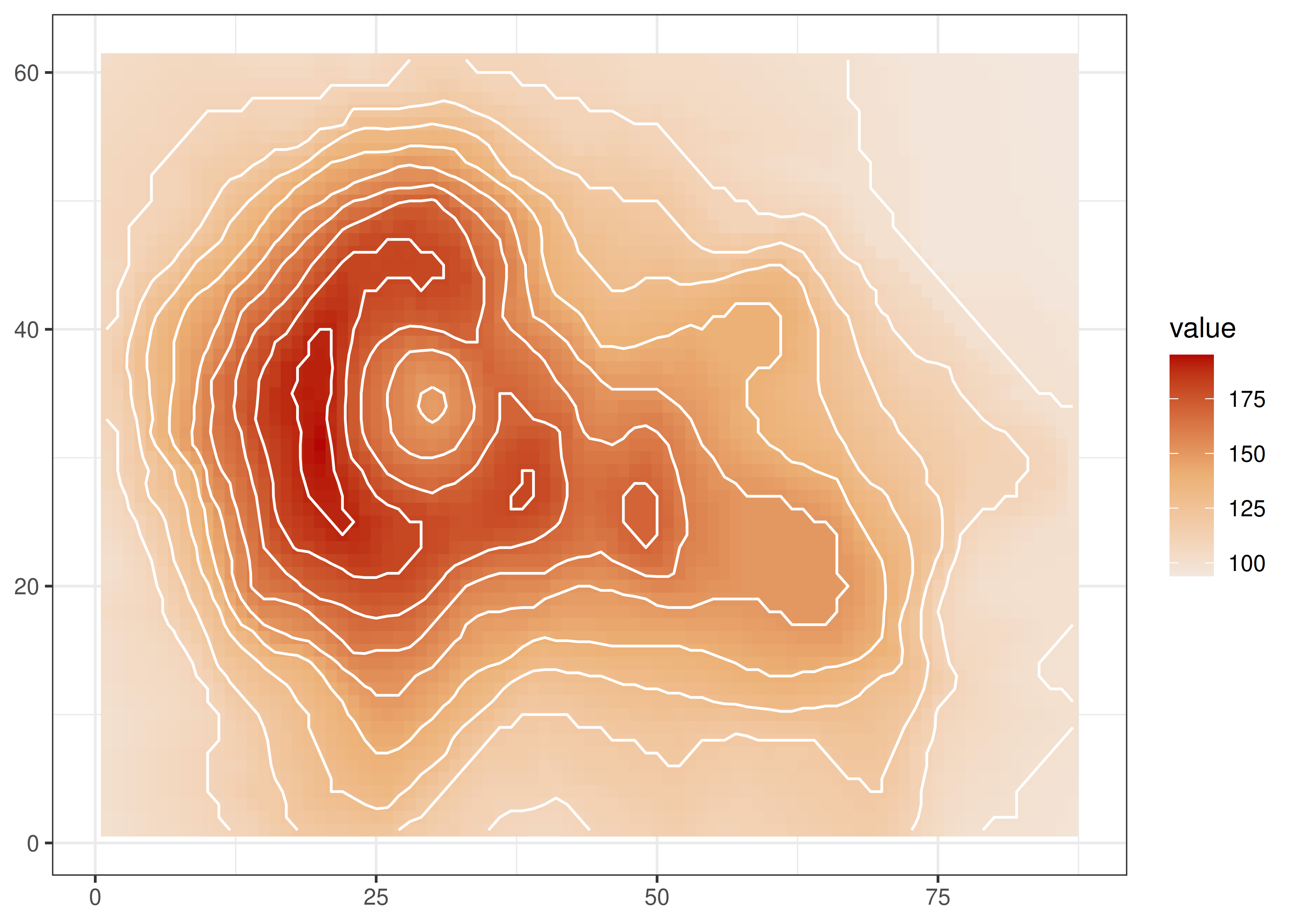
Un conjunto de datos con características que se aprovechan bien para un gráfico de contornos es
volcanode R Base. Este dataset posee información topográfica sobre el volcán Maungawhau ubicado en Nueva Zelanda.Las líneas de contorno dan una idea del relieve del volcán; en vez de marcar densidad, ahora utilizamos esta herramienta para delimitar zonas con diferentes alturas sobre el nivel del mar:
2.3 Colores
Si están bien utilizados, los colores pueden ser herramientas muy efectivas a la hora de mejorar visualizaciones de datos. Al mismo tiempo, una mala elección de colores puede arruinar completamente un gráfico.
Sea cual sea la paleta de colores que se use, el esquema elegido debe transmitir un mensaje claro, poseer un objetivo específico y no distraer.
A continuación vamos a ver algunos casos de gráficos donde el color está mal empleado.
2.3.1 Muchos colores
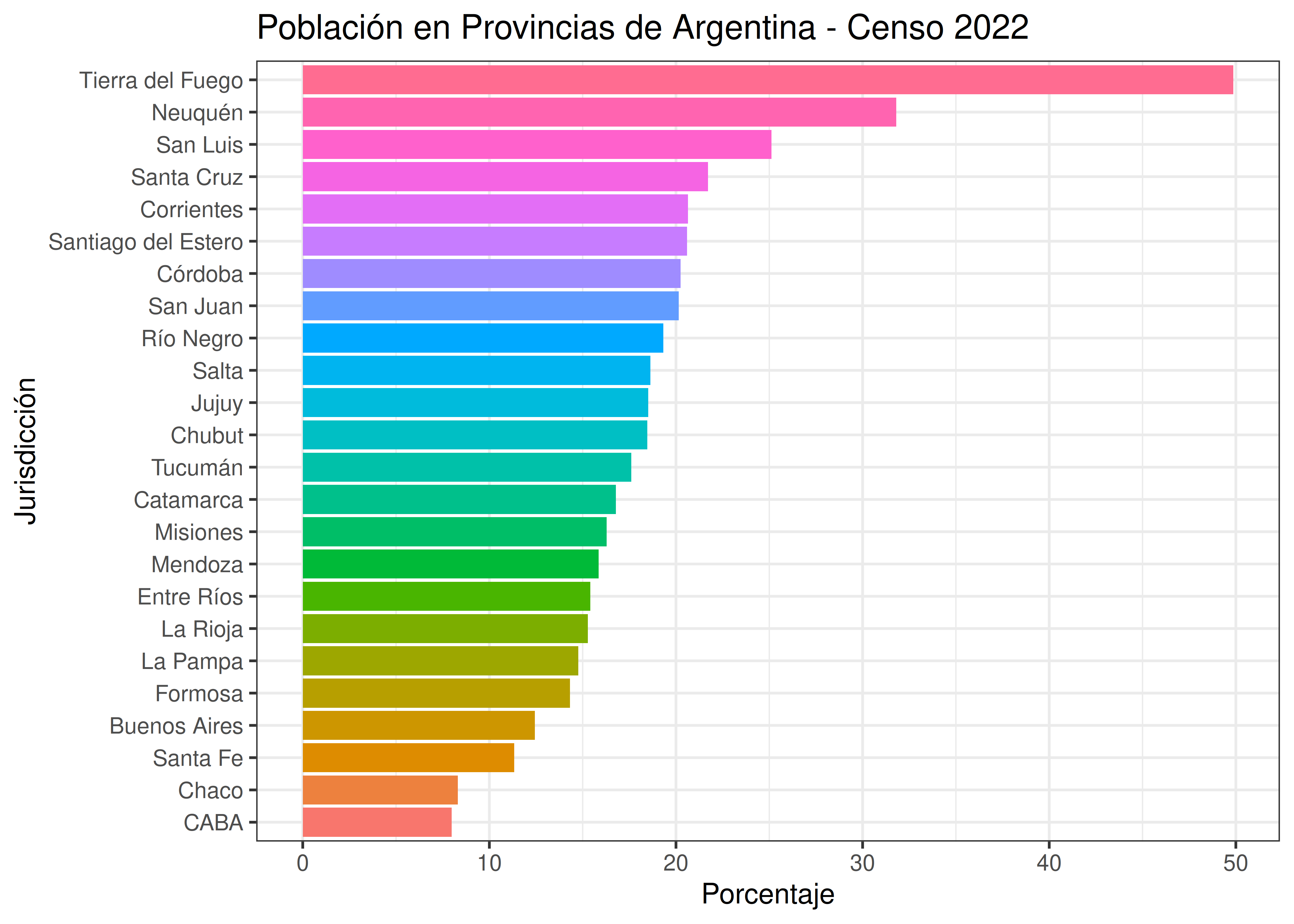
Un error común consiste en usar demasiados colores, como en el gráfico que se muestra a continuación. Dado que cada observación (en este caso, provincias argentinas) posee su propia tonalidad, la cantidad total de colores es muy elevada.
El trabajo de asociar a cada color con su respectiva provincia es un proceso que requiere de mucha atención, lleva tiempo y es fácil caer en equivocaciones (provincias con colores similares son prácticamente indistinguibles).
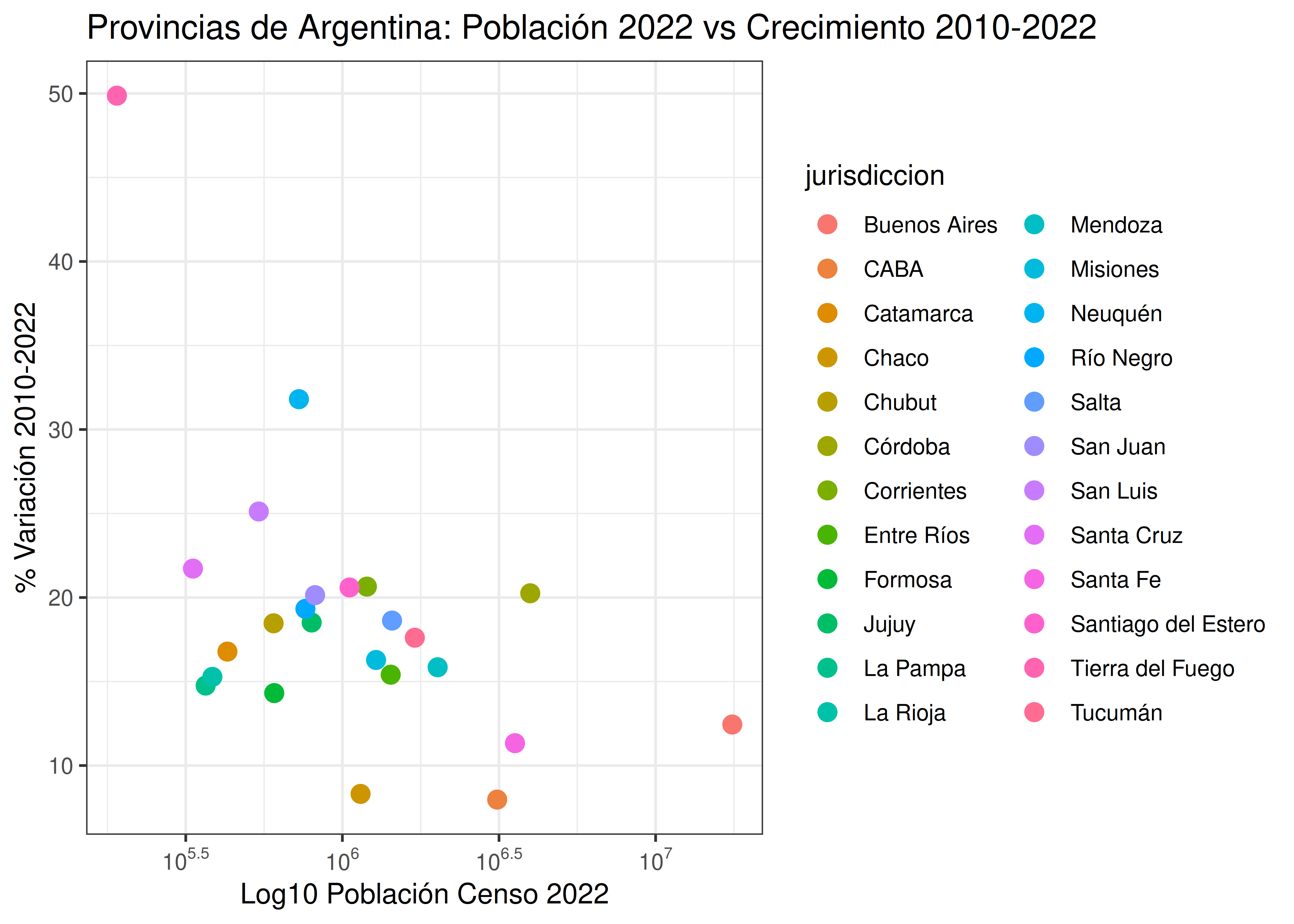
Los colores deben ser usados para mejorar gráficos y hacerlos de lectura más fácil, no para crear “acertijos visuales” donde el mensaje que se transmite termina siendo confuso.
Como alternativas al gráfico anterior, mostramos dos posibilidades: una donde el color se asocia a otra variable cualitativa, y uno donde se reemplaza el color por etiquetas que brindan la información deseada:
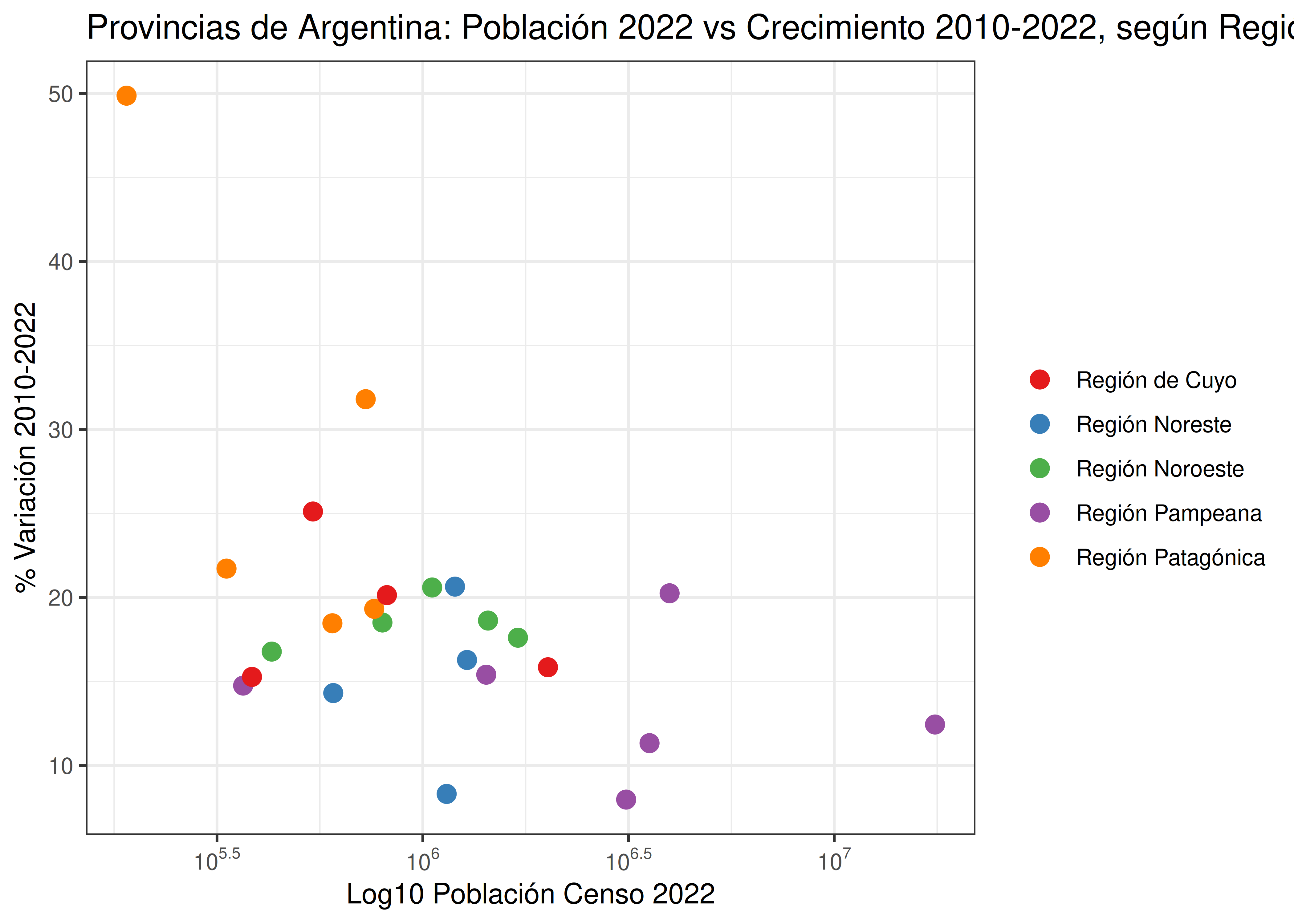
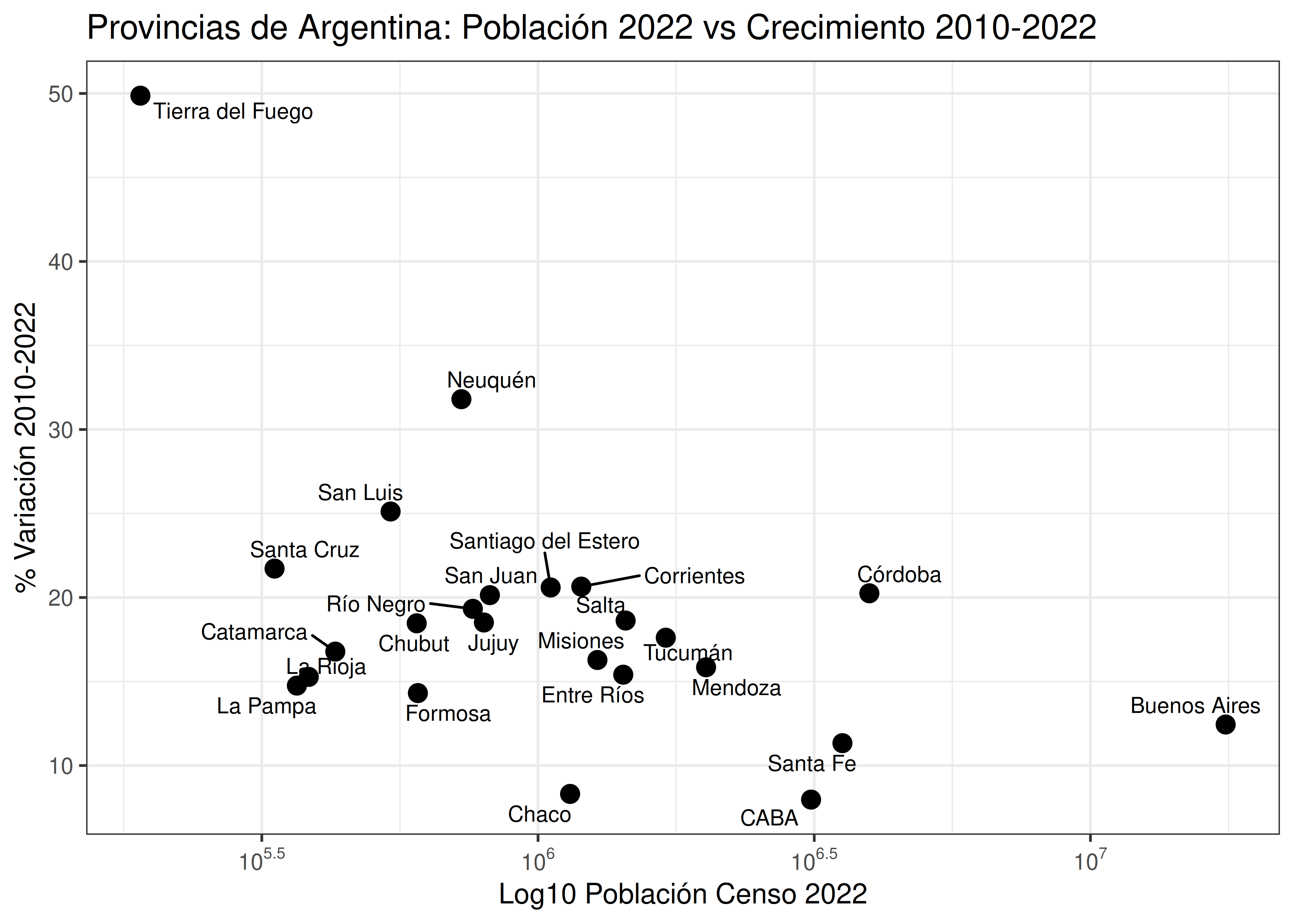
- En general, el uso de colores para distinguir entre categorías se recomienda cuando existen pocos grupos a graficar. Por ejemplo, las funciones de R que implementan las paletas creadas por Cynthia Brewer (paquete
RColorBrewer) devuelven un mensaje de advertencia si usamos más de 9 colores.
2.3.2 Colores innecesarios
- A veces, quienes generan gráficos sufren del síndrome de “Art Attack” y agregan detalles y colores que no suman al mensaje, sino más bien que distraen. El gráfico de abajo es un claro ejemplo de ello:
- En esta visualización, la paleta de colores no aporta información ni ayuda a entender mejor el mensaje transmitido; sólo se usa para darle un toque colorido al gráfico. Si bien esto no es un problema grave en sí mismo, podemos aprovechar el color de maneras más eficientes, por ejemplo para distinguir entre regiones geográficas (como vimos anteriormente) o bien usando una escala secuencial que refuerce la idea de diferencias numéricas entre provincias.
2.3.3 Escalas confusas
Cuando queremos emplear una gama de colores para recrear valores numéricos, es necesario definir paletas que tengan incrementos monótonos entre tonalidades. En general se eligen paletas de un solo color (por ej. verde claro a verde oscuro) o bien grupos de colores de una familia cercana (amarillos, naranjas, rojos).
Cuando esto no se cumple, las visualizaciones resultantes son confusas. Veamos un ejemplo usando la paleta arcoíris (rainbow), muy popular en R, pero poco útil en la práctica:
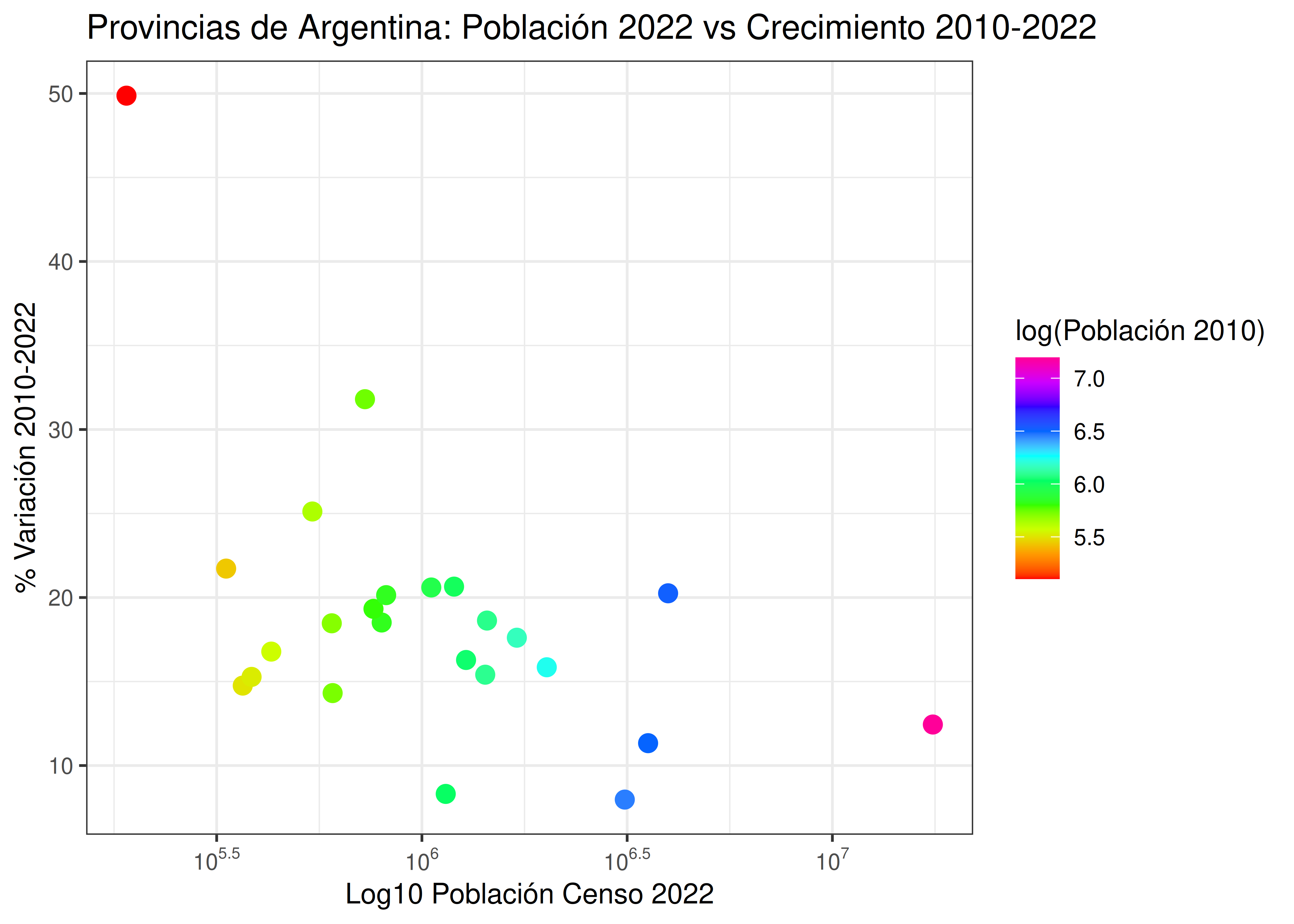
Esta escala es circular: los colores ubicados en los extremos (rojo y rosa fuerte) son similares, lo cual resulta confuso ya que están asociados a valores numéricos muy diferentes entre sí. Además, hay regiones de cambios rápidos (ej.: de amarillo a verde) y otras de cambios lentos (ej.: azules), lo cual hace que cantidades equidistantes entre sí pueden estar representadas por colores muy parecidos o muy distintos, dependiendo de la zona del eje en que se ubiquen.
Por todos estos motivos, las escalas de colores empleadas para representar valores numéricos deben ser monótonas y secuenciales. Por ejemplo:
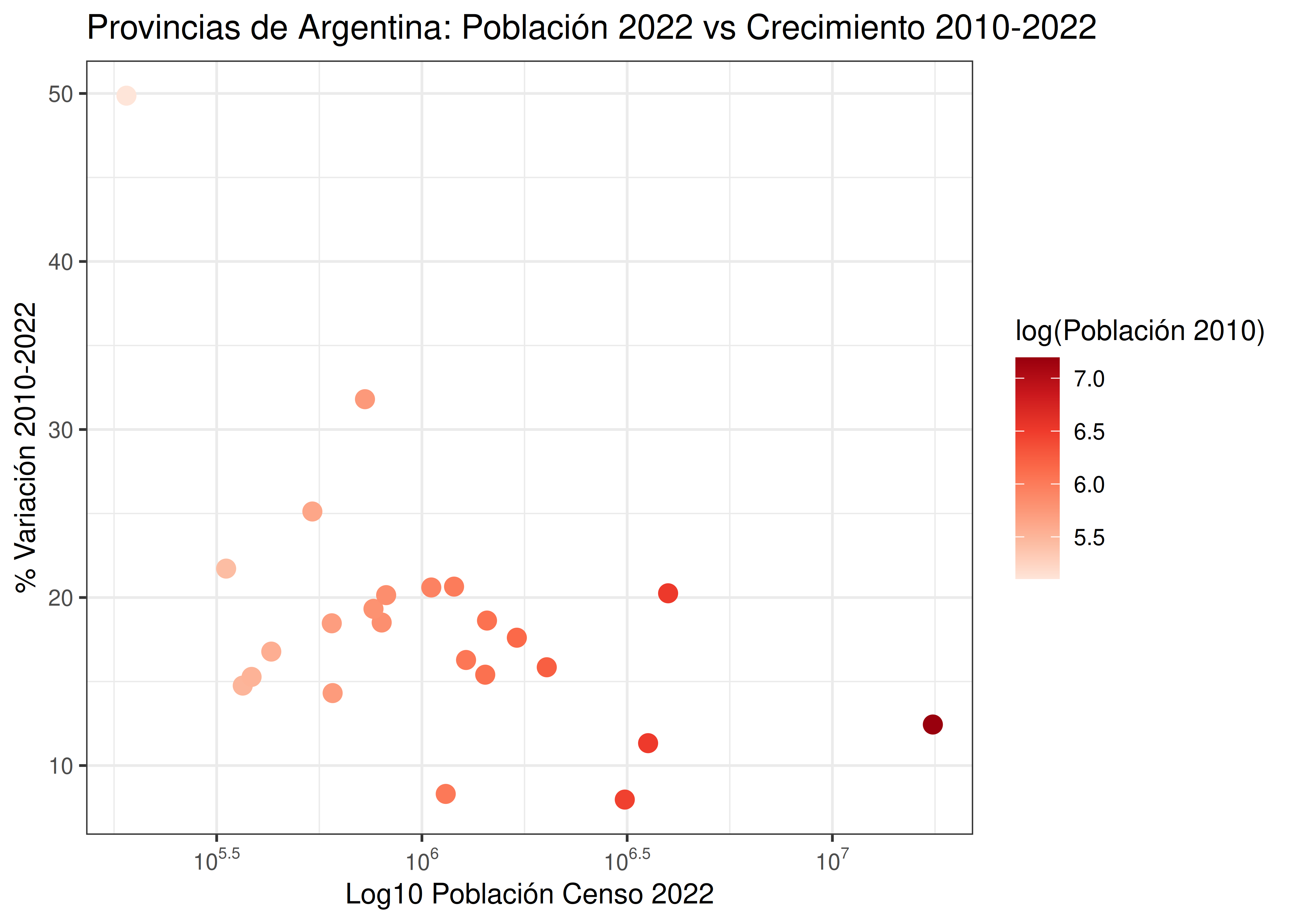
- Un problema similar al anterior ocurre si usamos colores muy parecidos para representar categorías:
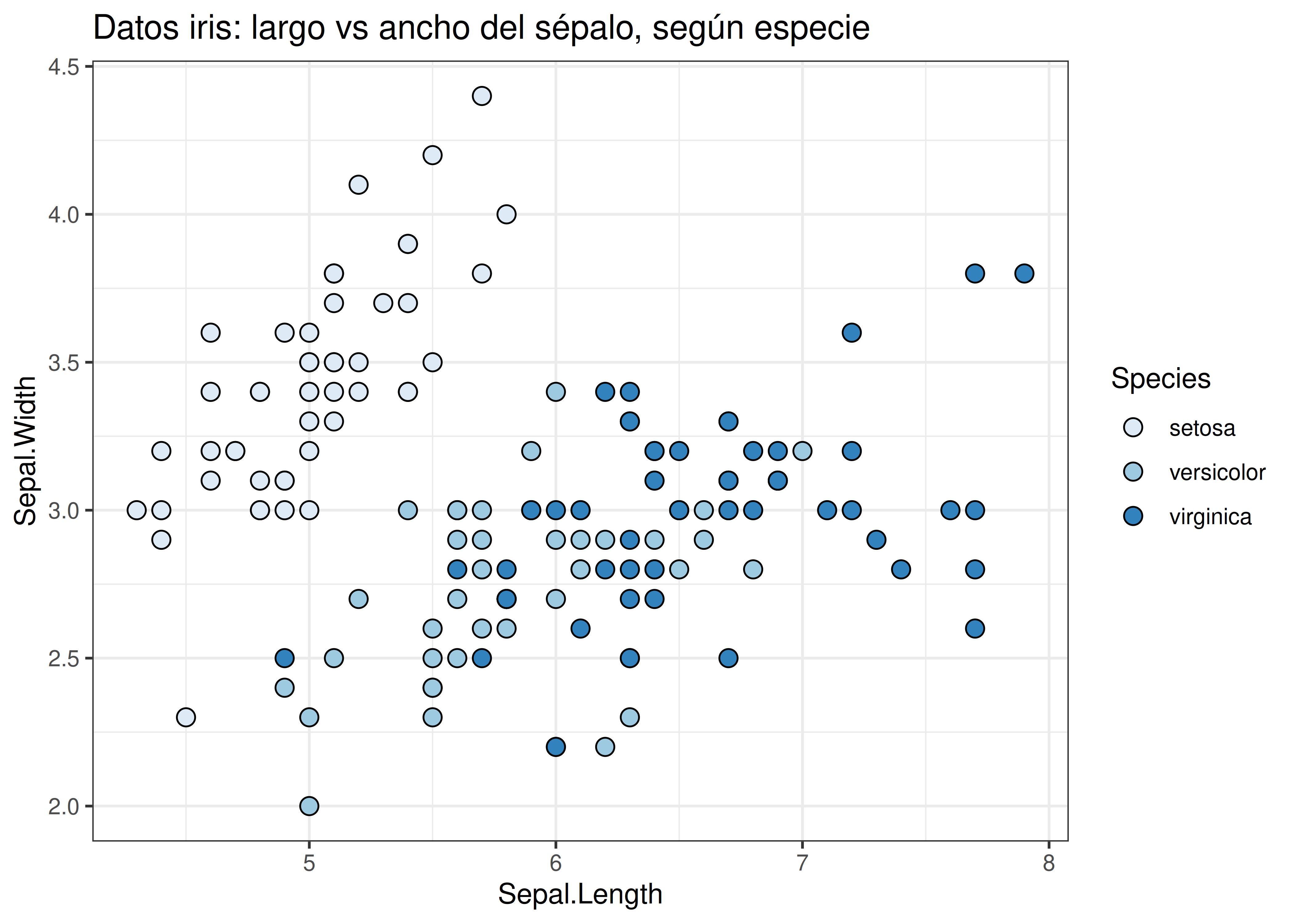
- En este caso, no sólo hay dificultades porque las tonalidades son similares entre sí, sino que también tenemos una superposición de puntos entre las especies versicolor y virginica. Asignar tonalidades que se distingan unas de otras ayuda a separar visualmente ambas categorías:
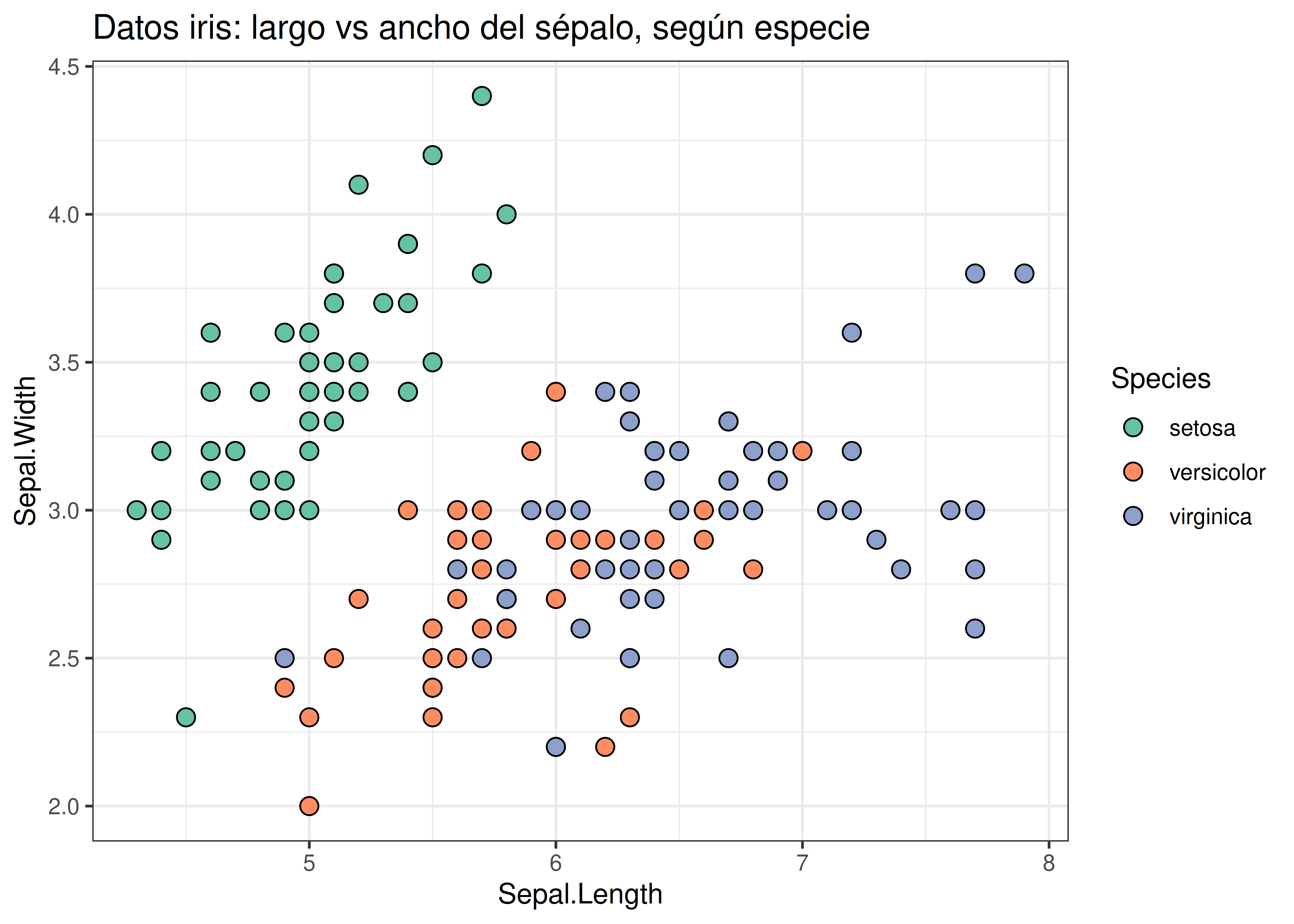
2.3.4 Paletas para personas daltónicas
Si bien no existen estudios concluyentes al respecto, se estima que a nivel mundial, aproximadamente entre un 5% y 10% de los varones poseen algún grado de daltonismo, mientras que entre las mujeres la prevalencia se reduce a menos del 1%. El tipo de daltonismo más común consiste en la incapacidad de distinguir correctamente las tonalidades rojas de las verdes, aunque hay personas con daltonismo asociado a otros colores (azul y verde, etc.).
Teniendo en cuenta esto, hay paletas creadas específicamente para que personas con daltonismo puedan distinguir fácilmente los colores empleados. Un ejemplo es la paleta de Okabe-Ito:
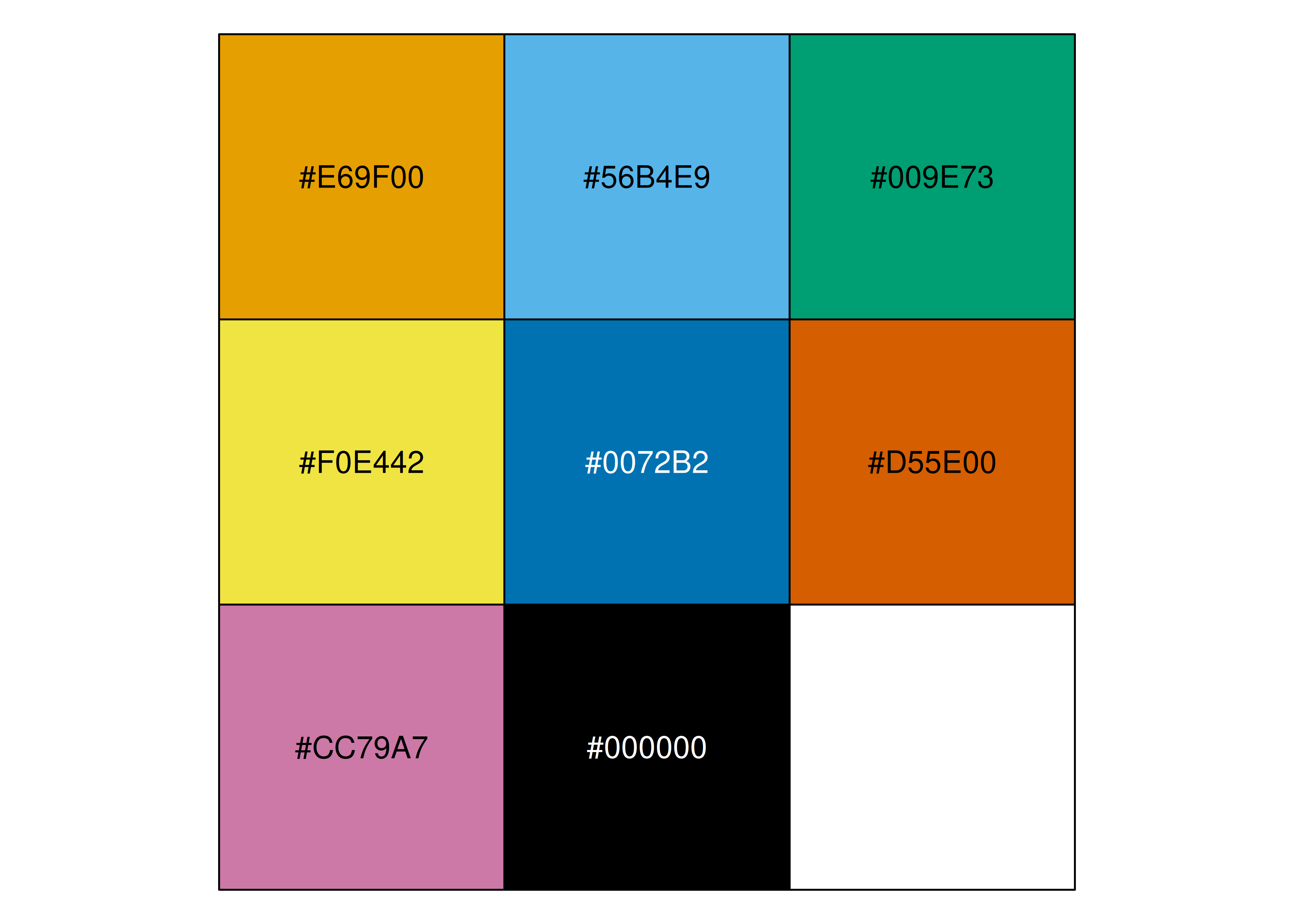
- Como alternativa, tenemos la paleta PiYG de Brewer (llamada original abajo). A su lado vemos cómo la visualizarían personas con diferentes tipos de daltonismo; todas las versiones siguen siendo fácilmente distinguibles:

- Si usamos otras paletas, lo anterior puede no ocurrir y la diferencia entre cada grupo queda oculta para la persona con daltonismo:

- Por lo tanto, si nuestros gráficos van a ser consumidos por un público extenso, es buena idea emplear paletas que tengan en cuenta estos detalles.
2.3.5 Blanco y negro
Siempre que el contexto lo permita, debemos tratar de evitar crear gráficos en blanco y negro. Rellenar figuras (boxplots, barras, etc.) con algún color sólido hace que estas se destaquen mejor contra el fondo del gráfico, permitiendo una interpretación más inmediata de las cantidades representadas y, de paso, convirtiendo la visualización en un objeto visualmente más agradable.
Claus Wilke argumenta que la costumbre de no usar colores proviene de los primeros software de visualización de datos, los cuales intentaban emular de manera precisa el aspecto de los gráficos hechos a mano por los científicos. En estos gráficos los colores muchas veces brillaban por su ausencia, o bien eran usados para crear un patrón de relleno no sólido (a rayas, con puntos, etc.).
Por otro lado, debemos tener en cuenta que durante mucho tiempo la comunicación de la ciencia se hizo casi exclusivamente en formato papel, y todos sabemos que imprimir a color es siempre más costoso que hacerlo en blanco y negro. Hoy en día, donde la gran mayoría de los gráficos existen de manera digital, no hay justificación para evitar el uso de colores, más allá de un criterio minimalista que puede ser empleado por razones puramente estéticas.
A continuación vamos a ver algunos ejemplos de gráficos sin color y sus potenciales problemas.
Gráfico de barras: las barras blancas sobre fondo blanco pueden llegar a crear una ilusión óptica que perjudica la cómoda visualización del gráfico:
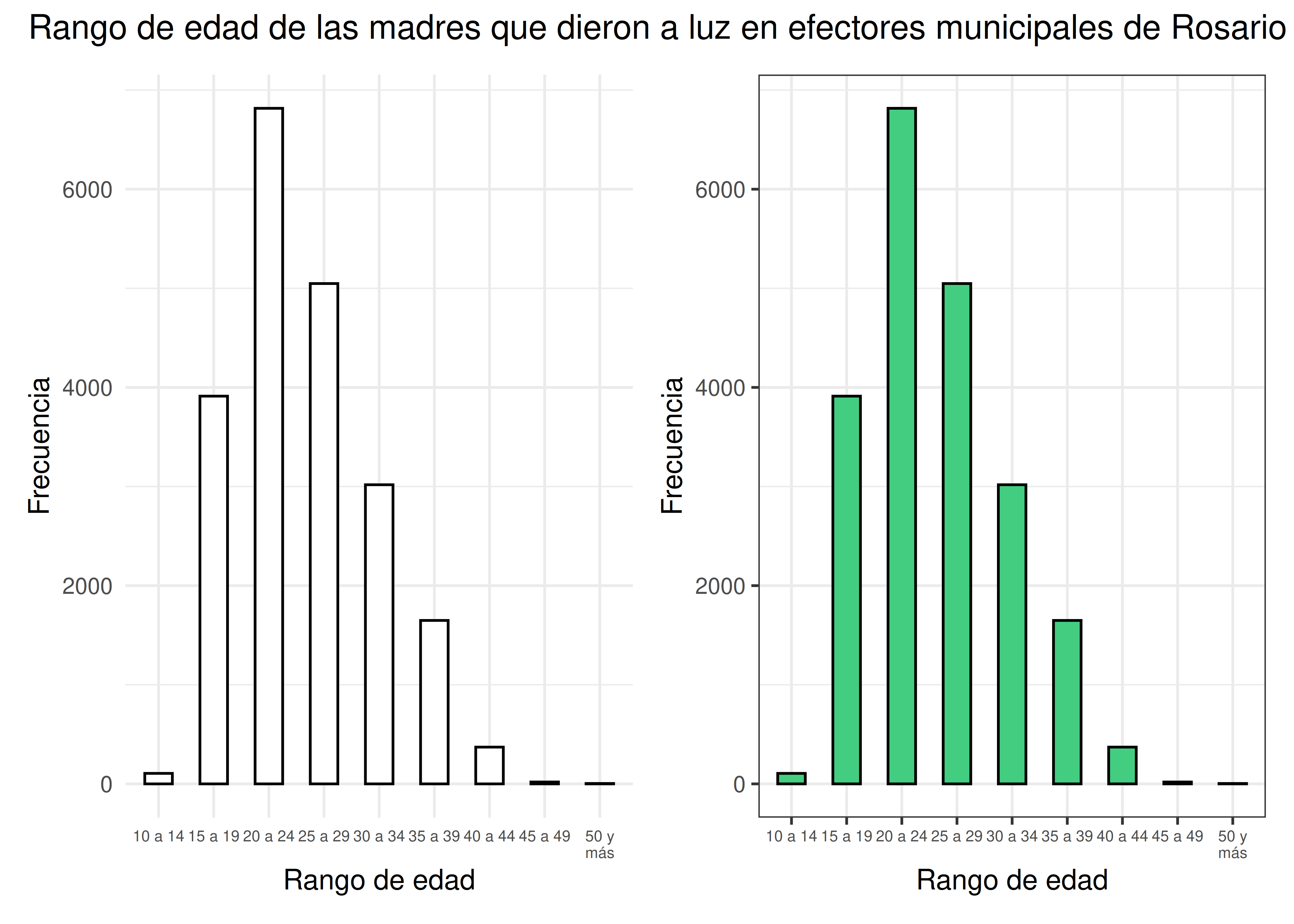
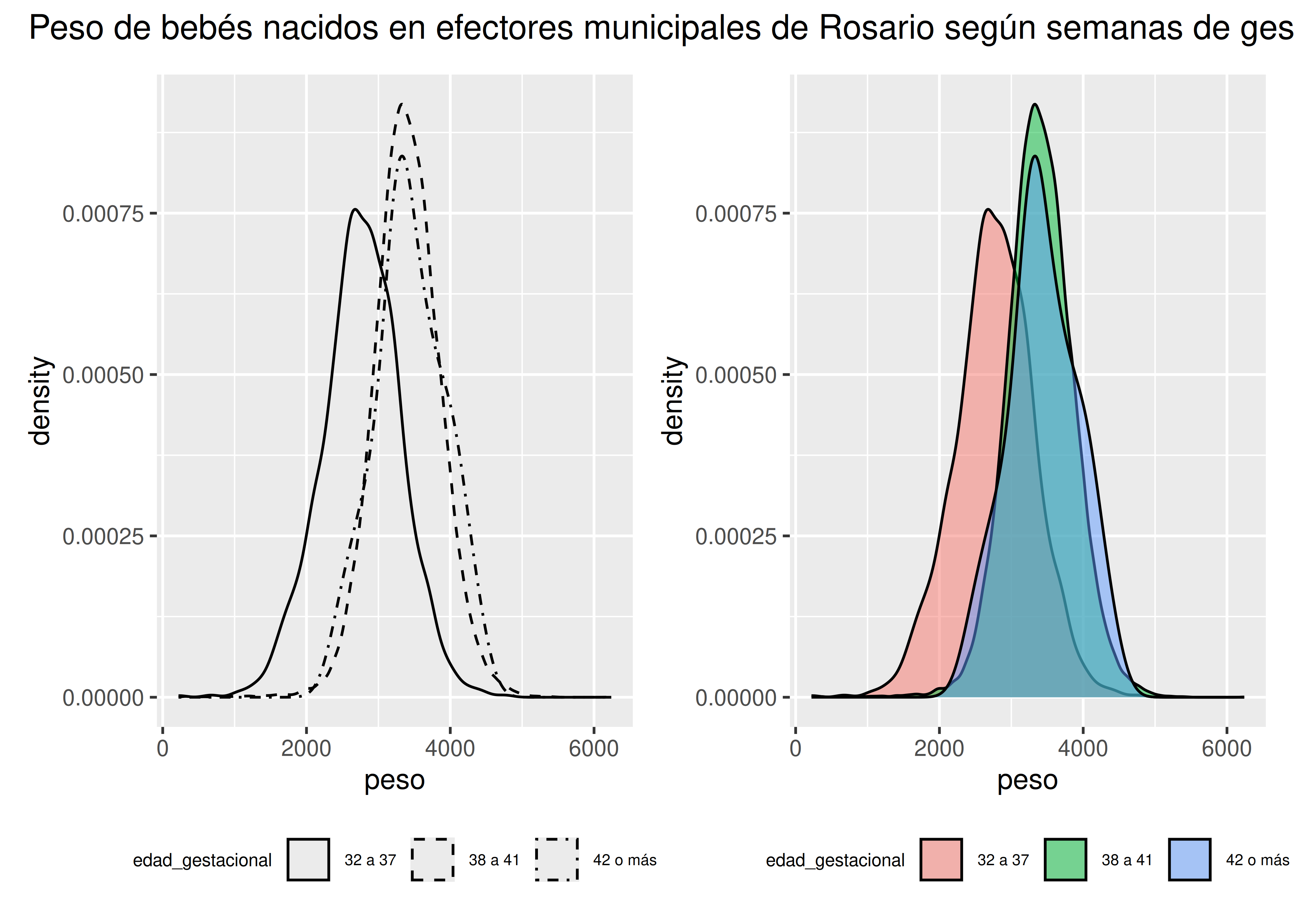
- Densidades: la superposición de las curvas y la necesidad de diferenciar grupos hacen necesaria la presencia de colores. Si tenemos que limitarnos al blanco y negro, debemos recurrir a estéticas no muy efectivas (como tipo de línea) para identificar a cada grupo. Algo similar ocurre con los gráficos de dispersión: si no podemos asociar categorías con colores, deberemos conformarnos con usar diferentes formas para cada una.
2.4 Leyendas
Siempre que en nuestros gráficos tengamos estéticas asociadas a colores, formas, tamaños o tipos de línea, necesitamos incluir leyendas (o escalas) que aclaren cómo esa estética se relaciona con la variable que representa.
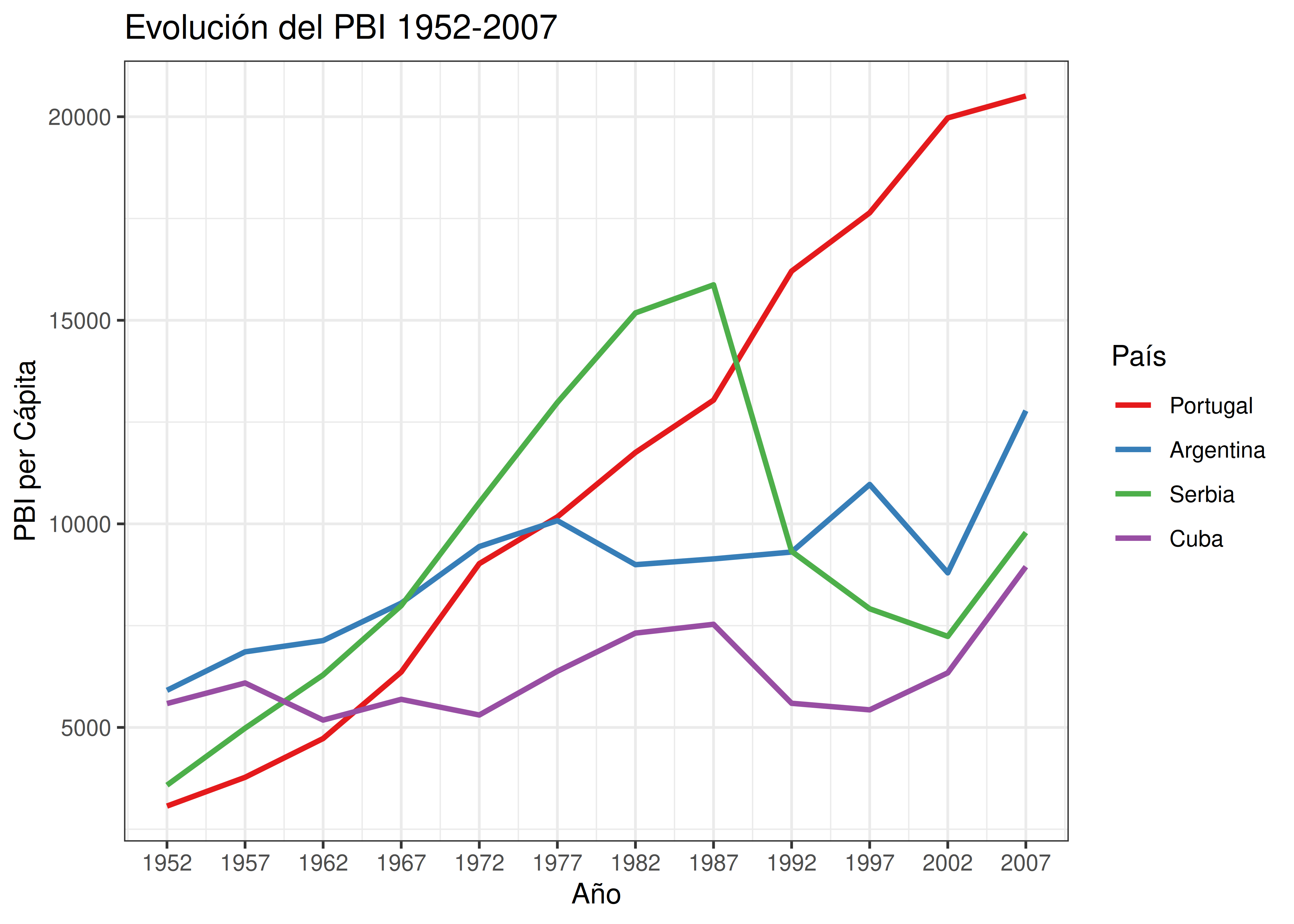
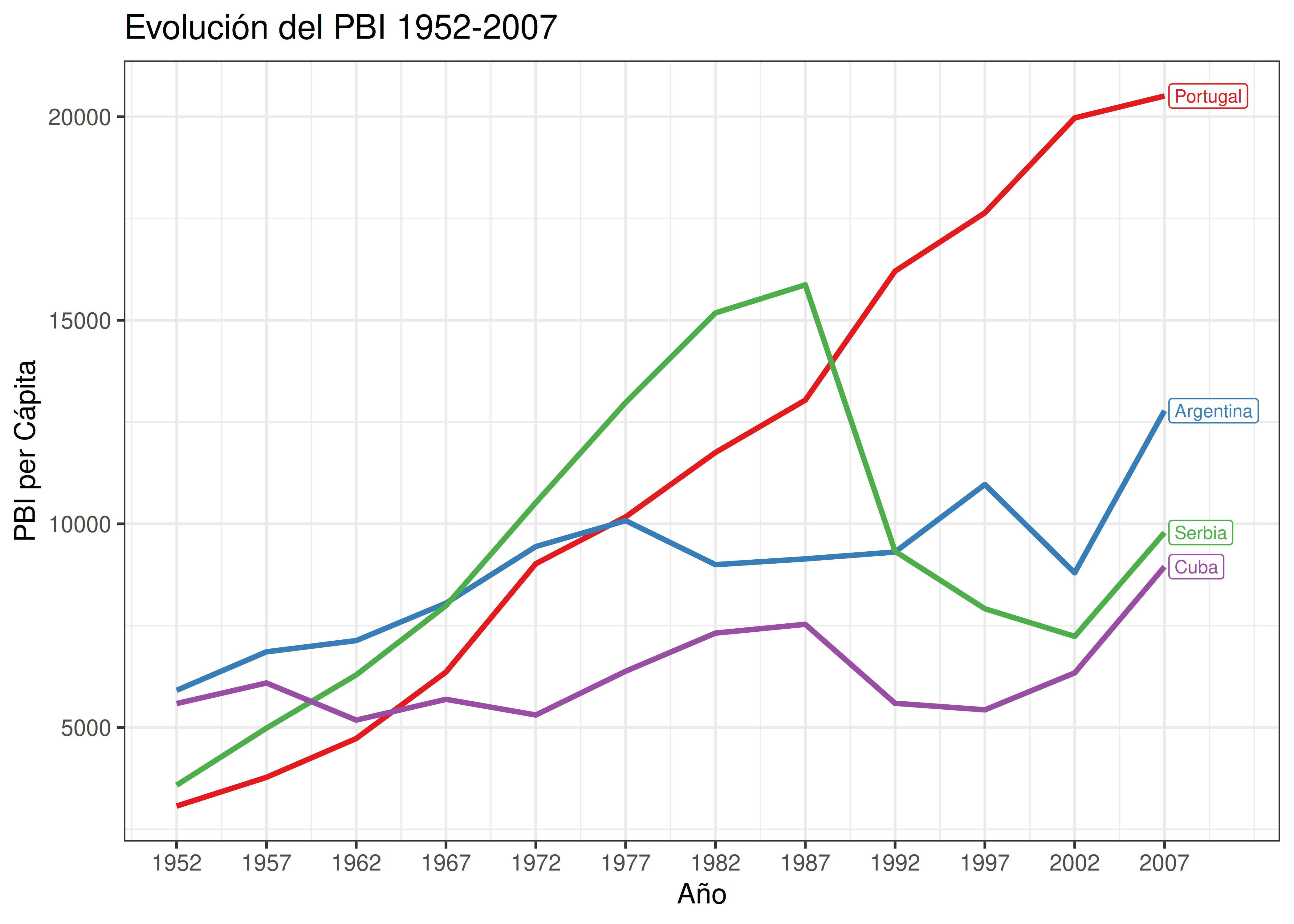
A continuación vemos un gráfico que muestra la evolución del PBI en 4 países diferentes. Los datos fueron extraídos del paquete
gapminder:

¿Están de acuerdo con el orden alfabético presente en la leyenda de arriba? ¿Podría mejorarse de alguna manera este gráfico, haciendo que sea más fácil de entender?
En casos donde hay un orden distinguible entre los valores representados, y la variable categórica asociada es nominal (sin orden intrínseco), se recomienda reordenar los niveles de la leyenda de manera que coincidan con el orden numérico. De esta manera, la relación que nuestro cerebro aplica para asociar colores con categorías es mucho más inmediata y natural:
- Por otro lado, las leyendas deben respetar el orden de las variables categóricas ordinales:
Muchas veces las leyendas pueden ser reemplazadas por textos o anotaciones que se ubican dentro del gráfico. Esto puede deberse a cuestiones de espacio (en general las leyendas ocupan mucho lugar y es necesario achicar el tamaño destinado al gráfico en sí mismo), de estética o bien para remarcar ciertas diferencias entre grupos de observaciones.
Ejemplo para la evolución del PBI:
2.5 Paneles
Cuando los conjuntos de datos que estamos analizando contienen un gran volumen de información, tratar de visualizar muchos aspectos en unos pocos gráficos puede ser contraproducente. En general, las visualizaciones resultantes están muy cargadas de información y son complejas de interpretar.
Para evitar este inconveniente podemos usar paneles que repliquen los gráficos construidos en distintos subgrupos de la población, o bien que estructuren de forma ordenada los análisis exploratorios llevados a cabo sobre cada variable.
2.5.1 Subgrupos
Sea cual sea el gráfico elegido para representar las variables de nuestro conjunto de datos, muchas veces resulta interesante ver cómo las relaciones entre estas variables dependen (o no) de diferentes subgrupos de la población que estamos estudiando.
Si la cantidad de subgrupos es moderadamente elevada, incluir todas las comparaciones en un solo lugar puede ser una mala idea. Los paneles nos ayudan a emprolijar y hacer más entendibles nuestros gráficos, replicando los análisis y ubicándolos en una grilla.
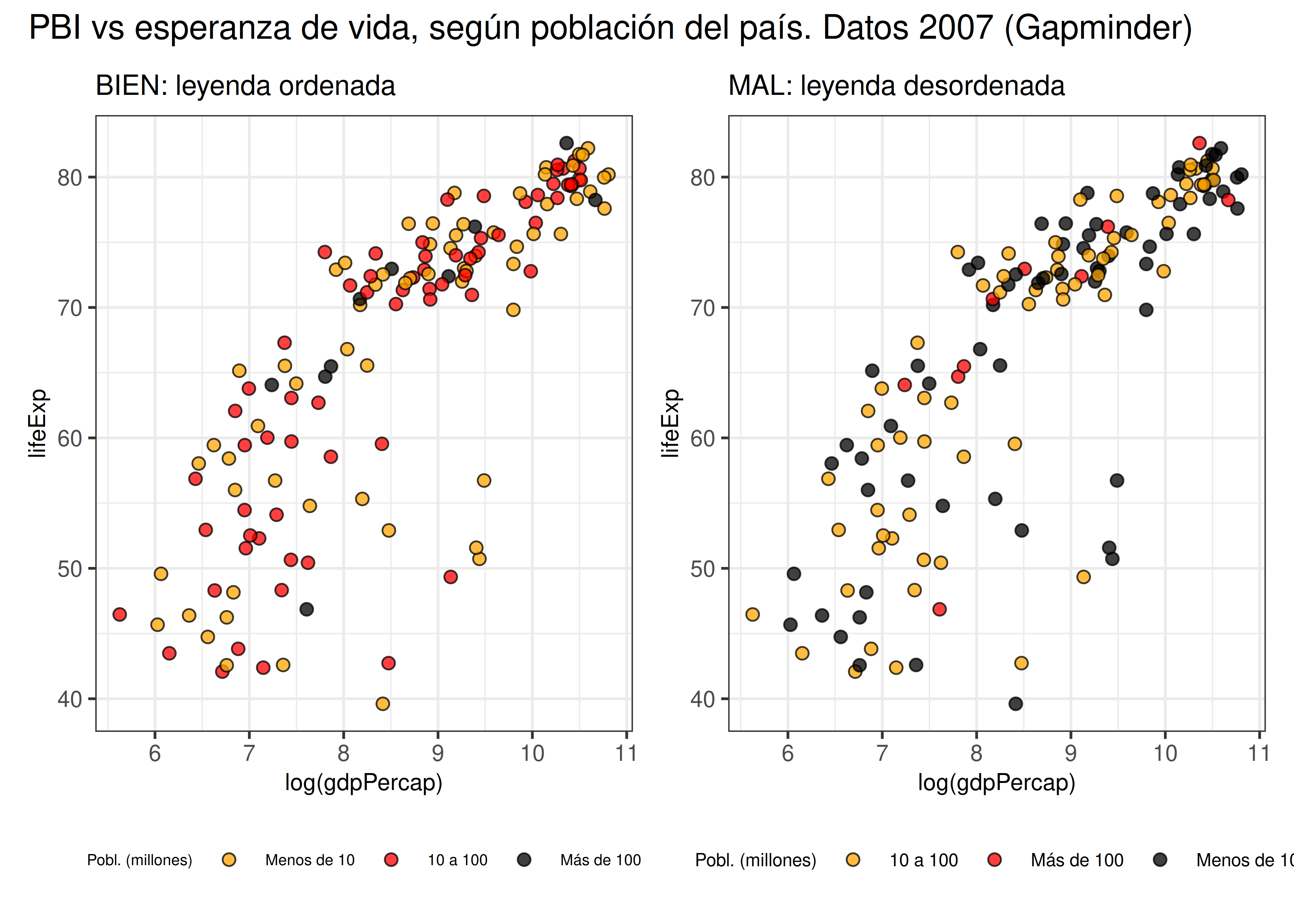
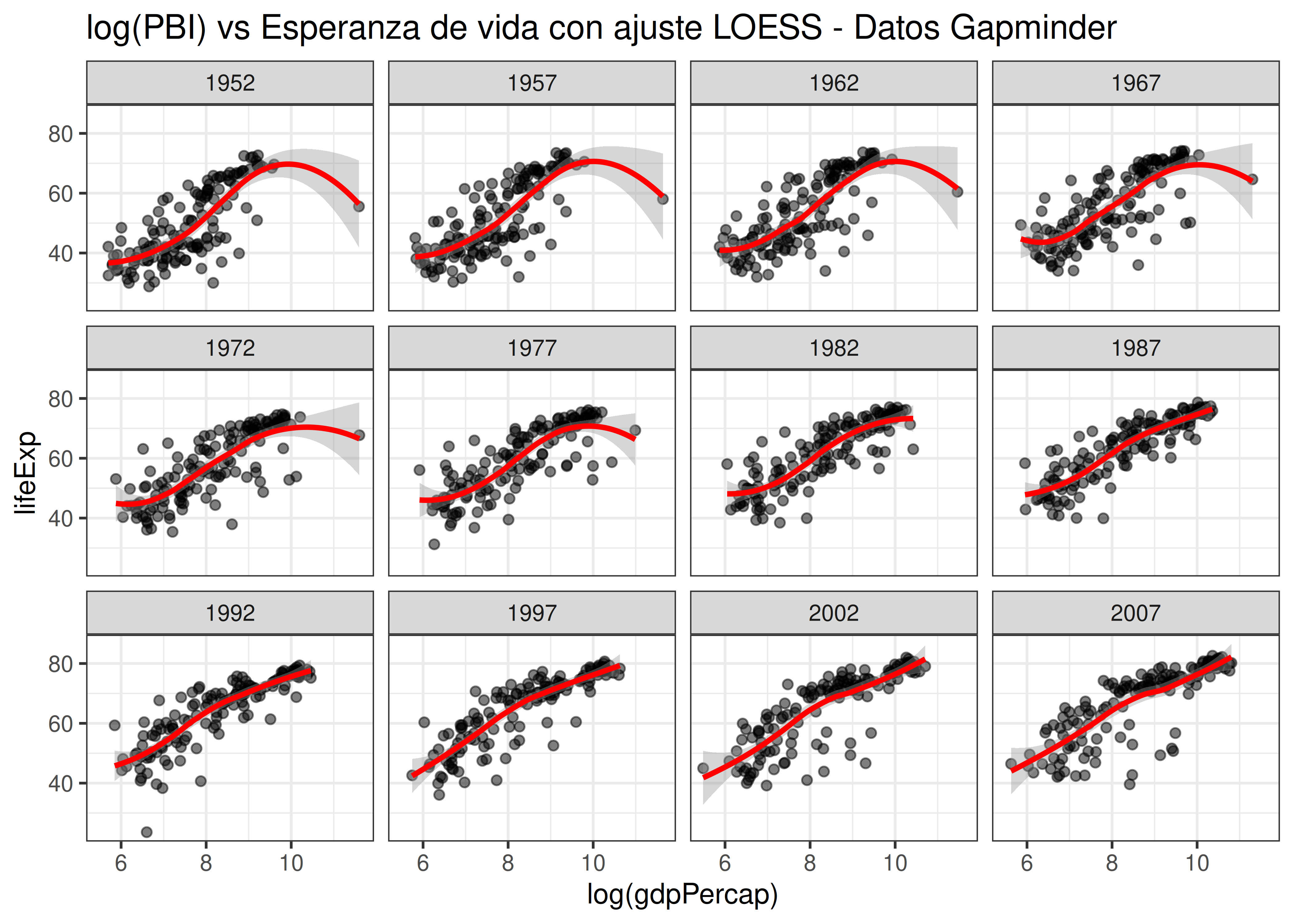
Veamos un ejemplo donde creamos diagramas de dispersión para las variables PBI per cápita y esperanza de vida de varios países, con un ajuste LOESS para cada año por separado. Este tipo de gráfico sería prácticamente imposible de armar en una figura que no use paneles (también llamados trellis plots o faceting en la literatura):
- Ejemplos comunes de faceting también se dan con histogramas, curvas de densidad, boxplots, gráficos de barra, etc. A continuación vemos boxplots de peso del recién nacido para subgrupos de la población conformados por el cruce entre 2 variables: tipo de parto (columnas) y semanas de gestación (filas):
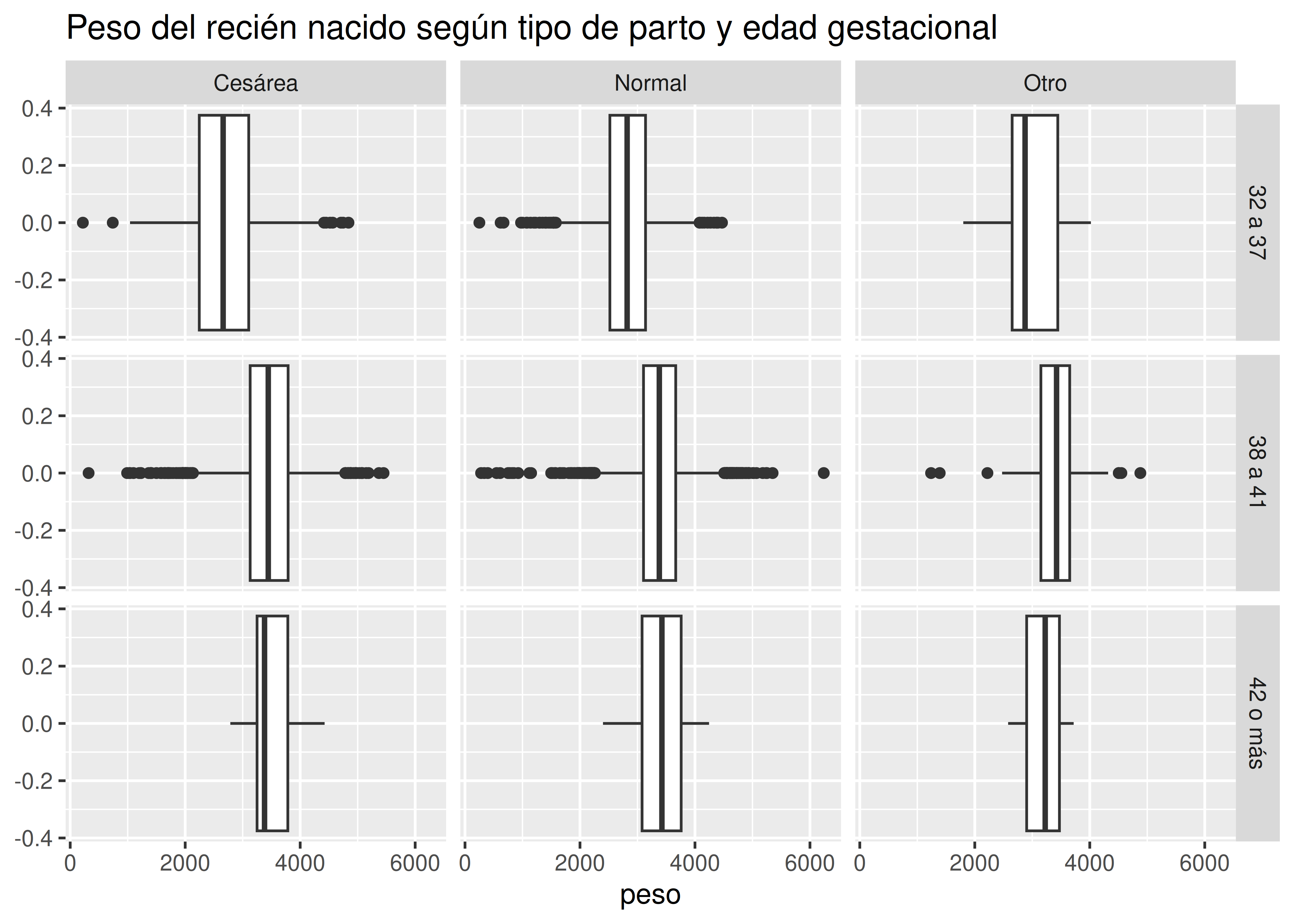
Si bien podríamos haber armado un único gráfico con 9 cajas, una por cada subgrupo, la ubicación espacial en una grilla como la de arriba facilita la interpretación de los resultados.
Lo importante en este tipo de visualizaciones es mantener constante las escalas de los ejes a lo largo de todos los paneles. Adaptar los límites a cada subgrupo en particular es totalmente engañoso, y debe ser evitado a toda costa.
También es importante que la ubicación de los gráficos en la grilla conserve un orden lógico. En el primer caso analizado, los años se suceden en orden ascendente de izquierda a derecha y de arriba hacia abajo. Si bien existen otras maneras de ordenarlos, estamos acostumbrados a que el panel de arriba a la izquierda sea el primero y el de abajo a la derecha, el último en nuestra recorrida visual. Lo mismo aplica para variables categóricas ordinales, como en el caso de la variable edad_gestacional del dataset de partos.
2.5.2 Paneles para múltiples visualizaciones
El otro uso de los paneles consiste en ver muchos gráficos distintos, independientes entre sí, en un solo lugar. En estos casos es vital que los colores, tamaños y apariencia general sean homogéneas, para que ningún panel en particular se robe la atención. Si asignamos ciertos colores a determinados subgrupos de la población, debemos mantener ese mapeo a lo largo de todos los gráficos presentados.
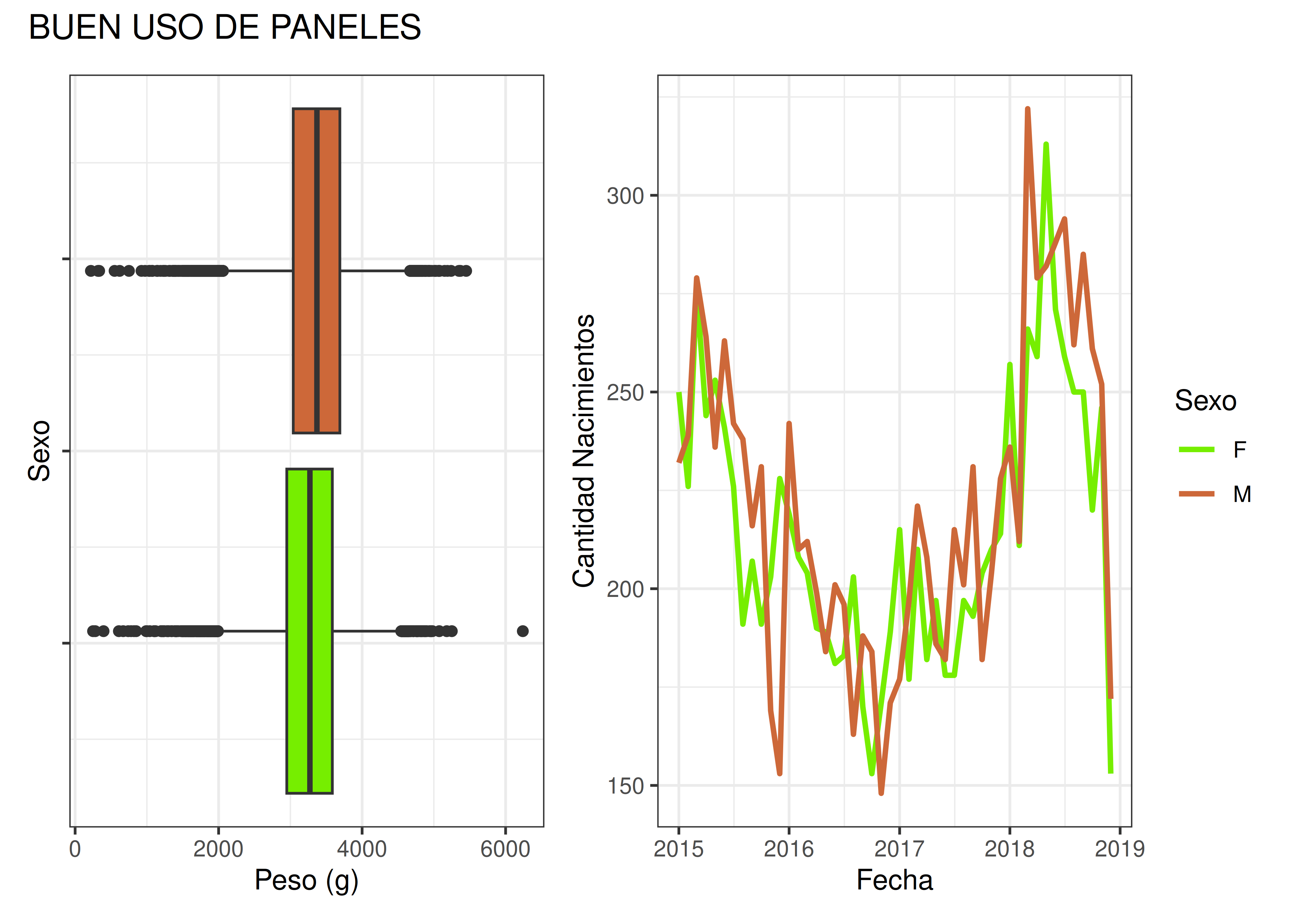
Ejemplo: boxplots para peso del recién nacido y evolución temporal de la cantidad de partos, según sexo del bebé:
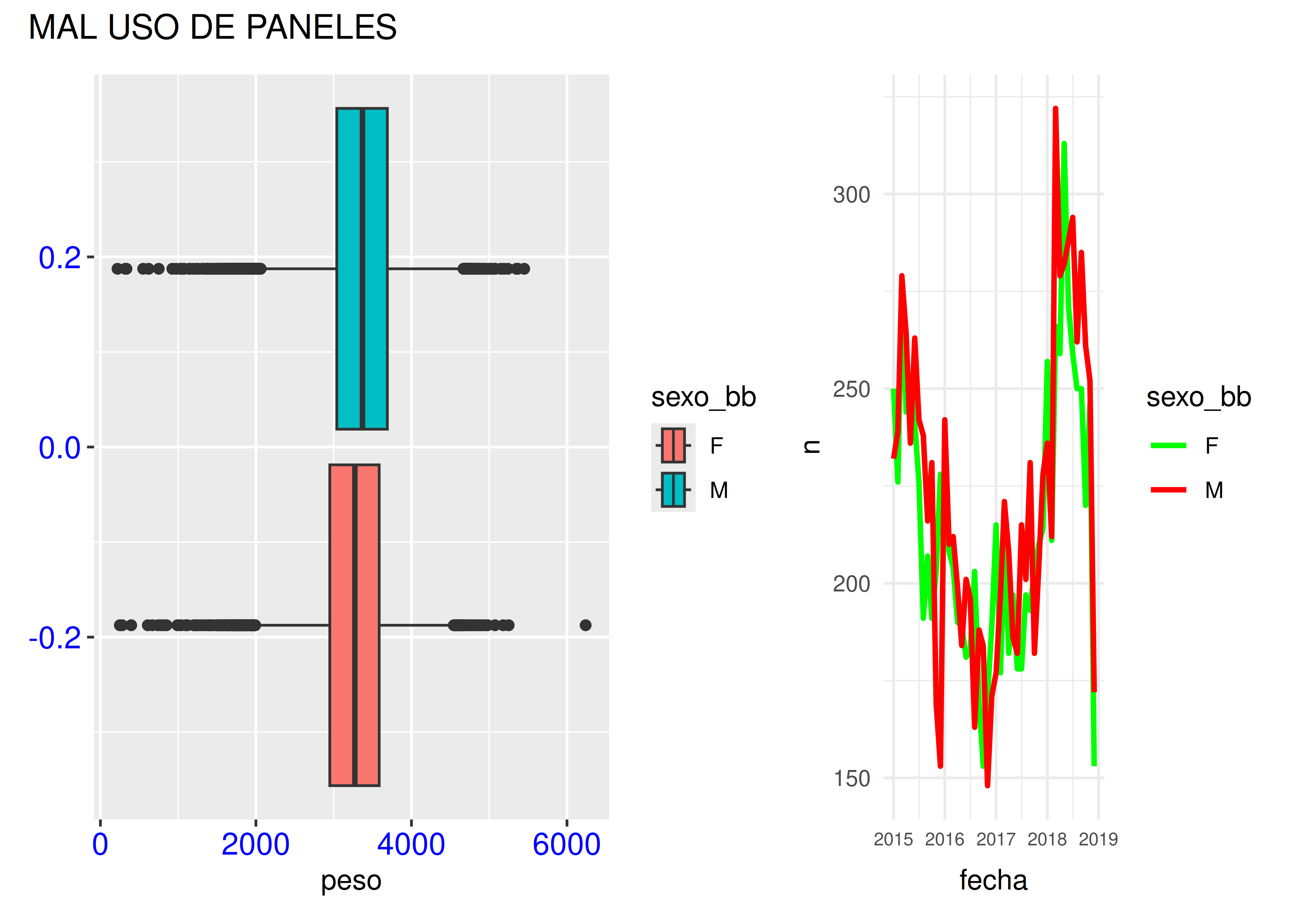
El gráfico de arriba tiene varios problemas: las estéticas no son compatibles (uno usa un fondo gris con marcas de eje azules, mientras que el otro posee un fondo blanco con letras negras); además, los colores asignados a cada nivel no se mantienen constantes y pueden llegar a confundir al público, los tamaños no son uniformes, etc.
Debajo vemos una versión mejorada:
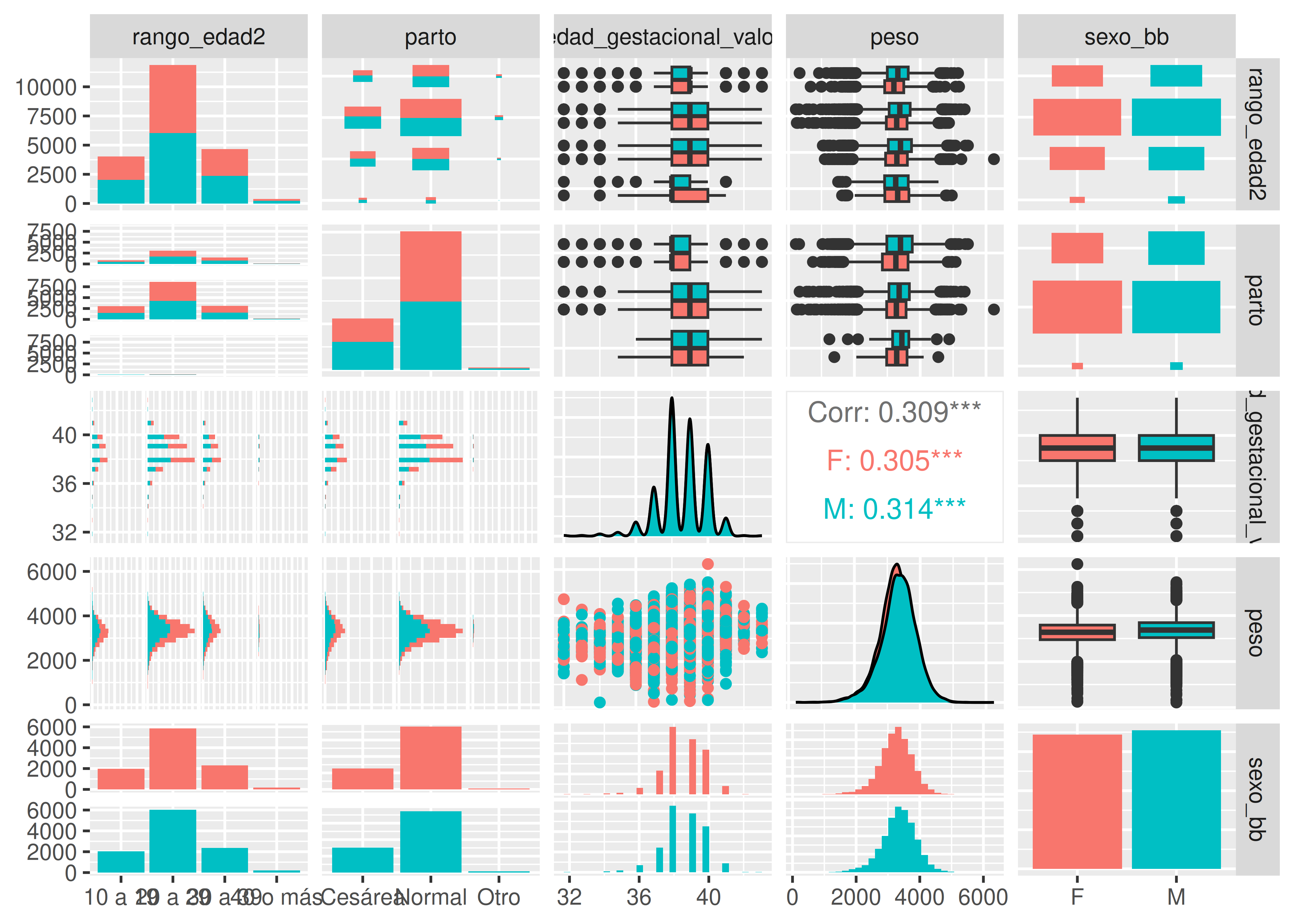
- Cuando la cantidad de información visualizada es abundante, resulta importante aclarar bien qué variable(s) estamos viendo en cada panel. En este sentido, el paquete
GGallyes de gran utilidad, a través de su funciónggpairs():
2.6 Grillas
Llamamos grillas a las rectas perpendiculares a los ejes que se dibujan en el fondo del gráfico para facilitar la interpretación del mismo, específicamente, a la hora de comparar valores entre diferentes observaciones o grupos representados.
Si bien constituyen un elemento muy importante de varios tipos de gráficos, muchas veces no son empleadas debidamente, o ni siquiera se las incluye. A continuación veremos algunos ejemplos de buenos y malos usos de grillas.
Retomando el ejemplo de evolución del PBI per cápita para ciertos países, veamos 4 maneras diferentes de aplicar grillas:
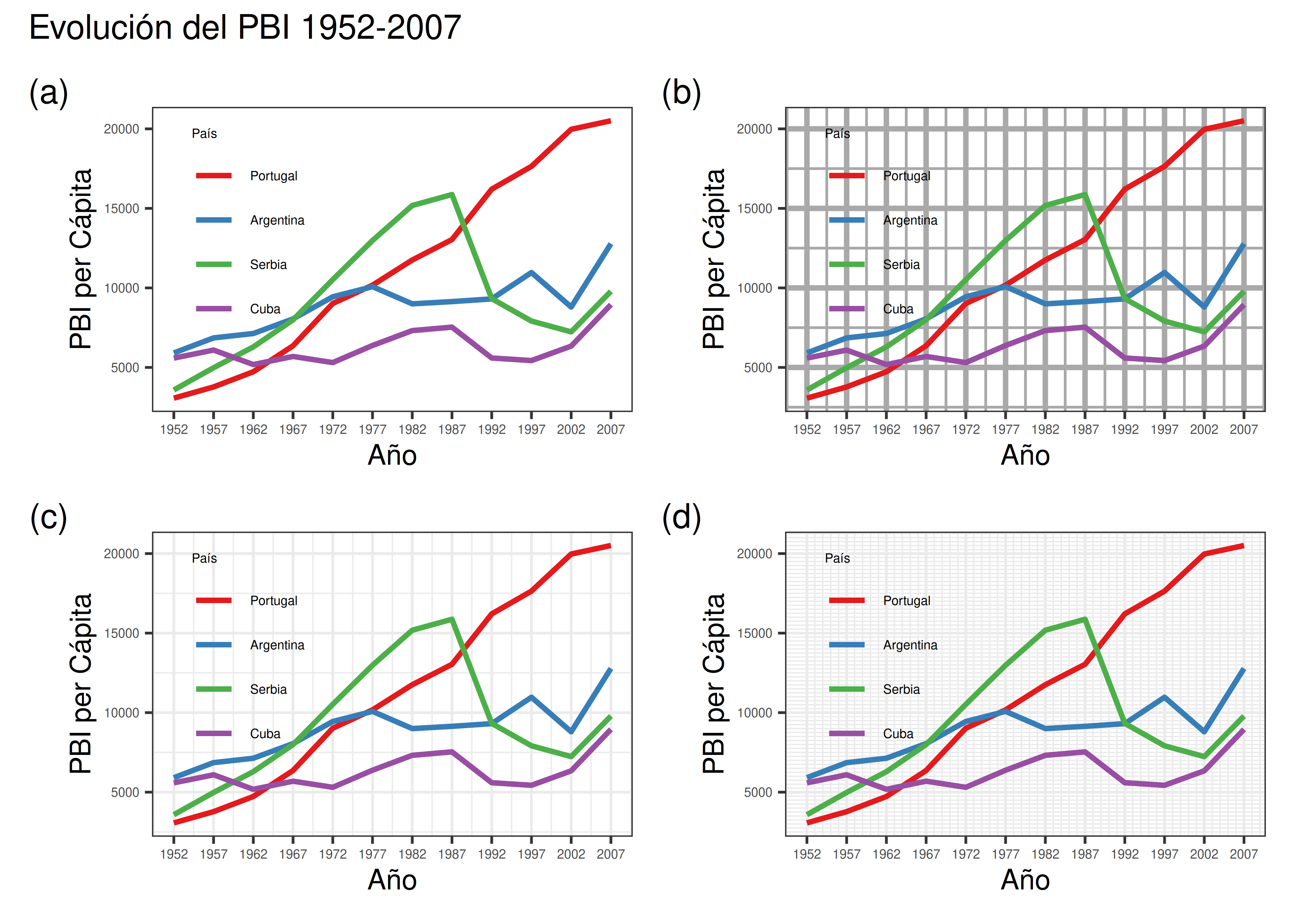
Analicemos este gráfico:
Panel (a): no se incluye grilla. Comparar valores se hace visualmente dificultoso. El gráfico en sí mismo no es “incorrecto”, pero se puede mejorar.
Panel (b): se incluye grilla, pero es demasiado llamativa y opaca los datos de interés. El grosor y la tonalidad de la grilla no deben competir con los usados para los elementos principales del gráfico.
Panel (c): esta es la opción preferida. Se incluye una grilla en tono gris claro que facilita la interpretación de los valores mostrados en el gráfico, sin crear una distracción como en el panel (b).
Panel (d): si bien los colores de la grilla son válidos, el problema en este caso es la cantidad innecesaria de líneas utilizadas. Usar una grilla demasiado densa también distrae y puede llegar a ocultar el mensaje principal del gráfico.
Un caso especial del uso de grillas se da cuando existe un valor “base” o “neutro” que sirve de punto de comparación para los valores representados en el gráfico.
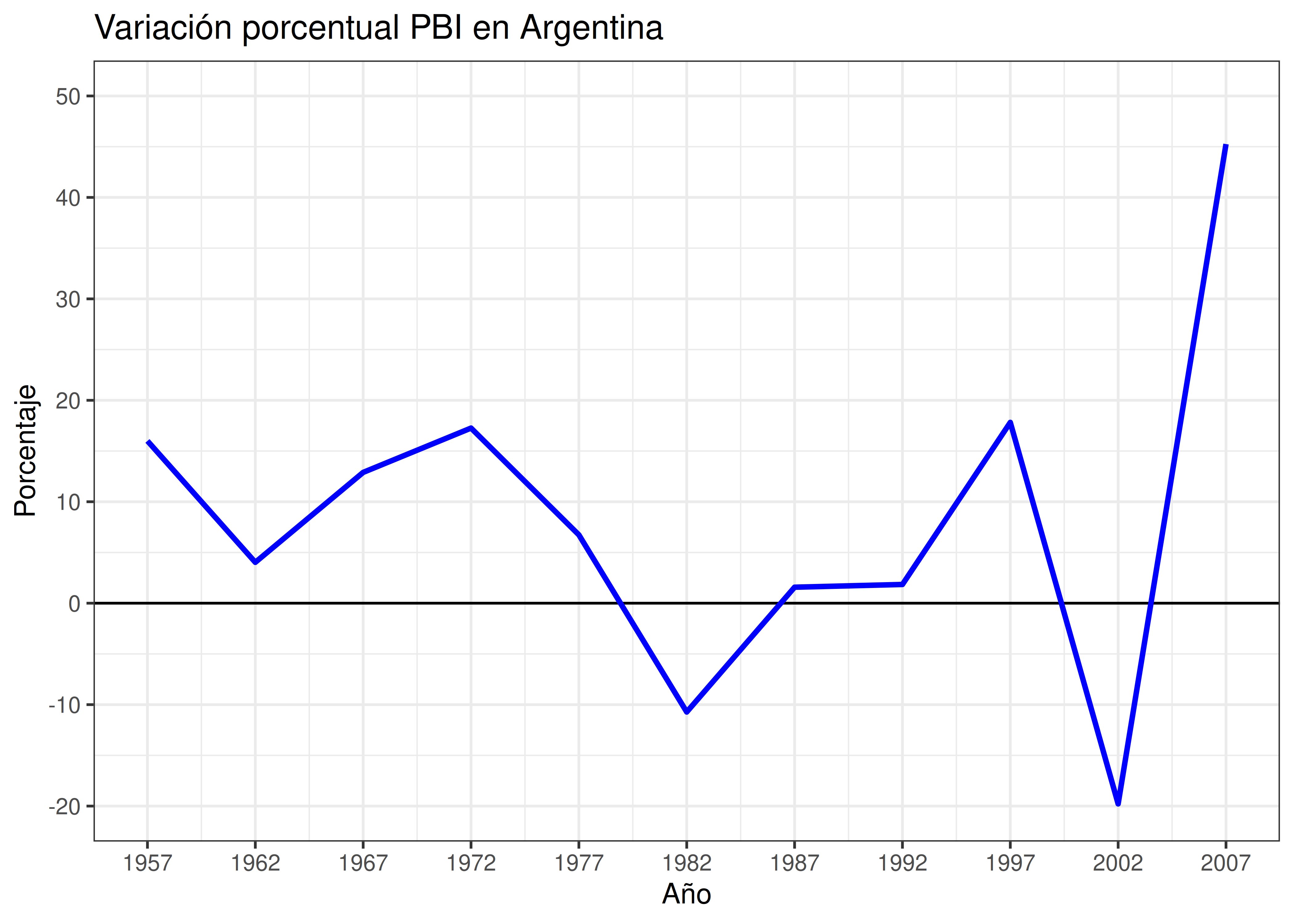
Por ejemplo, veamos el cambio porcentual en el PBI de Argentina para el período 1957-2007. Es natural tratar de ver si entre una medición y la siguiente, el PBI subió (variación mayor a 0) o bajó (menor a 0). Además de trazar la grilla original, se dibuja una línea recta horizontal que corta el eje Y a la altura del 0, reforzando su ubicación y permitiendo una interpretación más directa del gráfico.
- Algo similar hacemos cuando, en un diagrama de dispersión, se espera que ambas variables sean iguales: en vez de trazar una recta perpendicular a alguno de los ejes, dibujando la recta identidad que demarca la relación \(x=y\). Uno de los ejemplos más comunes de esto son los gráficos de cuantiles (q-q plots).
2.7 3D
Uno de los peores males que aquejan el mundo de la visualización de datos, junto con los gráficos de torta, son los gráficos 3D de datos originalmente 2D.
Excel es una herramienta que permite hacer este tipo de monstruosidad de manera relativamente sencilla, y su uso se ha extendido de tal manera que hoy en día es muy común ver gráficos 3D en contextos supuestamente serios (finanzas, academia, etc.).
Las críticas hacia el uso de efectos 3D son muchas y están bien fundamentadas. Veamos las principales:
- No aportan nada nuevo. Un gráfico de torta o barras 3D muestra exactamente la misma información que su versión original en 2D. Su uso es puramente “estético”.
- La mayoría de las veces engañan y confunden. El uso de estos efectos distorsiona las cantidades reales representadas en el gráfico, y el mensaje final depende del ángulo elegido para la visualización.
- Veamos cómo afecta el 3D a un gráfico de torta: a medida que rotamos el ángulo desde el cual vemos el gráfico, la porción más pequeña (25%) puede volverse artificialmente grande, enviando un mensaje contradictorio al espectador del gráfico.
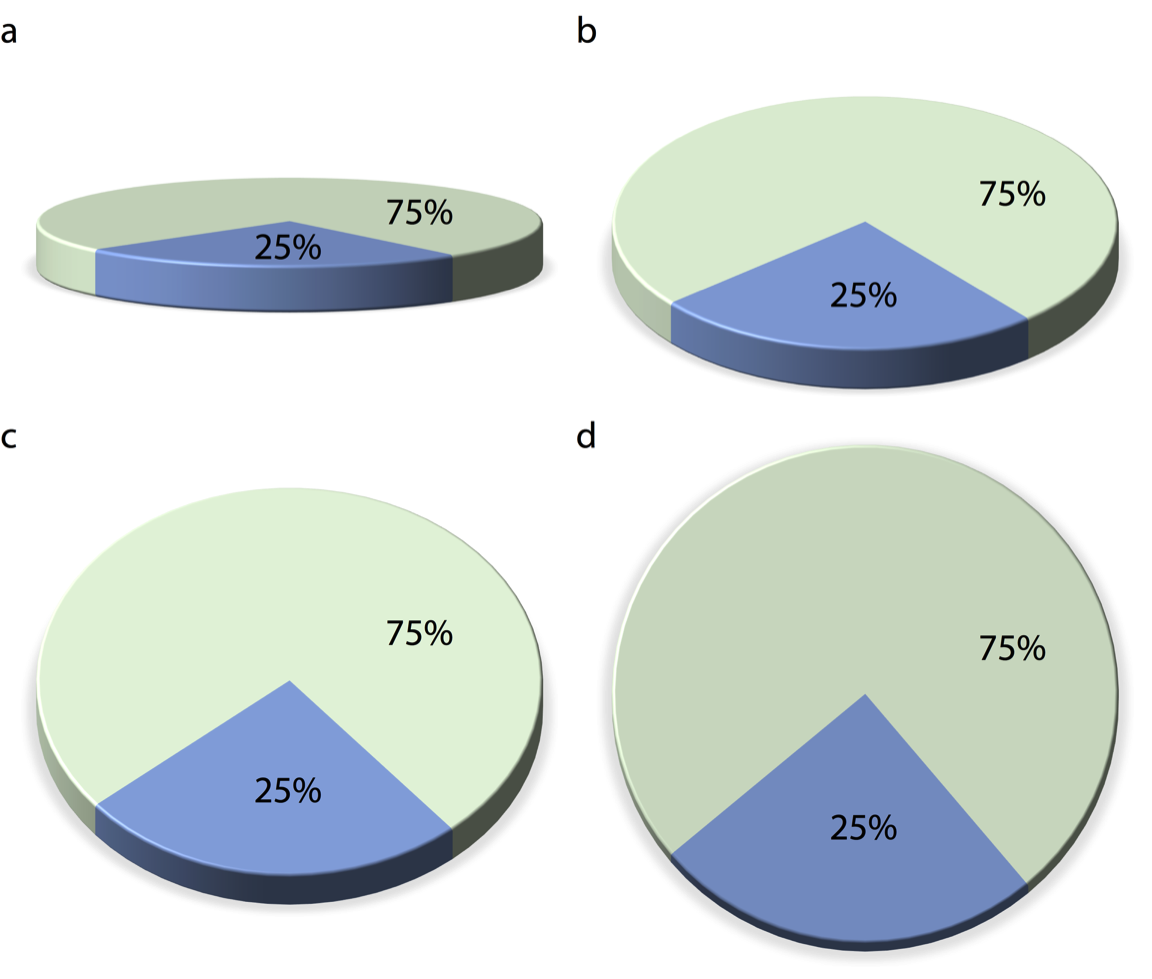
Sin embargo, lo peor está por venir: veamos ahora cómo impacta el efecto 3D sobre un gráfico de barras.
La siguiente figura fue construida usando Excel. Los datos originales representan tres grupos con los siguientes valores: 10, 5 y 12 (panel de la izquierda). La versión por defecto que ofrece Excel cuando se elige un gráfico 3D para esos mismos datos se muestra en el panel derecho.
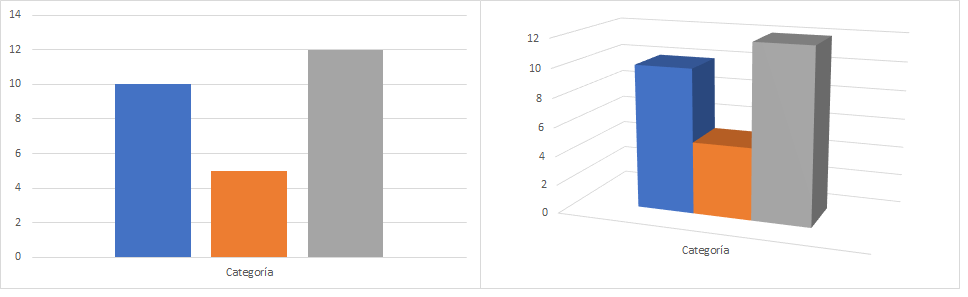
¿Por qué la altura de cada barra no coincide con su valor correspondiente? ¿Por qué el software más popular para almacenamiento de datos construye por defecto gráficos literalmente erróneos? ¿Por qué? No hay por qué.
No vamos a perder más tiempo de clase mirando figuras con efetos 3D innecesarios. Consideramos que estos dos ejemplos deberían ser suficientes para desmotivar a cualquier persona que esté considerando el uso de este tipo de gráficos.
2.8 Comentarios finales
- Existen muchísimos otros detalles de un gráfico que pueden salir mal, pero dedicarle a cada uno su propia sección nos llevaría demasiado tiempo. A continuación vamos a mencionar 2 de los más importantes:
2.8.1 Contexto
Todo gráfico debe estar bien contextualizado. Esto implica que debemos asegurarnos de incluir un título general, títulos de los ejes y leyendas, escalas utilizadas, unidades de medida de las variables representadas, etc. De ser necesario, también debemos indicar el período temporal analizado, las fuentes de información, y cualquier otro detalle importante que ayude a contextualizar mejor el mensaje que queremos transmitir.
Este último consejo se vuelve mucho más importante cuando la figura se publica de manera independiente o solitaria: no es lo mismo contextualizar un gráfico incluido en el anexo de una tesis, donde las características de los datos ya han sido descritas detalladamente, que hacerlo cuando el medio de comunicación empleado es alguna red social.
2.8.2 Tamaño
Cuando creamos una visualización debemos cuidar que el tamaño de los textos, puntos, barras o formas utilizadas sean legibles y también uniformes. Puede ser confuso (y hasta molesto) analizar un gráfico donde la etiqueta del eje X está escrita en un tamaño de fuente mayor que el título principal, o bien cuando diferentes ejes poseen diferentes tamaños de texto.
Con respecto al tamaño elegido, debemos pensar en qué lugar o por qué medio se publicarán los gráficos que estamos construyendo: ¿el público accederá a estos gráficos a través de un medio digital (PC, celular, etc.) en el cual es posible hacer zoom, o el resultado final se verá impreso en papel?
Si el gráfico es estático, es muy importante chequear que el tamaño de letra empleado se traslade bien al papel o documento de salida; caso contrario el gráfico será ininteligible y el mensaje se pierde. Con respecto a esto, debemos tener en cuenta que el tamaño de las letras de un gráfico como se ven en RStudio no necesariamente va a coincidir con el tamaño de las letras luego de la exportación de la imagen.